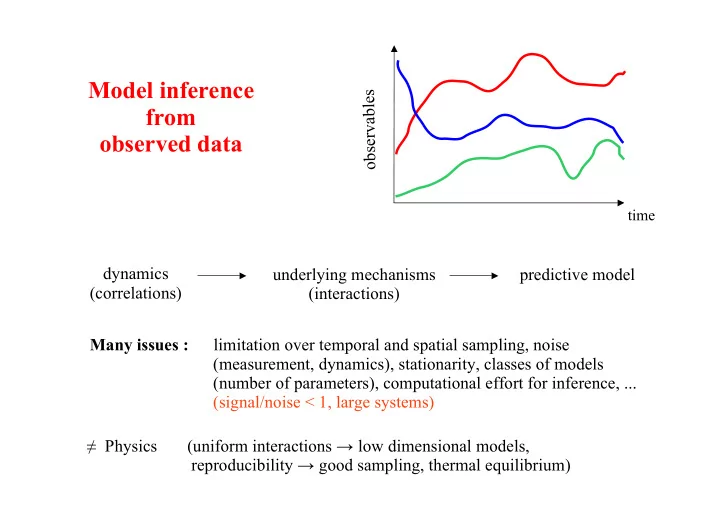
Model inference s e from l b a v observed data r e s b o - PowerPoint PPT Presentation
Model inference s e from l b a v observed data r e s b o time dynamics underlying mechanisms predictive model (correlations) (interactions) Many issues : limitation over temporal and spatial sampling, noise (measurement,
Model inference s e from l b a v observed data r e s b o time dynamics underlying mechanisms predictive model (correlations) (interactions) Many issues : limitation over temporal and spatial sampling, noise (measurement, dynamics), stationarity, classes of models (number of parameters), computational effort for inference, ... (signal/noise < 1, large systems) ! Physics (uniform interactions " low dimensional models, reproducibility " good sampling, thermal equilibrium)
Example 1: Concerted activity of a neural population Fujisawa, Amarasingham, Schnitzer, Meister (2003) Harrison, Buzsaki (2008) Schneidman et al. (2006)
• Network depend on activity (functional connections) • Connections can be modified through learning … ! Talk by S. Cocco on replay of cell assemblies after learning (memory consolidation) • More sophisticated methods to infer effective connections for encoding/decoding: encoding input output decoding
Example 2: Coevolution of residues in protein families PDZ domains Morais Cabral et al. (1996) • Conservation of residues (used for homology detection, phylogeny reconstruction) • Two-residue correlations ? could reflect structural and functional constraints ... Gobel et al. (1994) ! Talk by M. Weigt on covariation in protein families and the inverse Hopfield model ! Talk by O. Rivoire on spin glass models for protein evolution
Example 3: Order and organization in bird flocks ! Talk by by A. Jelic on information transfer in flocks of starlings
Example 4: Coupled dynamics of species in an ecological system Population ecology : interactions between species (existence, additivity, …) Lotka-Volterra equations: dN i dt = N i ( r i – # A ij N j ) j Issues : Measurement noise, dynamical noise, limited number of samples, unknown (not measured) species, … Is there any reliable signal about species-species 'interactions'? (additivity?) Exploit interactions to predict dynamics, extinction ?
Goals • Compression of data (eliminate indirect correlations, sparser representation?) correlated activity interaction interaction interaction • Find effective interaction network (ex: contact map in protein residue case) • Obtain predictive, generative models (ex : model for artificial protein sequences) Could be used to test effect of perturbation … to define 'energy' landscape and probe configuration space ... • Feedback with experiments : design of optimal, maximally informative protocols
Microscopic model for the data (1) (here, stationary and discrete data) (1,0,0,0,1,0,1,1, ..., 1,0,0,1,1,0) Data (0,1,0,0,0,1,1,1, ..., 0,1,1,0,0,0) " Probability p( $ 1 , $ 2 ,... , $ N )? (1,1,0,1,0,1,1,0, ..., 1,1,0,0,1,1) ... (0,1,0,0,1,0,0,0, ..., 0,0,0,1,0,0) m i = < ! i >, c ij = < ! i $ j >, ... (constraints are realizable) Constraints Maximum entropy principle (Jaynes, 1957) Find p( ! ) maximizing the entropy S[p] = - % p( ! ) ln p( ! ) under the selected constraints !
