
CSE 120 File System Interface What the user/programmer sees File - PowerPoint PPT Presentation
Overview CSE 120 File System Interface What the user/programmer sees File System Implementation How it works Summer, 2006 Day 9 File Systems Instructor: Neil Rhodes 2 What is a File? Typical Filesystem Named collection of related
Overview CSE 120 File System Interface � What the user/programmer sees File System Implementation � How it works Summer, 2006 Day 9 File Systems Instructor: Neil Rhodes 2 What is a File? Typical Filesystem Named collection of related information stored in secondary Unix/Windows model: storage � Hierarchical namespace � Smallest allotment of logical secondary storage Long-term storage � create/open/close/read/write/seek � Must survive process termination (and system reboot!) � File is a single collection of bytes 3 4
File Metadata Other Possibilities File as a database Not the data in the file, but data about the file � Records with named keys, types, and values � Owner � Group – Example: Apple Newton � Indexing on various keys provided by file system � Permissions – For example, “find all records whose age > 19” � Name � Creation date File as array of data chunks � Palm OS, for example: � Modification date � Last access date – Records have attributes - Modified (Dirty) � Type - Unique ID � Application Creator - Category � Icon - Deleted � Size Files with structure beyond sequence of bytes � Maximum size � Vax VMS: � Locked – text files: sequence of lines of data � Hidden – Binary files: sequence of bytes � etc. Files with more than one stream (fork) of data � Mac OS with resource fork and data fork � NTFS/HFS+: multiple streams of data in a given file 5 6 File Types Links File extension Two possibilities � Examples: .c, .h, .doc,.bmp � Symbolic link. A file “foo” has a reference to file “bar”. If bar is deleted, � Enforced by OS (uses extension to determine what file to run) using “foo” gives an error � Hard link. “foo” and “bar” both refer to the same file. If either is deleted, � Or, used as convention (Unix) the other still refers to it Magic Number � Various file have different magic numbers towards the beginning. – On Linux, see /usr/share/magic for long list of magic numbers for various files Stored file type � Classic Mac OS, for example. File type and creator 7 8
File Namespace File Operations One-level Common � Create � Delete Two-levels � Open � Often, one per user � Close � Read Hierarchical � Write � Tree � Seek � Get attributes � Set attributes Less common � Rename � Append 9 10 Directory Operations Abstraction of the Disk Common Sequence of equal-sized blocks: 0..n-1 � Create � Delete Operations block 0 � OpenDir � Read block i � CloseDir � Write block i block 1 � ReadDir � Rename block 2 Less Common block 3 � Link … � Unlink block n-3 block n-2 block n-1 11 12
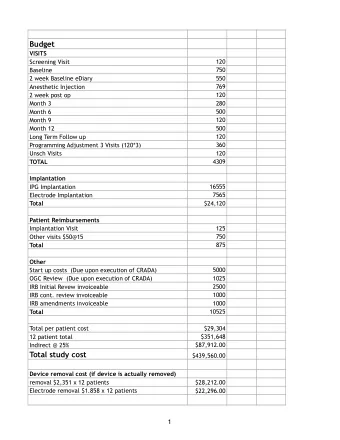
Information Kept About Open Files File System Metadata Everything except the contents of the files System-wide open-file table � What blocks are free � Contains entry for each open file (attributes, disk block locations, etc.) � What blocks are used Per-process open-file table � Which blocks are used for which files � Each entry contains: � Directory structure – Reference to system-wide open file table entry � Names, attributes, etc. – Access mode – Current location in the file 13 14 Finding the Blocks of a File Finding the Blocks of a File Contiguous: all blocks are adjacent index-node ( i-node ) � Pros: extremely fast to read � Keep data structure for each file, stored in disk block(s). � Cons: must specify max size when creating the file. External – Pointers to disk blocks. If too big, use 1 pointer as single-indirect, 1 as double, 1 a s triple. fragmentation � Example: CD-ROM – inode table contains location of each inode (stored on disk, but cached in mem). File File File � Pros: only in memory while the disk is open block 0 block 1 block 2 Linked List Attributes � Pros: no external fragmentation Phys block 4 Phys block 0 Phys block 3 � Cons: – slow to get to block n 3 – Uses data in block (no longer a power of two) External Linked List � Pros: All data in blocks available to user/program � Cons: Linked list table must be in memory – 20GB disk 1KB block size -> 20,000,000 blocks -> -1 table of size 60-80MB Extents 0 � Allocate groups of contiguous blocks i-node – For each one, keep start and number block size: 1024 bytes. Max file size: 1024*(10+256+256 2 +256 3 ) > 16GB 15 16
Keeping Track of Free Space Implementing Directories Linked list of disk blocks Keep name and attributes in fixed-size structure � Rather than storing one free block number per disk, store as many as name attributes contents will fit – Pros: little memory usage a.out attributes first block – Cons: disk access to allocate main.c attributes first block usr attributes first block Bitmap � 1-bit per disk block. Keep only name and inode (/usr/include/stdio.h) � Pros: attributes attributes attributes – Quick to access 56 77 83 – Easy to allocate contiguous blocks � Cons: inode 36 inode 33 root inode 2 – Fair amount of memory usage - 16GB disk, 1KB blocks -> 2 24 bits -> 2 21 bytes -> 2MB . 2 . 36 . 33 – Slow to find a free block if there aren’t many free blocks .. 2 .. 36 .. 2 bin 52 stdio.h 52 usr 36 include 33 limits.h 33 dev 65 local 78 block 56 block 77 block 83 17 18 Implementing Links Caching Disk access is slow Soft link (symbolic link) � Keep cache of recently used disk blocks � Contents of data block is name of file linked to LRU is good choice, except: � What about filesystem metadata? (Filesystem consistency) – If we corrupt a disk block used for a file, the file is corrupt – If we corrupt a disk block used for filesystem metadata, the filesystem is corrupt � Write-through cache for filesystem metadata blocks – inodes – directory blocks Hard link (multiple directory entries point at same inode) – free block lists � Count of links in inode What about cached written user data � When removing an entry from a directory, decrement the inode link � How long to keep cached? count � Unix approach – If zero, free inode and blocks associated with inode – sync daemon calls sync (flushes cache) every 30 seconds – Process can call sync directly 19 20
Recommend


















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.