Out line Markov Decision P rocesses Dynamic Decision Net works - PDF document
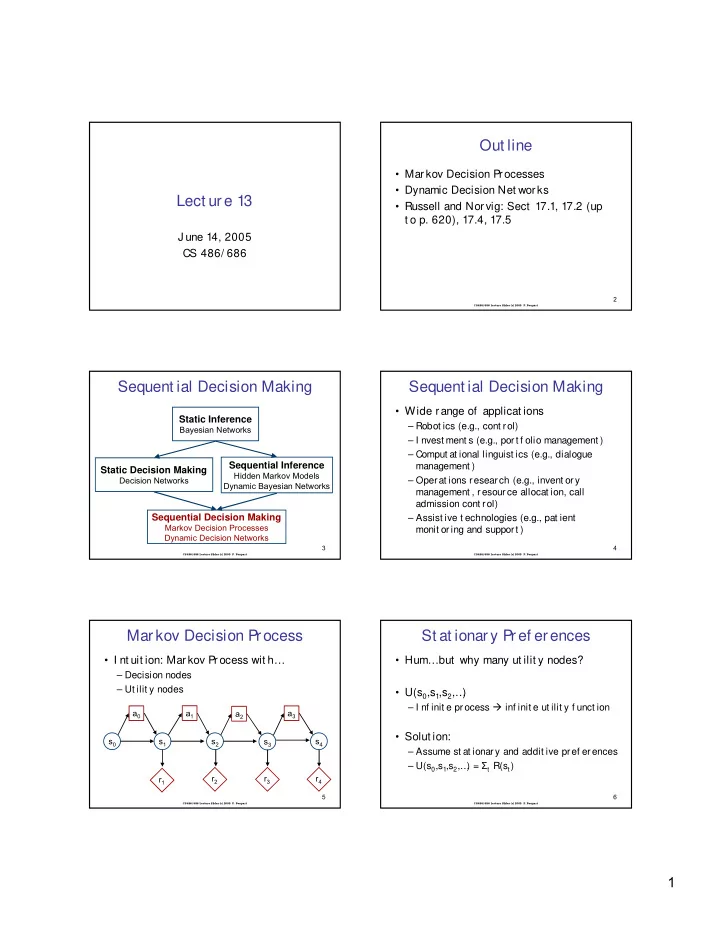
Out line Markov Decision P rocesses Dynamic Decision Net works Lect ure 13 Russell and Nor vig: Sect 17.1, 17.2 (up t o p. 620), 17.4, 17.5 J une 14, 2005 CS 486/ 686 2 CS486/686 Lecture Slides (c) 2005 P. Poupart Sequent
Out line • Markov Decision P rocesses • Dynamic Decision Net works Lect ure 13 • Russell and Nor vig: Sect 17.1, 17.2 (up t o p. 620), 17.4, 17.5 J une 14, 2005 CS 486/ 686 2 CS486/686 Lecture Slides (c) 2005 P. Poupart Sequent ial Decision Making Sequent ial Decision Making • Wide range of applicat ions Static Inference – Robot ics (e.g., cont rol) Bayesian Networks – I nvest ment s (e.g., port f olio management ) – Comput at ional linguist ics (e.g., dialogue Sequential Inference management ) Static Decision Making Hidden Markov Models Decision Networks – Operat ions research (e.g., invent ory Dynamic Bayesian Networks management , resour ce allocat ion, call admission cont rol) Sequential Decision Making – Assist ive t echnologies (e.g., pat ient Markov Decision Processes monit or ing and support ) Dynamic Decision Networks 3 4 CS486/686 Lecture Slides (c) 2005 P. Poupart CS486/686 Lecture Slides (c) 2005 P. Poupart Markov Decision Process St at ionary Pref erences • I nt uit ion: Mar kov Process wit h… • Hum…but why many ut ilit y nodes? – Decision nodes – Ut ilit y nodes • U(s 0 ,s 1 ,s 2 ,… ) – I nf init e pr ocess � inf init e ut ilit y f unct ion a 0 a 1 a 2 a 3 • Solut ion: s 0 s 1 s 2 s 3 s 4 – Assume st at ionary and addit ive pref erences ) = Σ t R(s t ) – U(s 0 ,s 1 ,s 2 ,… r 2 r 3 r 4 r 1 5 6 CS486/686 Lecture Slides (c) 2005 P. Poupart CS486/686 Lecture Slides (c) 2005 P. Poupart 1
Discount ed/ Average Rewards Markov Decision Process • I f process inf init e, isn’t Σ t R(s t ) inf init e? • Def init ion – Set of st at es: S • Solut ion 1: discount ed rewards – Set of act ions (i.e., decisions): A – Discount f act or: 0 ≤ γ ≤ 1 – Transit ion model: Pr(s t | a t -1 ,s t -1 ) – Finit e ut ilit y: Σ t γ t R(s t ) is a geomet ric sum – γ is like an inf lat ion rat e of 1/ γ - 1 – Reward model (i.e., ut ilit y): R(s t ) – Discount f act or: 0 ≤ γ ≤ 1 – I nt uit ion: pref er ut ilit y sooner t han lat er – Horizon (i.e., # of t ime st eps): h • Solut ion 2: aver age rewards – More complicat ed comput at ionally • Goal: f ind opt imal policy – Beyond t he scope of t his course 7 8 CS486/686 Lecture Slides (c) 2005 P. Poupart CS486/686 Lecture Slides (c) 2005 P. Poupart I nvent ory Management Policy • Markov Decision Pr ocess • Choice of act ion at each t ime st ep – St at es: invent ory levels – Act ions: {doNot hing, orderWidget s} • For mally: – Transit ion model: st ochast ic demand – Mapping f rom st at es t o act ions – Reward model: Sales – Cost s - St orage – i.e., δ (s t ) = a t – Discount f act or: 0.999 – Horizon: ∞ – Assumpt ion: f ully observable st at es • Allows a t t o be chosen only based on current • Tradeof f : increasing supplies decreases odds st at e s t . Why? of missed sales