
Generalization and Simplification in Machine Learning Shay Moran - PowerPoint PPT Presentation
Generalization and Simplification in Machine Learning Shay Moran School of Mathematics, IAS Princeton . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Two dual aspects of
Generalization and Simplification in Machine Learning Shay Moran School of Mathematics, IAS Princeton . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Two dual aspects of “learning” Two aspects: 1. Generalization: Infer new knowledge from existing knowledge. 2. Simplification: Provide simple(r) explanations for existing knowledge. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Interrelations Simplification Generalization e.g. math: simplification generalization simpler proof more general theorem theorem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Philosophical heuristics Simplification Generalization Simpler (consistent) explanations are better. [Occam’s razor – William of Ockham ≈ 1300]. simplification = ⇒ generalization If I can’t reduce it to a freshman level then I don’t really understand it. [Richard Feynman 1980’s]. when James Gleick (a science reporter) asked him to explain why spin-1/2 particles obey Fermi-Dirac statistics When presented with a complicated proof, Erd¨ os used to reply: “Now, let’s find the book’s proof. . . ” [Paul Erd¨ os] generalization = ⇒ simplification Can these relations be manifested as theorems in learning theory? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
This talk ”Simplification ≡ Generalization” in Learning Theory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Plan Generalization Simplification/compression The “generalization – compression” equivalence Binary classification Multiclass categorization Vapnik’s general setting of learning Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Generalization: General Setting of Learning [Vapnik ’95] . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . .. . . . . .
Intuition Imagine a scientist that performs m experiments with outcomes z 1 , . . . , z m and wishes to predict the outcome of future experiments. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Classification example: intervals D – unknown distribution over R c – unknown interval: Given: Training set ( ) ( ) ∼ D m S = x 1 , c ( x 1 ) , . . . , x m , c ( x m ) Goal: Find h = h ( S ) ⊆ R that minimizes the disagreement with c [ ] E x ∼D 1 c ( x ) ̸ = h ( x ) in the Probably (w.p. 1 − δ ) Approximately Correct (up to ϵ ) sense . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Regression example: mean estimation D – unknown distribution over [0 , 1] Given: Training set S = z 1 , . . . , z m ∼ D m 0 . 3 0 . 2 0 . 1 0 0 2 4 6 8 10 Goal: Find h = h ( S ) ∈ [0 , 1] that minimizes ( x − h ) 2 ] [ E x ∼ D in the Probably (w.p. 1 − δ ) Approximately Correct (up to ϵ ) sense . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
The General Setting of Learning: definition H hypothesis class D distribution over examples ℓ loss function . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
The General Setting of Learning: definition H hypothesis class D distribution over examples ℓ loss function Output: h out known to learner: H unknown to learner: D z 1 , . . . , z m i.i.d examples from D Nature Learning algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
