
DENSELY CONNECTED CONVOLUTIONAL NETWORKS Gao Huang*, Zhuang Liu*, - PowerPoint PPT Presentation
Best paper award DENSELY CONNECTED CONVOLUTIONAL NETWORKS Gao Huang*, Zhuang Liu*, Laurens van der Maaten, Kilian Q. Weinberger Cornell University Tsinghua University Facebook AI Research CVPR 2017 CONVOLUTIONAL NETWORKS LeNet AlexNet VGG
Best paper award DENSELY CONNECTED CONVOLUTIONAL NETWORKS Gao Huang*, Zhuang Liu*, Laurens van der Maaten, Kilian Q. Weinberger Cornell University Tsinghua University Facebook AI Research CVPR 2017
CONVOLUTIONAL NETWORKS LeNet AlexNet VGG Inception ResNet
STANDARD CONNECTIVITY
RESNET CONNECTIVITY Identity mappings promote gradient propagation. : Element-wise addition Deep residual learning for image recognition: [He, Zhang, Ren, Sun] (CVPR 2015)
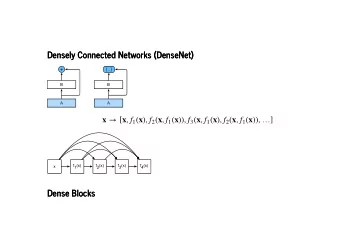
DENSE CONNECTIVITY C C C C : Channel-wise concatenation C
DENSE AND SLIM C C C C k channels k channels k channels k channels k : Growth Rate
FORWARD PROPAGATION x 4 x 4 x 3 x 3 x 2 x 2 x 1 x 1 x 0 x 0 x 3 h 1 h 2 h 3 x 2 h 4 x 1 x 0 Batc Con x 2 ReL x 1 x 0 x 1 x 0 x 0
COMPOSITE LAYER IN DENSENET Convolution (3x3) Batch Norm x 3 x 4 x 2 x 3 ReLU x 1 x 2 x 0 x 1 x 0 k channels x 5 =h 5 ([x 0 , …, x 4 ])
COMPOSITE LAYER IN DENSENET WITH BOTTLENECK LAYER Convolution (1x1) Convolution (3x3) Batch Norm Batch Norm x 4 x 3 x 2 ReLU ReLU x 1 x 0 l x k 4 x k k channels channels channels Higher parameter and computational efficiency
DENSENET Dense Block 1 Dense Block 2 Dense Block 3 Convolution Convolution Convolution Pooling Pooling Pooling Linear Output Pooling reduces Feature map sizes match feature map sizes within each block
ADVANTAGES OF DENSE CONNECTIVITY
ADVANTAGE 1: STRONG GRADIENT FLOW Error Signal Implicit “deep supervision” Deeply supervised Net: [Lee, Xie, Gallagher, Zhang, Tu] (2015)
ADVANTAGE 2: PARAMETER & COMPUTATIONAL EFFICIENCY ResNet connectivity : #parameters: Input Output s e r u t a e f d e t a l O(C x C) e r r h l o C C C DenseNet connectivity: k<<C Input s e r u t a e Output f d e fi i s r e v i O(l x k x k) D k: Growth rate h l l X k k
ADVANTAGE 3: MAINTAINS LOW COMPLEXITY FEATURES Standard Connectivity: Classifier uses most complex (high level) features y = w 4 h 4 (x) w 4 classifier x h 1 (x) h 2 (x) h 3 (x) h 4 (x) Increasingly complex features
ADVANTAGE 3: MAINTAINS LOW COMPLEXITY FEATURES Dense Connectivity: y = w 0 x + w 0 Classifier uses features of all complexity levels w 1 +w 1 h 1 (x) w 2 +w 2 h 2 (x) w 3 +w 3 h 3 (x) w 4 C C C C +w 4 h 4 (x) classifier x h 1 (x) h 2 (x) h 3 (x) h 4 (x) Increasingly complex features
RESULTS
RESULTS ON CIFAR-10 ResNet (110 Layers, 1.7 M) ResNet (1001 Layers, 10.2 M) DenseNet (100 Layers, 0.8 M) DenseNet (250 Layers, 15.3 M) With data augmentation Without data augmentation 12.0 12.0 11.0 11.0 11.26 10.56 10.0 10.0 9.0 9.0 Previous SOTA Test Error (%) 8.0 8.0 7.3 7.0 7.0 Previous SOTA 6.41 6.0 6.0 5.9 5.0 5.0 5.2 4.62 4.2 4.5 4.0 4.0 3.6 3.0 3.0 2.0 2.0