but increases st orage cost s 9 10 CS486/686 Lecture Slides (c) 2005 P. Poupart CS486/686 Lecture Slides (c) 2005 P. Poupart Policy Opt imizat ion Policy Opt imizat ion • Policy evaluat ion: • Three algorit hms t o opt imize policy: – Comput e expect ed ut ilit y – Value it erat ion h – EU( δ ) = Σ t =0 γ t Pr(s t | δ ) R(s t ) – Policy it erat ion – Linear Progr amming • Opt imal policy: • Value it er at ion: – Policy wit h highest expect ed ut ilit y – EU( δ ) ≤ EU( δ *) f or all δ – Equivalent t o variable eliminat ion 11 12 CS486/686 Lecture Slides (c) 2005 P. Poupart CS486/686 Lecture Slides (c) 2005 P. Poupart 2
Value I t erat ion Value I t erat ion • Not hing more t han variable eliminat ion • At each t , st art ing f rom t =h down t o 0: • Perf orms dynamic programming – Opt imize a t : EU(a t | s t )? – Fact ors: Pr(s t +1 | a t ,s t ), R(s t ), f or • Opt imize decisions in rever se order – Rest rict s t – Eliminat e s t +1 ,… ,s h ,a t +1 ,… ,a h a 3 a 3 a 2 a 2 a 0 a 1 a 0 a 1 s 0 s 1 s 2 s 3 s 4 s 0 s 1 s 2 s 3 s 4 r 2 r 3 r 4 r 2 r 3 r 4 r 1 r 1 13 14 CS486/686 Lecture Slides (c) 2005 P. Poupart CS486/686 Lecture Slides (c) 2005 P. Poupart Value I t erat ion A Markov Decision Process • Value when no t ime lef t : 1 γ = 0.9 – V(s h ) = R(s h ) S • Value wit h one t ime st ep lef t : ½ ½ 1 Poor & You own a Poor & – V(s h-1 ) = max a h-1 R(s h-1 ) + γ Σ s h Pr(s h |s h-1 ,a h-1 ) V(s h ) A Unknown company Famous A +0 +0 • Value wit h t wo t ime st eps lef t : I n ever y st at e you must S – V(s h-2 ) = max a h-2 R(s h-2 ) + γ Σ s h-1 Pr(s h-1 |s h-2 ,a h-2 ) V(s h-1 ) choose bet ween ½ S aving money or ½ 1 • … ½ ½ ½ A dver t ising • Bellman’s equat ion: S A A Rich & Rich & – V(s t ) = max a t R(s t ) + γ Σ s t +1 Pr(s t +1 |s t ,a t ) V(s t +1 ) S Famous Unknown – a t * = argmax a t R(s t ) + γ Σ s t +1 Pr(s t +1 |s t ,a t ) V(s t +1 ) ½ +10 +10 ½ ½ 15 16 CS486/686 Lecture Slides (c) 2005 P. Poupart CS486/686 Lecture Slides (c) 2005 P. Poupart 1 γ = 0.9 Finit e Horizon S ½ 1 PU ½ PF A A +0 +0 1 S ½ ½ ½ ½ ½ S A A • When h is f init e, RF RU S +10 +10 • Non-st at ionar y opt imal policy ½ ½ ½ • Best act ion dif f erent at each t ime st ep • I nt uit ion: best act ion varies wit h t he amount t V(PU) V(PF) V(RU) V(RF) of t ime lef t h 0 0 10 10 h-1 0 4.5 14.5 19 h-2 2.03 8.55 16.53 25.08 h-3 4.76 12.20 18.35 28.72 h-4 7.63 15.07 20.40 31.18 h-5 10.21 17.46 22.61 33.21 17 18 CS486/686 Lecture Slides (c) 2005 P. Poupart CS486/686 Lecture Slides (c) 2005 P. Poupart 3
I nf init e Horizon I nf init e Horizon • Assuming a discount f act or γ , af t er k t ime • When h is inf init e, st eps, rewards are scaled down by γ k • St at ionary opt imal policy • For large enough k, rewards become • Same best act ion at each t ime st ep insignif icant since γ k � 0 • I nt uit ion: same (inf init e) amount of t ime lef t • Solut ion: at each t ime st ep, hence same best act ion – pick large enough k – run value it erat ion f or k st eps • Problem: value it erat ion does an inf init e – Execut e policy f ound at t he k t h it erat ion number of