
Lawrence Berkeley National Laboratory WPSE 2009 Unified Parallel - PDF document
Costin Iancu Lawrence Berkeley National Laboratory WPSE 2009 Unified Parallel C SPMD programming model, shared memory space abstraction Communication is either implicit or explicit one-sided Memory model:
Costin Iancu Lawrence Berkeley National Laboratory WPSE 2009 • � Unified Parallel C – � SPMD programming model, shared memory space abstraction – � Communication is either implicit or explicit – one-sided – � Memory model: relaxed and strict UPC Code Compiler • � Ubiquitous UPC implementation Compiler-generated C code – � Compiler based on the Open64 framework UPC Runtime system UPC Runtime system – � Source to source translation – � GASNet communication libraries GASNet Communication System - � PUT/GET primitives Network Hardware - � Vector/Index/Strided (VIS) primitives - � Synchronization, collective operations • � Provide integration across all levels of the software stack • � Mechanisms for finer grained control over system resources • � Application level resource usage policies • � Language and compiler support Emphasize production quality development tools
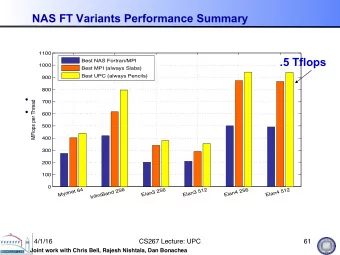
• � Productivity = performance without pain + portability • � Provide support for application adaptation (load balance, comm/comp overlap, scheduling, synchronization) • � Challenges: scale, heterogeneity, convergence of shared and distributed memory optimizations • � Broad spectrum of approaches (distributed / shared memory) Fine grained communication optimizations (PACT’05) - � - � Automatic non-blocking communication (PACT’05, ICS’07) Performance models for loop nest optimizations (PPoPP’07, ICS’08, PACT’08) - � - � Applications ( IPDPS’05, SC’07, PPoPP’08, IPDPS’09) Adoption: >7 years concerted effort, DOE support and encouragement, one big government user • � One of the highest scaling FFT (NAS) results to date (~2 Tflops) • � Communication is aggressively overlapped with computation • � UPC vs MPI – 10%-70% faster one-sided is more effective ���������������������������������������������������������������������������������������������������� ��������������������������������������������������������������������������������������������
• � Best performance of “primitive” operations – � Select best implementation available for “primitive” operations (put/get, sync) Provide efficient implementations for library “abstractions” (collectives) – � • � Optimizations – � Single node performance – � Mechanisms to efficiently map application to hardware/OS Runtime Adaptation – � Program transformations – minimize processor “idle” waiting • � Multi-level optimizations (distributed and shared memory) • � Compile time, static optimizations are not sufficient • � Adaptation = runtime – � Program Description – � Performance Models vs Autotuning – � Parameter Estimation/Classification Instantaneous vs Asymptotic Guided vs Automatic Offline vs Online – � Feedback Loop – � Static topology mapping vs dynamic
Code Generation Compile Time Transformations Runtime Mechanisms Estimate Params Communication Oblivious (numerical) Performance Transformations Database Analyze Comm Requirements Communication Aware Performance Analysis Models MessageVectorization Estimate Load Message Strip-Mining Data Redistribution Memory Instantiate Comm Manager Plan (Cache) Estimation of Performance Eliminate Redundant Parameters Comm & Reshape (categorical) Description + Code Templates • � Describe program behavior, lightweight representation ( Paek - LMAD perfect nests ) - � Easily extended for symbolic analysis - � RT-LMAD similar to SSA- irregular loops • � Decouple serial transformations from communication transformations - � Serial transformations - cache parameters (static/conservative) - � Communication transformations - network parameters (dynamic) • � No performance loss when decoupling optimizations - � Coarse grained characteristics - � Blocking for cache and network at different scales - � Compute and communication bound are categories - � Multithreading - � No global communication scheduling (intrinsic computation)
COMMUNICATION OPTIMIZATIONS • � Domain Decomposition and Scheduling for Code Generation • � Efficient High Level Communication Primitives (collectives,p2p) • � Application level performance determining factors: – � Computation – � Spatial - topology (point-to-point, one-from-many, many-from-one, many-to-many) – � Temporal - schedule ( burst, peer order) • � System level performance determining factors: – � Multiple available implementations – � Resource constraints (issue queue, TLB footprint) – � Interaction with OS (mapping, scheduling) Adaptation: offline search, easy to evaluate heuristics, lightweight analysis
Overhead OR Inverse Bandwidth Flow Control, Fairness Models, Asymptotic > 2X Optimizations, Instantaneous Load Throttling load is desirable for performance InfiniBand Bandwidth Repartition for 128 Procs Across Bisection 900100 800100 700100 Bandwidth (KB/s) 600100 500100 400100 300100 200100 100100 100 10 100 1000 10000 100000 1000000 10000000 Size (bytes) • � Deployed systems are under-provisioned, unfair, noisy Two processors saturate the network, four processors overwhelm it (Underwood et al, SC’07) • � Performance is unpredictable and unreproducible • � Simple models can’t capture variation Quantitative or Qualitative?
• � Previous approaches measure asymptotic values, optimizations need instantaneous values • � Existing “time accurate” performance models do not account well for system scale OR wide SMP nodes • � Qualitative models: which is faster, not how fast! (PPoPP’07, ICS’08) Not time accurate, understand errors and model robustness, allow for imprecision/noise • � Spatiotemporal exploration of network performance: - � Short and large time scales – account for variability and system noise - � Small and large system scales – SMP node, full system • � Preserve Ordering – � Sample implementation space, transformation specific – � Be pessimistic – determine the worst case – � Track derivatives, not absolute values • � Analytical performance models ( strip-mining transformations, PPoPP’07 ) > 90% efficiency • � Multiprotocol implementation of vector operations ( ICS’08, PACT’08 )
TUNING OF VECTOR OPERATIONS • � Vector Operations – copy disjoint memory regions in one logical step ( scatter/gather ) • � Often used in applications: boundary data in finite difference, particle-mesh, sparse matrices, MPI Derived Data Types • � Well supported: • � Native : Elan, InfiniBand, IBM LAPI/DCMF • � Third party comm libraries: GASNet, ARMCI, MPI • � “Frameworks”: UPC, Titanium, CAF, GA, LAPI
• � Interfaces: strided, indexed • � Previous studies show the need for a multi-protocol approach • � Implementations: – � Blocking – no overlap (BLOCK) – � Pipelining – flow control and fairness are problems (PIPE) – � Packing – flow control and attentiveness are problems (VIS) foreach(S) start_time() • � Protocols : Blocking, Non-Blocking, Packing (AM based) for (iters) foreach(N) get(S) • � Empirical approach based on optimization space exploration end_time() - � Transfer structure (N, S) - � Application characteristics : active processors, communication topology, foreach(S) start_time() system size, instantaneous load for(iters) foreach(N) get_nb(S) sync_all • � For each setting – Which implementation is faster? end_time() • � Fast, lightweight decision mechanism – prune parameter space • � Strategy: best OR worst case scenario? foreach(S) start_time() for(iters) foreach(N) vector_get(N,S) end_time()
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.