The General Setting of Learning: definition H hypothesis class D distribution over examples ℓ loss function Output: h out known to learner: H unknown to learner: D z 1 , . . . , z m i.i.d examples from D Nature Learning algorithm Goal: loss of h out ≤ loss of best h ∈ H in the PAC sense classification problems, regression problems, some clustering problems,. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Examples Binary classification: ▶ Z = X × { 0 , 1 } ▶ H – class of X → { 0 , 1 } functions ▶ ℓ ( ) [ ] h , ( x , y ) = 1 h ( x ) ̸ = y . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Examples Binary classification: ▶ Z = X × { 0 , 1 } ▶ H – class of X → { 0 , 1 } functions ▶ ℓ ( ) [ ] h , ( x , y ) = 1 h ( x ) ̸ = y Multiclass categorization: ▶ Z = X × Y ▶ H – class of X → Y functions ▶ ℓ ( ) [ ] h ( x , y ) = 1 h ( x ) ̸ = y . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Examples Binary classification: ▶ Z = X × { 0 , 1 } ▶ H – class of X → { 0 , 1 } functions ▶ ℓ ( ) [ ] h , ( x , y ) = 1 h ( x ) ̸ = y Multiclass categorization: ▶ Z = X × Y ▶ H – class of X → Y functions ▶ ℓ ( ) [ ] h ( x , y ) = 1 h ( x ) ̸ = y Mean estimation: ▶ Z = [0 , 1] ▶ H = [0 , 1] ▶ ℓ ( h , z ) = ( h − z ) 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Examples Binary classification: ▶ Z = X × { 0 , 1 } ▶ H – class of X → { 0 , 1 } functions ▶ ℓ ( ) [ ] h , ( x , y ) = 1 h ( x ) ̸ = y Multiclass categorization: ▶ Z = X × Y ▶ H – class of X → Y functions ▶ ℓ ( ) [ ] h ( x , y ) = 1 h ( x ) ̸ = y Mean estimation: ▶ Z = [0 , 1] ▶ H = [0 , 1] ▶ ℓ ( h , z ) = ( h − z ) 2 Linear regression: ▶ Z = R d × R ▶ H – class of affine R d → R functions ) 2 ▶ ℓ ( ) ( h , ( x , y ) = h ( x ) − y . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Agnostic and realizable-case Learnability H – hypothesis class H is agnostic learnable: ∃ algorithm A , s.t. for every D , if m > n agn ( ϵ, δ ) S ∼D m [ L D ( A ( S )) ≥ min Pr h ∈H L D ( h ) + ϵ ] ≤ δ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Agnostic and realizable-case Learnability H – hypothesis class H is agnostic learnable: ∃ algorithm A , s.t. for every D , if m > n agn ( ϵ, δ ) S ∼D m [ L D ( A ( S )) ≥ min Pr h ∈H L D ( h ) + ϵ ] ≤ δ H is realizable-case learnable: ∃ algorithm A s.t. for every realizable D , if m > n real ( ϵ, δ ) S ∼D m [ L D ( A ( S )) ≥ ϵ ] ≤ δ Pr ▶ D is realizable if there is h ∈ H with L D ( h ) = 0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Compression: Sample compression schemes [Littlestone,Warmuth ’86] . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . .. . . . . .
Intuition Imagine a scientist that performs m experiments with outcomes z 1 , . . . z m and wishes to choose d ≪ m of them in a way that allows to explain all other experiments (choose d axioms) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
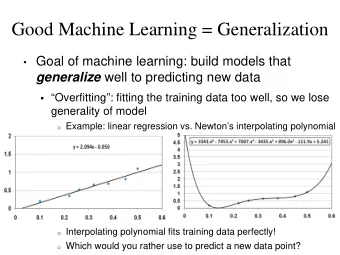
Example: polynomials P – unknown polynomial of degree ≤ d : Input: training set of m evaluations of P ( d ≪ m ) − 2 − 1 0 1 2 3 Compression: Keep d + 1 points − 2 − 1 0 1 2 3 Reconstruction: Lagrange Interpolation Evaluates to the correct value on the whole training set . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Compression algorithm: definition [Littlestone,Warmuth ’86] H hypothesis class ℓ loss function . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Compression algorithm: definition [Littlestone,Warmuth ’86] H hypothesis class ℓ loss function Compression scheme of size d : S = z 1 , z 2 , . . . , z m Output: h out Input sample z i 1 , . . . , z i d Compression Compressor Reconstructor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Compression algorithm: definition [Littlestone,Warmuth ’86] H hypothesis class ℓ loss function Compression scheme of size d : S = z 1 , z 2 , . . . , z m Output: h out Input sample z i 1 , . . . , z i d Compression Compressor Reconstructor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Compression algorithms examples Compression algorithm for interval approximation of size 2: “output the smallest interval containing the positive examples” input sample output hypothesis Compression algorithm for mean estimation of size 3: “output the average of 3 sample points with minimal empirical error” 0 . 3 0 . 2 0 . 1 0 0 2 4 6 8 10 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.