it er at ions… 19 20 CS486/686 Lecture Slides (c) 2005 P. Poupart CS486/686 Lecture Slides (c) 2005 P. Poupart Comput at ional Complexit y Dynamic Decision Net work • Space and t ime: O(k| A| | S| 2 ) ☺ Act t- 2 Act t- 1 Act t – Here k is t he number of it erat ions M t- 2 M t- 1 M t M t+1 • But what if | A| and | S| are def ined by several random variables and T t- 2 T t- 1 T t T t+1 consequent ly exponent ial? L t- 2 L t- 1 L t L t+1 • Solut ion: exploit condit ional C C C C t- 2 t- 1 t t+1 independence N t- 2 N t- 1 N t N t+1 – Dynamic decision net work R t R t- 2 R t- 1 R t+1 21 22 CS486/686 Lecture Slides (c) 2005 P. Poupart CS486/686 Lecture Slides (c) 2005 P. Poupart Dynamic Decision Net work Part ial Observabilit y • What if st at es are not f ully obser vable? • Similarly t o dynamic Bayes net s: • Solut ion: Par t ially Obser vable Mar kov Decision Process – Compact represent at ion ☺ – Exponent ial t ime f or decision making � o 2 o 3 o o o 1 a 3 a 2 a 0 a 1 s 0 s 1 s 2 s 4 s 3 r 2 r 3 r 4 r 1 23 24 CS486/686 Lecture Slides (c) 2005 P. Poupart CS486/686 Lecture Slides (c) 2005 P. Poupart 4
Par t ially Observable Markov POMDP Decision Pr ocess (POMDP) • Def init ion • Pr oblem: act ion choice gener ally depends – Set of st at es: S on all previous observat ions… – Set of act ions (i.e., decisions): A – Set of observat ions: O • Two solut ions: – Transit ion model: Pr(s t |a t -1 ,s t -1 ) – Consider only policies t hat depend on a – Observat ion model: Pr(o t |s t ) f init e hist or y of observat ions – Reward model (i.e., ut ilit y): R(s t ) – Discount f act or: 0 ≤ γ ≤ 1 – Find st at ionary suf f icient st at ist ics – Horizon (i.e., # of t ime st eps): h encoding relevant past observat ions • Policy: mapping f r om past obs. t o act ions 25 26 CS486/686 Lecture Slides (c) 2005 P. Poupart CS486/686 Lecture Slides (c) 2005 P. Poupart Part ially Observable DDN Policy Opt imizat ion • Act ions do not depend on all st at e variables • Policy opt imizat ion: – Value it erat ion (variable eliminat ion) Act t- 2 Act t- 1 Act t – Policy it erat ion M t- 2 M t- 1 M t M t+1 • POMDP and PODDN complexit y: T t- 2 T t- 1 T t T t+1 – Exponent ial in | O| and k when act ion choice L t- 2 L t- 1 L t L t+1 depends on all previous observat ions � C C C C t- 2 t- 1 t t+1 – I n pract ice, good policies based on subset of past observat ions can st ill be f ound N t- 2 N t- 1 N t N t+1 R t R t- 2 R t- 1 R t+1 27 28 CS486/686 Lecture Slides (c) 2005 P. Poupart CS486/686 Lecture Slides (c) 2005 P. Poupart COACH project COACH project Aging Population • Automated prompting system to help elderly persons wash their hands • Dementia • IATSL: Alex Mihailidis, Pascal Poupart, Jennifer Boger, – Deterioration of intellectual faculties Jesse Hoey, Geoff Fernie and Craig Boutilier – Confusion – Memory losses (e.g., Alzheimer’s disease) • Consequences: – Loss of autonomy – Continual and expensive care required 29 30 CS486/686 Lecture Slides (c) 2005 P. Poupart CS486/686 Lecture Slides (c) 2005 P. Poupart 5
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.