NAS FT Variants Performance Summary Best MFlop rates for all NAS FT - PowerPoint PPT Presentation
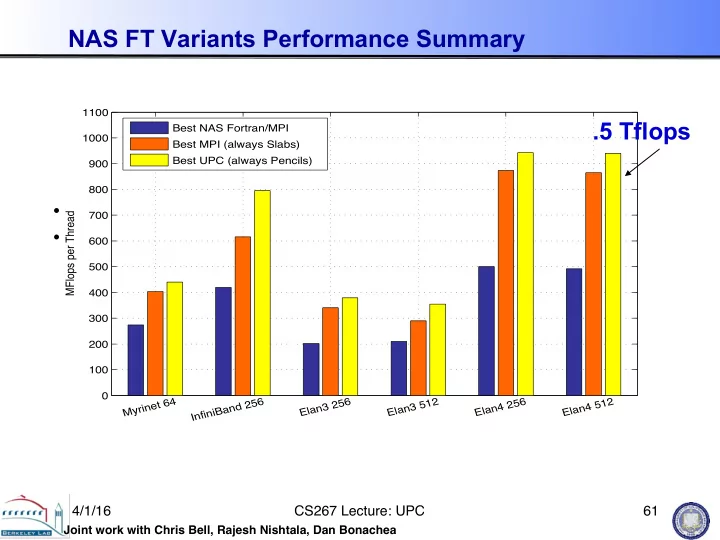
NAS FT Variants Performance Summary Best MFlop rates for all NAS FT Benchmark versions 1100 .5 Tflops Best NAS Fortran/MPI 1000 Best NAS Fortran/MPI Best MPI (always Slabs) 1000 Best MPI Best UPC (always Pencils) 900 Best UPC 800 800
NAS FT Variants Performance Summary Best MFlop rates for all NAS FT Benchmark versions 1100 .5 Tflops Best NAS Fortran/MPI 1000 Best NAS Fortran/MPI Best MPI (always Slabs) 1000 Best MPI Best UPC (always Pencils) 900 Best UPC 800 800 • Slab is always best for MPI; small message cost too high MFlops per Thread MFlops per Thread 700 • Pencil is always best for UPC; more overlap 600 600 500 400 400 300 200 200 100 0 Myrinet 64 InfiniBand 256 Elan3 256 Elan3 512 Elan4 256 Elan4 512 0 Myrinet 64 InfiniBand 256 Elan3 256 Elan3 512 Elan4 256 Elan4 512 4/1/16 � CS267 Lecture: UPC � 61 � Joint work with Chris Bell, Rajesh Nishtala, Dan Bonachea �
FFT Performance on BlueGene/P PGAS implementations HPC Challenge Peak as of July 09 is • consistently outperform MPI ~4.5 Tflops on 128k Cores Leveraging communication/ • 3500 computation overlap yields best performance Slabs 3000 Slabs (Collective) More collectives in flight • Packed Slabs (Collective) and more communication 2500 MPI Packed Slabs leads to better performance GFlops 2000 At 32k cores, overlap • algorithms yield 17% 1500 improvement in overall G 1000 application time O Numbers are getting close to • O 500 HPC record D Future work to try to beat • 0 the record 256 512 1024 2048 4096 8192 16384 32768 Num. of Cores 62
Case Study: LU Factorization • Direct methods have complicated dependencies - Especially with pivoting (unpredictable communication) - Especially for sparse matrices (dependence graph with holes) • LU Factorization in UPC - Use overlap ideas and multithreading to mask latency - Multithreaded: UPC threads + user threads + threaded BLAS • Panel factorization: Including pivoting • Update to a block of U • Trailing submatrix updates • Status: - Dense LU done: HPL-compliant - Sparse version underway 4/1/16 � CS267 Lecture: UPC � 63 � Joint work with Parry Husbands �
UPC HPL Performance X1 Linpack Performance Opteron Cluster Altix Linpack Linpack Performance • MPI HPL numbers Performance 1400 from HPCC MPI/HPL 160 1200 UPC database 140 200 1000 120 • Large scaling: 100 800 150 GFlop/s • 2.2 TFlops on 512p, GFlop/s GFlop/s 80 600 • 4.4 TFlops on 1024p 100 MPI/HPL 60 MPI/HPL 400 (Thunder) UPC 40 UPC 50 200 20 0 0 0 Alt/32 60 X1/64 X1/128 Opt/64 • Comparison to ScaLAPACK on an Altix, a 2 x 4 process grid - ScaLAPACK (block size 64) 25.25 GFlop/s (tried several block sizes) - UPC LU (block size 256) - 33.60 GFlop/s, (block size 64) - 26.47 GFlop/s • n = 32000 on a 4x4 process grid - ScaLAPACK - 43.34 GFlop/s (block size = 64) - UPC - 70.26 Gflop/s (block size = 200) 4/1/16 � CS267 Lecture: UPC � 64 � Joint work with Parry Husbands �
Recommend
























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.