
High Dimensional Classification in the Presence of Correlation: A - PowerPoint PPT Presentation
High Dimensional Classification in the Presence of Correlation: A Factor Model Approach A. PEDRO DUARTE SI LVA * Faculdade de Economia e Gesto / Centro de Estudos em Gesto e Economia Universidade Catlica Portuguesa Centro Regional do
High Dimensional Classification in the Presence of Correlation: A Factor Model Approach A. PEDRO DUARTE SI LVA * Faculdade de Economia e Gestão / Centro de Estudos em Gestão e Economia Universidade Católica Portuguesa Centro Regional do Porto PARIS, 23-28 August 2010 Compstat’ 2010 (*) Supported by: FEDER / POCI 2010
High Dim ensional Correlation Adjusted Classification Overview 1. A Factor-model linear classification rule for High-Dimensional correlated data 2. Asymptotic properties with p 3. Variable selection for problems with “rare” and “mostly weak” group differences 4. Performance in Micro-Array problems 5. Conclusions and Perspectives Compstat ’ 2010 PARIS, 23-28 August 2010
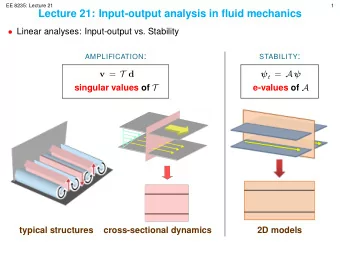
High Dim ensional Correlation Adjusted Classification Problem Statment: X p ( Y ; X ) Y {0,1} We want to find a rule that predicts Y given X ˆ Y argmax π f (X) Bayes rule: g g g X | Y ~ N ( μ , Σ ) Assuming p (Y) Bayes rule: π 1 = ( 1 ) - ( 0) { } 1 ( ) ˆ Y T 1 Δ Σ X ( μ μ ) log 0 i 0 1 2 π 1 How to estimate -1 when p > n and the X correlations are important ? Compstat ’ 2010 PARIS, 23-28 August 2010
High Dim ensional Correlation Adjusted Classification A Factor-Model Approach i P f i q X i = ( Yi) + B f i + i q < < p j D (j) > k 0 0 f ~ N (0 , I ) ε ~ N (0 , D ) i q q i p ε = B B T + D -1 = D -1 B [ I q + B T D -1 B] -1 B T D -1 - D -1 ˆ Σ T ˆ ˆ ˆ B B D RFctq ε ˆ ˆ ˆ -1/2 ˆ ˆ -1/2 ˆ -1/2 ˆ -1/2 2 B , D arg min || V Σ V V S V || RFctq F B ˆ , D ˆ ε Compstat ’ 2010 PARIS, 23-28 August 2010
High Dim ensional Correlation Adjusted Classification Asym ptotic Properties We will compare empirical linear rules 1 n { } ( ) ˆ T ˆ 1 δ 1 Δ Σ X ( X X ) log 0 L δ i 0 1 2 n L 1 and estimator ˆ Δ For some parameter space Γ satisfying δ L ˆ 2 max E || Δ Δ || o(1) ( C1 ) Γ L θ δ based on the criterion ˆ T ˆ -1 ˆ Δ Σ Δ δ W ( δ max P δ (Y 1 | Y 0 max 1 Φ L ) ) Γ L Γ θ L i i Γ δ δ δ ˆ T -1 -1 ˆ L L L ˆ ˆ 2 Δ Σ Σ Σ Δ δ δ L L n(p) when p ; d p Compstat ’ 2010 PARIS, 23-28 August 2010
High Dim ensional Correlation Adjusted Classification Asym ptotic Properties Main Result T 1 2 θ : Δ Σ Δ c , when k λ ( ) λ ( Σ k ) 1 min max 2 θ μ , μ , Σ Γ (k , k , k , q, B, c) Δ B (0) (1) F 0 1 2 q β (j, a) 0 = 1 = 1 / 2 j, a R(j' , l' ) j' , l' D (j) j ε ( C1 ) is satisfied R(j' , l' ) j' , l' T 2 -1/2 -1/2 2 -1/2 -1/2 Σ B B D arg min || R V Σ V || R V Σ V RFctq B, D RFctq F RFctq RFct q n(p) p ; It follows that: when log p 1 1 K λ ( Σ ) Σ Σ Σ Σ 0Fq 2 2 max 0Fq W ( δ 1 Φ c K max ) RFct RFct Γ Fq Fq q q 0Fq Γ 0F 1 K λ ( Σ ) q δ F q 0Fq min 0Fq Compstat ’ 2010 PARIS, 23-28 August 2010
High Dim ensional Correlation Adjusted Classification Selecting Predictors 1 - Rank variables acording to tw o-sam ple t-scores 2 – Choose a selection cut-off for the score values (Donoho e Jin 2004) Higher Criticism Given p ordered p-values: 1 , ..., p ( ) j/p - π p j HC(j; π ) j ( ) ( ) j / p 1 - (j / p) HC * max HC(j; π ) j α j 0 Compstat ’ 2010 PARIS, 23-28 August 2010
High Dim ensional Correlation Adjusted Classification Selecting Predictors Higher Criticism I n a tw o-group hom okedastic m odel, w ith : - Diagonal classification rules - p-values derived from two-group t-scores - Independent variables - Rare “effects” (mean group diferences) - Weak effects w hen p HC* is asym ptotically equivalent to the (Donoho e Jin 2009) optim al selection threshold Compstat ’ 2010 PARIS, 23-28 August 2010
High Dim ensional Correlation Adjusted Classification Selecting Predictors Control of false discovery rates Given a sequence of p independent tests w ith ordered p-values: 1 , ..., p Reject the null hypothesis ( H 0 j ) w here j k, w ith j (Benjamini e Hochberg 1995) k max j : π α j p Given a sequence of p dependent tests w ith ordered p-values: 1 , ..., p Reject the null hypothesis ( H 0 j ) w here j k, w ith j (Benjamini e Yekutieli 2001) k max j : π α j p 1 p i i 1 Compstat ’ 2010 PARIS, 23-28 August 2010