RESULTS ON CIFAR-100 ResNet (110 Layers, 1.7 M) ResNet (1001 Layers, 10.2 M) DenseNet (100 Layers, 0.8 M) DenseNet (250 Layers, 15.3 M) With data augmentation Without data augmentation 35.0 35.0 35.58 33.47 Previous SOTA 30.0 30.0 28.2 Test Error (%) 27.22 Previous SOTA 25.0 25.0 24.2 22.71 22.3 20.5 20.0 20.0 19.6 17.6 15.0 15.0 10.0 10.0
RESULTS ON IMAGENET DenseNet ResNet DenseNet ResNet 28.0 28.0 ResNet-34 ResNet-34 26.0 26.0 DenseNet-121 DenseNet-121 Top-1 error (%) Top-1 error (%) ResNet-50 ResNet-50 24.0 24.0 DenseNet-169 DenseNet-169 DenseNet-201 DenseNet-201 ResNet-101 ResNet-101 ResNet-152 ResNet-152 22.0 22.0 DenseNet-264 DenseNet-264 DenseNet-264(k=48) DenseNet-264(k=48) 20.0 20.0 3 10 16 23 29 0 20 40 60 80 GFLOPs # Parameters (M) Top-1: 20.27% Top-5: 5.17%
MULTI-SCALE DENSENET (Preview) … … … … Classifier 1 Classifier 1 Classifier 2 Classifier 2 Classifier 3 Classifier 3 Classifier 4 cat: 0.2 cat: 0.4 cat: 0.6 0.2 ≱ threshold 0.4 ≱ threshold 0.6 > threshold Multi-Scale DenseNet: [Huang, Chen, Li, Wu, van der Maaten, Weinberger] (arXiv Preprint: 1703.09844)
MULTI-SCALE DENSENET (Preview) Test … Input Inference Speed: … ~ 2.6x faster than ResNets ~ 1.3x faster than DenseNets … … Classifier 1 Classifier 2 Classifier 3 Classifier 4 “Hard” examples “Easy” examples
Memory efficient Torch implementation: https://github.com/liuzhuang13/DenseNet Other implementations: Our Caffe Implementation Tensorflow Implementation (with BC structure) by Illarion Our memory-efficient Caffe Implementation. Khlestov. Our memory-efficient PyTorch Implementation. Lasagne Implementation by Jan Schlüter. PyTorch Implementation by Andreas Veit. Keras Implementation by tdeboissiere. PyTorch Implementation by Brandon Amos. Keras Implementation by Roberto de Moura Estevão Filho. MXNet Implementation by Nicatio. Keras Implementation (with BC structure) by Somshubra MXNet Implementation (supports ImageNet) by Xiong Lin. Majumdar. Tensorflow Implementation by Yixuan Li. Chainer Implementation by Toshinori Hanya. Tensorflow Implementation by Laurent Mazare. Chainer Implementation by Yasunori Kudo.
REFERENCES • Kaiming He, et al. "Deep residual learning for image recognition" CVPR 2016 • Chen-Yu Lee, et al. "Deeply-supervised nets" AISTATS 2015 • Gao Huang, et al. "Deep networks with stochastic depth" ECCV 2016 • Gao Huang, et al. "Multi-Scale Dense Convolutional Networks for Efficient Prediction" arXiv preprint arXiv:1703.09844 (2017) • Geoff Pleiss, et al. "Memory-Efficient Implementation of DenseNets”, arXiv preprint arXiv: 1707.06990 (2017)
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.