
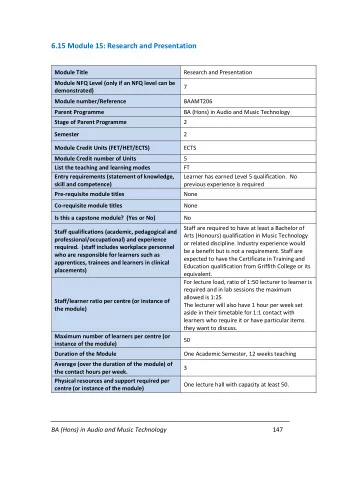
Module 15 POMDP Bounds CS 886 Sequential Decision Making and - PowerPoint PPT Presentation
Module 15 POMDP Bounds CS 886 Sequential Decision Making and Reinforcement Learning University of Waterloo Bounds POMDP algorithms typically find approximations to optimal value function or optimal policy Need some performance
Module 15 POMDP Bounds CS 886 Sequential Decision Making and Reinforcement Learning University of Waterloo
Bounds • POMDP algorithms typically find approximations to optimal value function or optimal policy – Need some performance guarantees • Lower bounds on 𝑊 ∗ – 𝑊 𝜌 for any policy 𝜌 – Point-based value iteration • Upper bounds on 𝑊 ∗ – QMDP – Fast-informed bound – Finite Belief-State MDP 2 CS886 (c) 2013 Pascal Poupart
Lower Bounds • Lower bounds are easy to obtain • For any policy 𝜌 , 𝑊 𝜌 is a lower bound since 𝑊 𝜌 𝑐 ≤ 𝑊 ∗ 𝑐 ∀𝜌, 𝑐 • The main issue is to evaluate a policy 𝜌 3 CS886 (c) 2013 Pascal Poupart
Point-based Value Iteration • Theorem: If 𝑊 0 is a lower bound, then the value functions 𝑊 𝑜 produced by point-based value iteration at each iteration 𝑜 are lower bounds. • Proof by induction – Base case: pick 𝑊 0 to be a lower bound 𝑜 𝑐 ≤ 𝑊 ∗ 𝑐 ∀𝑐 – Inductive assumption: 𝑊 – Induction: • Let Τ 𝑜+1 be the set of 𝛽 -vectors for some set 𝐶 of beliefs ∗ • Let Τ 𝑜+1 be the set of 𝛽 -vectors for all beliefs 𝛽 𝑐 ≤ 𝑊 ∗ (𝑐) • Hence 𝑊 𝑜+1 𝑐 = max 𝛽∈Τ 𝑜+1 𝛽(𝑐) ≤ max ∗ 𝛽∈Τ 𝑜+1 4 CS886 (c) 2013 Pascal Poupart
Upper Bounds • Idea: make decision based on more information than normally available to obtain higher value than optimal. • POMDP: states are hidden • MDP: states are observable • Hence 𝑊 𝑁𝐸𝑄 ≥ 𝑊 𝑄𝑃𝑁𝐸𝑄 5 CS886 (c) 2013 Pascal Poupart
QMDP Algorithm • Derive upper bound from MDP Q-function by allowing the state to be observable • Policy: 𝑡 𝑢 → 𝑏 𝑢 QMDP(POMDP) Solve MDP to find 𝑅 𝑁𝐸𝑄 Pr 𝑡 ′ 𝑡, 𝑏 max 𝑅 𝑁𝐸𝑄 𝑡, 𝑏 = 𝑆 𝑡, 𝑏 + 𝛿 𝑏 ′ 𝑅 𝑁𝐸𝑄 (𝑡′, 𝑏′) 𝑡 ′ 𝑐 = max 𝑐 𝑡 𝑅 𝑁𝐸𝑄 (𝑡, 𝑏) Let 𝑊 𝑡 𝑏 Return 𝑊 6 CS886 (c) 2013 Pascal Poupart
