Estimating Environmental Exposure using Cell Tower Data Owais Gilani, Bucknell University Michael Kane, Yale University Simon Urbanek, AT&T Labs Research
Outline Motivation : Why should we care about environmental exposure? Background : How is exposure done now? Approach : What are we doing to improve it? Results : A demo showing community-level exposure incorporating human mobility. Conclusion : Mobility is an important next step in exposure modeling
Why should we care about environmental exposure?
Exposure is linked to asthma Over 8% of the U.S. population has asthma. 1.5 million emergency room visits in 2015. In 2015 3,615 people died of asthma. Asthmatics are 40% more likely to have acute episodes on high pollution days.
Exposure is linked to cancer "... outdoor air pollution is a 'Category 1'- or de fi nite cause of cancer." 41% of Americans will be diagnosed with cancer and 21% will die from it. Environmental pollution causes at least 2% of cases.
Exposure is linked to poor fetal development Air pollution signi fi cantly increases the risk of low birth weight in babies, leading to lifelong damage to health. Cutting pollution to that guideline would prevent 300- 350 babies a year being born with low weight in London per year. Globally, 90% of children globally are exposed to air pollution above WHO guidelines.
Pollution Types Ozone Higher concentrations in summer Generated by cars, industrial facilities, etc. Fine particulate matter (PM 2.5) Higher concentrations in winter Increased mortality from lung cancer and heart disease Nitrogen Oxide NOx From fuel combustion Highest concentration on roads but also from energy production
How is exposure modeled now?
First, you model pollution The U.S. has 12 pollution monitoring sites, 12 of which are in CT. Get temperature, wind speed, wind direction, and the minimum distance to primary and secondary roads for census tracts. Model the pollution for each of the census tracts.
library(spTimer) x_train <- read.csv("pollution_data_train.csv") x_test <- read.csv("pollution_data_test.csv") # Gaussian Process model. pfit <- spT.Gibbs(formula = ozone.ppb ~ Temp2 + WindSpeed2 + minDistPrim+minDistSec, data = x, model = "GP", coords = ~ Longitude + Latitude) # Spatial Prediction. preds <- predict(pfit, newdata = x_test, newcoords = ~ Longitude + Latitude) # Compare modeled results with actuals. spT.validation(x_test$ozone.ppb, c(preds$Median))
How do we model exposure? We have: Estimate of the amount of ozone in the air at any location. Population estimates for any census tract We can multiply the amount of pollution by the number of people in the census tract to get the distribution of average exposure in the state of CT.
Does anyone see problems with this?
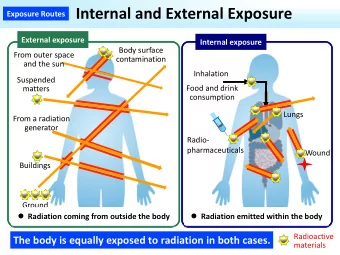
How does cell data help?
Our approach For a user: Get the sequence of tower check-ins and their duration. Find the daily user exposure based on his/her location. Then, fi nd the distribution of exposures for any census tract
A note on anonymity from the CDC website Data obtained from the National Center for Health Statistics: Compressed Mortality, Multiple Cause of Death, Linked Birth / Infant Death records and Natality, are also covered by the following policy: The Public Health Service Act (42 U.S.C. 242m(d)) provides that the data collected by the National Center for Health Statistics (NCHS) may be used only for the purpose for which they were obtained; any e ff ort to determine the identity of any reported cases, or to use the information for any purpose other than for statistical reporting and analysis, is against the law. Therefore users will: Use these data for statistical reporting and analysis only. For sub-national geography, do not present or publish death or birth counts of 9 or fewer or rates based on counts of nine or fewer (in fi gures, graphs, maps, table, etc.). Make no attempt to learn the identity of any person or establishment included in these data. Make no disclosure or other use of the identity of any person or establishment discovered inadvertently and advise the Director, NCHS of any such discovery.
Research Questions How much does ozone exposure vary in CT commuters when we don't assume people are stationary? Where do we see the largest di ff erence in ozone exposure in the two models?
What is a CT commuter? An AT&T user with a device that is connected to the network. Someone who is in CT for the entire day. Someone who checks into at least 3 towers within a 500m bu ff er of a primary or secondary road.
Are these really only "commuters?"
Procedure Split on users/devices. For each user check-in, get the towers location, time on the tower (in seconds). Join with the exposure at the tower lat, lon, time.
What does typical code look like?
library(rgdal) census_tract_gen <- function(tract_shapefile, tract_id, projection=CRS(paste("+proj=utm +zone=17 +ellps=WGS84 +datum=WGS84", "+units=m +no_defs "))) { function(lon, lat) { x <- cbind(lon, lat) x.dat <- data.frame(id=1:nrow(x)) xx <- SpatialPointsDataFrame(x, x.dat) proj4string(xx) = CRS("+init=epsg:4326") xx.proj <- spTransform(xx, projection) shf.proj <- spTransform(tract_shapefile, projection) xx.tract <- xx.proj %over% shf.proj as.character(xx.tract[, tract_id]) } } ct <- readOGR("ShapeFiles/CT Census Tracts/", "tl_2016_09_tract") census_tract <- census_tract_gen(tract_shapefile=ct, tract_id="GEOID")
So what are the results?
Conclusions The absolute cumulative difference is up to 0.05 PPH. Even with its low-spatial variation, assuming no spatial variation introduces significant bias.
Recommend
More recommend
Unleash a World of Digital Possibilities—Browse, Share, and Explore Content Without Boundaries