High Dim ensional Correlation Adjusted Classification Selecting Predictors Expanded Higher Criticism A selection scheme for problems where effects are rare and m ost (but not necessarly all) effects are weak 1 - Include all variables that satisfy Benjamini and Yekutieli’s criterion Estimate an “empirical null distributiuon” 2 - 3 - Compute p-values for the effects of non-selected variables, based on the null estimated in step 2 4 - Find the HC* threshold from the p-values computed in step 3 Compstat ’ 2010 PARIS, 23-28 August 2010
High Dim ensional Correlation Adjusted Classification Singh’s Prostate Cancer Data – p= 6033; n= 50+ 52 Rule Error Estimate # Variables kept (std error) (min – median - max) 0.2146 58 – 134.5 – 421 Fisher’s LDA* (0.0101) 0.0670 Naive Bayes* 58 – 134.5 – 421 (0.0052) 0.0642 Support Vector Machines* 58 – 134.5 – 421 (0.0052) 0.0838 108 – 356 – 1771 Nearest Shruken Centroids (0.0063) 0.0741 Regularized DA 82 – 390 – 1201 (0.0053) 0.0650 Shrunken DA* 58 – 134.5 – 421 (0.0051) 0.0641 Factor-based LDA* (q=1) 58 – 134.5 – 421 (0.0052) 0.0720 NLDA* 58 – 134.5 – 421 (0.0052) * After variable selection by the maximum of FDR (False Discovery Rates) and HC (Higher Criticism), both derived from Independence based T-scores. The p-values used in the HC computations are derived from empirical Null distributions Compstat ’ 2010 PARIS, 23-28 August 2010
High Dim ensional Correlation Adjusted Classification Golubs’s Leukemia Data –- p = 7 129 ; n = 47+ 25 Rule Error Estimate # Variables kept (std error) (min – median - max) 0.2558 326 – 478 – 712 Fisher’s LDA* (0.0109) 0.480 326 – 478 – 712 Naive Bayes* (0.0085) 0.0405 326 – 478 – 712 Support Vector Machines* (0.0049) 0.0201 Nearest Shruken Centroids 703 – 3166 – 7129 (0.0039) 0.0491 12 – 1934 – 7124 Regularized DA (0.0062) 0.0276 326 – 478 – 712 Shrunken DA* (0.0044) 0.0174 Factor-based LDA* (q=1) 326 – 478 – 712 (0.0034) 0.1510 326 – 478 – 712 NLDA* (0.0085) * After variable selection by the maximum of FDR (False Discovery Rates) and HC (Higher Criticism), both derived from Independence based T-scores. The p-values used in the HC computations are derived from empirical Null distributions Compstat ’ 2010 PARIS, 23-28 August 2010
High Dim ensional Correlation Adjusted Classification Alon’s Colon Data -– p = 2 000 ; n = 40+ 22 Rule Error Estimate # Variables kept (std error) (min – median - max) 0.3285 3 – 71.5 – 200 Fisher’s LDA* (0.0143) 0.2275 3 – 71.5 – 200 Naive Bayes* (0.0133) 0.1576 Support Vector Machines* 3 – 71.5 – 200 (0.0095) 0.1563 Nearest Shruken Centroids 7 – 39 – 527 (0.0098) 0.2174 14 – 425 – 2000 Regularized DA (0.0126) 0.1865 3 – 71.5 – 200 Shrunken DA* (0.0100) 0.1746 Factor-based LDA* (q=1) 3 – 71.5 – 200 (0.0098) 0.2614 3 – 71.5 – 200 NLDA* (0.0114) * After variable selection by the maximum of FDR (False Discovery Rates) and HC (Higher Criticism), both derived from Independence based T-scores. The p-values used in the HC computations are derived from empirical Null distributions Compstat ’ 2010 PARIS, 23-28 August 2010
High Dim ensional Correlation Adjusted Classification Conclusions A factor-m odel classification rule, designed for high- dim ensional correlated data, w as proposed Asymptotic Analysis show that As p the new rule can approach a low expected error rate Often, much lower than unrestricted covariance rules independence-based rules Empirical comparisons sugest that w hen com bined w ith sensible variable selection schem es the new rule is highly com petitive in MicroArray Applications Compstat ’ 2010 PARIS, 23-28 August 2010
Recommend







![Classification Image Classification Set of predefined categories [eg: table, apple, dog, giraffe]](https://c.sambuz.com/743996/classification-s.webp)














More recommend
Explore More Topics
Stay informed with curated content and fresh updates.