Microscopic model for the data (2) Analogy with Thermodynamics and Ensembles in Statistical Physics • System with energy E, volume V, N particles, ... • Fix average value of volume V # impose pressure p : E $ E + pV number of particules N # impose chemical potential µ : E $ E - µ N • E ( ! ;J,h) = - ! J ij $ i $ j - ! h i $ i Model Ising model! i<j i • p MAXENT ( ! ;J,h) = exp( -E( ! ;J,h) ) / Z[J,h] where Z[J,h] = % exp( -E( ! ;J,h) ) ! • find couplings and fields such that all N+ N(N-1)/2 constraints are fulfilled & ln Z[J,h] & ln Z[J,h] = m i = c ij , & h i & J ij
Boltzmann Machine Learning Ackley, Hinton, Sejnowski (1985) • Start from random J ij and h i • Calculate < $ i $ j > and < $ k > using Monte Carlo simulations • Compare to c ij and m k (data) and update J ij $ J ij - a (< $ i $ j > - c ij ) ) h k $ h k - a (< $ k > - m k ) Problems: 1. issue of thermalization (critical point ? may take exponential-in-N time …) 2. convergence (yes, but flat modes ?) $ slow
Microscopic model for the data (3) B Cross-entropy of data (= ! 1 ,..., ! B ) S † [J,h] = % - ln p( ! b ;J,h) b=1 = B ( ln Z[J,h] - ! J ij c ij - ! h i m i ) i i<j S † [J,h;data] J,h J*,h* • The minimum of S is the Ising model we are looking for : S † [J,h] S[p] S[p MAXENT ] = S † [J*,h*] • The Hessian of S is positive semi-definite, hence S is convex
Microscopic model for the data (4) Hessian of the cross-entropy ( ) < $ i $ j $ k > - < $ i > < $ j $ k > < $ i $ j $ k $ l > - < $ i $ j > < $ k $ l > & 2 S(J,h;data) = & (J,h) & (J,h) < $ i $ j $ k > - < $ i $ j > < $ k > < $ i $ j > - < $ i > < $ j > where < > = Gibbs average with the Ising model ( ) x ij X T ( ) X = ( # x ij ( $ i $ j - < $ i $ j >) + # x k ( $ k - < $ k >) ) 2 < > X = $ x k i<j k Log-prior on the parameters... Zero modes ? J,h
Bayesian inference framework (1) Data = set of configurations ! b , b = 1, 2, … , B= nb. of configs P[ J,h | Data] ' & P[ ! b | J,h ] ( P 0 [ J,h ] Bayes formula b P 0 [ J,h ] (useful in case of undersampling ...) Prior For instance : P 0 ' exp ( - ! J ij /(2J 2 ) ) 0 i<j P[ ! | J,h ] = exp ( ! J ij $ i $ j + ! h i $ i ) / Z[ J,h ] Likelihood i<j i
Bayesian inference framework (2) P[ J,h | Data ] ' exp ( B[ ! J ij c ij + ! h i m i ]) / Z[ J,h ] B Posterior Proba of J,h i<j i ' P 0 [ J,h ] S = - ln P[ J,h | Data ] Regularized Cross-entropy = B ( ln Z[J,h] - ! J ij c ij - ! h i m i ) - ln P 0 [ J,h ] i<j i = B ( ln Z[J,h] - ! J ij c ij - ! h i m i ) + ! J ij /(2J 2 ) 0 i<j i i<j (with Gaussian prior)
Questions 1. Practical methods to find interactions J ij from the correlations c ij ? (fast, accurate algorithms) 2. How much data does one need to get reliable interactions? (overfitting ...) |J* ) J| ? J* $ configurations {S i } $ c $ J B = nb. configs
Questions Asymptotic inference : B $ infinity, while N is kept fixed Error on each parameter of the order of B -1/2 What happens in practice, i.e. when B and N are of the same order of magnitude ? 3. How large should be the sampled sub-system? correlation length Is the inverse problem well-behaved ?
Inference approaches • Gaussian inference (and Mean field) • Inverse Hopfield-Potts model • Pseudo-likelihood algorithms • Advanced statistical physics methods
Interactions from correlations for Gaussian variables N Gaussian variables x i with variances c ii = <x i x i > = 1 i ! j : c ij = <x i x j > = + + + … J ij % J ik J kj % J ik J kl J lj k k,l Matrix notation: c = Id + J + J 2 + J 3 + … = (Id-J) -1 " J = Id – c -1 Time = N 3 Problems: • Matrix c corrupted by noise, which makes inversion very unreliable Empirical matrix c = ( ) ^ " Errors of order (N/B) 1/2 … c ij ± B -1/2 N nb. of data
• Not correct for discrete variables (neurons=0,1 ; amino-acids=1,2, .., 21) J Gaussian … but with regularization pseudo-count L 2 (quadratic log-prior) 2-spin system • Gaussian theory corresponds to mean-field theory Why? MF exact when effective fields average out = with many neighbors & weak interactions, and fluctuations are described by Gaussian law example: very large dimensions D in physical systems lead to N(0,1/D)
Inference approaches • Mean field inference • Inverse Hopfield-Potts model • Pseudo-likelihood algorithms • Advanced statistical physics methods
Inverse Hopfield model : retarded learning phase transition Example: N=100 , ! = Gaussian (0,.7) | * + ) * | #config=40 # config / N Phase transition! #config=400 Retarded learning: Watkin, Nadal (1994) Baik, Ben Arous, Peche (2005)
Inverse Hopfield Model : posterior entropy of patterns Example : P=1 pattern, no field Cocco, M., Sessak (2011) * 2 /N = 1.1 * 2 /N = 0.5 Retarded learning transition ) ) s s t t i i b b ( ( ~1/ ( ? ( " c =2, ! L =1)
Inverse Hopfield Model : error on the inferred patterns For pattern components ~1, corrections to S 0 are useless (at best) unless many configurations are available ... " Mean-Field is better (even if wrong) when few data are available
Inference approaches • Mean field inference • Inverse Hopfield-Potts model • Pseudo-likelihood algorithms • Advanced statistical physics methods
Pseudo-likelihood methods (1) Idea: avoid calculation of partition function using Callen identities (1963) < $ 0 > = < tanh( % J 0k $ k + h 0 ) > k k ! 0 b ) % tanh( % J 0k $ k + h 0 ) / B J 0k 0 k ! 0 sampled configurations Pseudo cross entropy: b « S » = % log 2 cosh( % J 0k $ k + h 0 ) - B (h 0 m 0 + % J 0k c 0k ) sampled k ! 0 k ! 0 configurations Prior: increase signal/noise ratio by exploiting the sparsity of J ij cost function ({J}) = pseudo-cross entropy (h 0 ,{J 0k }) + * % |J 0k | k
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.