Measuring Hyperlink Distances Wikipedia case study Rodrigo R. Paim Daniel R. Figueiredo Universidade Federal do Rio de Janeiro 2 nd Workshop of Brazilian Institute for Web Science Research
Webpages and Hyperlinks Paim & Figueiredo - 2011
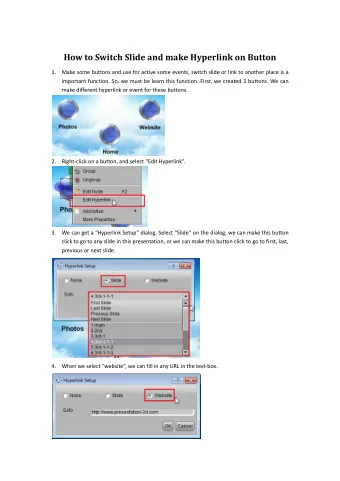
The Web Graph Webpages → Vertices Hyperlinks → Directed Edges Campus UFRJ Rio Brazil Paim & Figueiredo - 2011
Hyperlink Distance Webpages have some specific content Can’t get it from structure of the web New concept to analyze “connected webpages” Inversely proportional to contextual similarity d 2 Economic Physics Crisis d 1 < d 2 , d 3 d 1 Greece Europe Maths d 3 Paim & Figueiredo - 2011
Measuring Distances Multiple distance metrics Variation of Jaccard distance IDF-based Keywords play a crucial role Indicate context of a webpage Why to measure distances? Paim & Figueiredo - 2011
Navigating the Web Can one go from any webpage to another using local information only? Image from The Opte Project Website Paim & Figueiredo - 2011
Navigating the Web Car Safety Food Paim & Figueiredo - 2011
Navigating the Web Car Safety Restaurant Food Industry Agriculture Food Paim & Figueiredo - 2011
Navigating the Web Car Food Safety Processing Nestlé Restaurant Food Industry Manufacturing Agriculture Food Paim & Figueiredo - 2011
Navigating the Web Car Food Safety Processing Automotive Nestlé Industry Restaurant Food Automobile Industry Manufacturing Agriculture Food Paim & Figueiredo - 2011
Navigating the Web Car Food Safety Processing Automotive Nestlé Industry Restaurant Food Automobile Industry Manufacturing Agriculture Food Paim & Figueiredo - 2011
Problem Formulation Decentralized greedy algorithm From any u to any v Choose closest hyperlink to destination Local information only Can it reach destination? In few steps Using hyperlink distances Paim & Figueiredo - 2011
Case Study Wikipedia Two major sets D : Documents (articles) C : Categories Keywords of documents Wikipedia web graph Vertices (~ 3.6 M) Edges (~ 100 M) Paim & Figueiredo - 2011
Navigation Algorithms BFS Minimum distance with global knowledge Random Walk Next webpage chosen randomly Greedy Algorithm Only closest neighbor (dead ends) Modified Greedy Closest neighbor (not visited yet) Paim & Figueiredo - 2011
Results
Results 96.45%
Results 16.88%
Results Dead Ends 5.46%
Results 45.27%
Conclusion Greedy performs worse than Random Walk But Modified Greedy performs better Only for big distances However far from optimal (BFS) Categories are not a good “compass” Ongoing work: How to define a better greedy algorithm? Paim & Figueiredo - 2011
Thanks for your attention! Rodrigo R. Paim Daniel R. Figueiredo LAND – PESC/COPPE - UFRJ Measuring Hyperlink Distances: Wikipedia Case Study ACM WebSci'11 (Extended Abstract) Paim & Figueiredo - 2011
Recommend
More recommend
Unleash a World of Digital Possibilities—Browse, Share, and Explore Content Without Boundaries