Fast Informed Bound • QMDP upper bound is too loose – Actions depend on current state (too informative) • Tighter upper bound: fast Informed bound (FIB) – Actions depend on previous state (less informative) 𝐺𝐽𝐶 ≥ 𝑊 ∗ 𝑊 𝑁𝐸𝑄 ≥ 𝑊 7 CS886 (c) 2013 Pascal Poupart
FIB Algorithm • Derive upper bound by allowing the previous state to be observable • Policy: 𝑡 𝑢−1 , 𝑏 𝑢−1 , 𝑝 𝑢 → 𝑏 𝑢 FIB(POMDP) Find 𝑅 𝐺𝐽𝐶 by value iteration Pr 𝑡 ′ 𝑡, 𝑏 Pr 𝑝 ′ 𝑡 ′ , 𝑏 𝑅 𝐺𝐽𝐶 (𝑡 ′ , 𝑏 ′ ) 𝑅 𝐺𝐽𝐶 𝑡, 𝑏 = 𝑆 𝑡, 𝑏 + 𝛿 𝑏 ′ max 𝑝 ′ 𝑡 ′ 𝑐 = max 𝑐 𝑡 𝑅 𝐺𝐽𝐶 (𝑡, 𝑏) Let 𝑊 𝑡 𝑏 Return 𝑊 8 CS886 (c) 2013 Pascal Poupart
FIB Analysis 𝐺𝐽𝐶 ≥ 𝑊 ∗ • Theorem: 𝑊 𝑁𝐸𝑄 ≥ 𝑊 • Proof: Pr 𝑡 ′ 𝑡, 𝑏 max 𝑏 ′ 𝑅 𝑡 ′ , 𝑏 ′ 1) 𝑅 𝑁𝐸𝑄 𝑡, 𝑏 = 𝑆 𝑡, 𝑏 + 𝛿 𝑡 ′ Pr 𝑡 ′ 𝑡, 𝑏 Pr 𝑝 ′ 𝑡 ′ , 𝑏 max = 𝑆 𝑡, 𝑏 + 𝛿 𝑏 ′ 𝑅(𝑡 ′ , 𝑏 ′ ) 𝑡 ′ 𝑝 ′ Pr 𝑡 ′ 𝑡, 𝑏 Pr 𝑝 ′ 𝑡 ′ , 𝑏 𝑅(𝑡 ′ , 𝑏 ′ ) ≥ 𝑆 𝑡, 𝑏 + 𝛿 𝑏 ′ max 𝑝 ′ 𝑡 ′ = 𝑅 𝐺𝐽𝐶 (𝑡, 𝑏) 𝐺𝐽𝐶 ≥ 𝑊 ∗ since 𝑊 2) 𝑊 𝐺𝐽𝐶 is based on observing the previous state (too informative) 9 CS886 (c) 2013 Pascal Poupart
Finite Belief-State MDP • Belief state MDP: all beliefs are treated as states 𝑊 ∗ 𝑐 = max 𝑅 ∗ (𝑐, 𝑏) 𝑏 • QMDP and FIB: value of each interior belief is 𝑐 = max 𝑐 𝑡 𝑅 𝐺𝐽𝐶 (𝑡, 𝑏) interpolated: i.e., 𝑊 𝑡 𝑏 • Idea: retain subset of beliefs – Interpolate value of remaining beliefs 10 CS886 (c) 2013 Pascal Poupart
Finite Belief-State MDP • Belief state MDP 𝑅 𝑐, 𝑏 = 𝑆 𝑐, 𝑏 + 𝛿 Pr 𝑝 ′ 𝑐, 𝑏 𝑏 ′ 𝑅(𝑐 𝑏,𝑝 , 𝑏 ′ ) max 𝑝 ′ • Let 𝐶 be a subset of representative beliefs • Approximate 𝑅(𝑐 𝑏,𝑝 , 𝑏 ′ ) with lowest interpolation – Linear program 𝑅 𝑐 𝑏,𝑝 , 𝑏 ′ = min 𝑑 𝑐 𝑅 𝑐, 𝑏 ′ 𝑐∈𝐶 𝑑 such that 𝑑 𝑐 = 1 and 𝑑 𝑐 ≥ 0 ∀𝑐 𝑐 11 CS886 (c) 2013 Pascal Poupart
Finite Belief-State MDP Algorithm • Derive upper bound by interpolating values based on a finite subset of values FiniteBeliefStateMDP(POMDP) Find 𝑅 𝐶 by value iteration Pr 𝑝 ′ 𝑐, 𝑏 max 𝑏 ′ 𝑅 𝐶 (𝑐 𝑏𝑝 ′ , 𝑏 ′ ) 𝑅 𝐶 𝑐, 𝑏 = 𝑆 𝑐, 𝑏 + 𝛿 ∀𝑐 ∈ 𝐶, 𝑏 𝑝 ′ where 𝑅 𝐶 𝑐 𝑏𝑝 ′ , 𝑏 ′ 𝑑 𝑐 𝑅 𝐶 (𝑐, 𝑏 ′ ) = min 𝑐∈𝐶 𝑑 such that 𝑑 𝑐 = 1 and 𝑑 𝑐 ≥ 0 ∀𝑐 ∈ 𝐶 𝑐∈𝐶 𝑐 = max 𝑐 𝑡 𝑅 𝐶 (𝑡, 𝑏) Let 𝑊 𝑡 𝑏 Return 𝑊 12 CS886 (c) 2013 Pascal Poupart
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.