
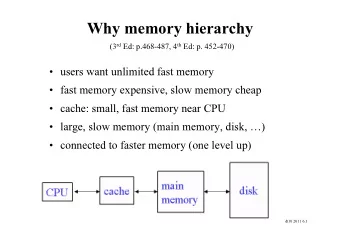
CS 6354: Memory Hierarchy III for ( int i = 0; i < I; ++i) { 5 - PowerPoint PPT Presentation
CS 6354: Memory Hierarchy III for ( int i = 0; i < I; ++i) { 5 September 2016 Goto Fig. 4 3 } } } A[i * J + j] * B[j * K + k]; C[i * K + k] += for ( int j = 0; j < J; ++j) { for ( int k = 0; k < K; ++k) { 4 Nave (2) } } }
CS 6354: Memory Hierarchy III for ( int i = 0; i < I; ++i) { 5 September 2016 Goto Fig. 4 3 } } } A[i * J + j] * B[j * K + k]; C[i * K + k] += for ( int j = 0; j < J; ++j) { for ( int k = 0; k < K; ++k) { 4 Naïve (2) } } } A[i * J + j] * B[j * K + k]; C[i * K + k] += for ( int k = 0; k < K; ++k) { for ( int j = 0; j < J; ++j) { for ( int i = 0; i < I; ++i) { Naïve (1) 2 1 ACM Transactions on Mathematical Software, Vol. 34, No. 3, Article 12, Publication date: May 2008. 12:6 gepp var1 gebp Fig. 8 ✲ • +:= +:= ✲ gemm var1 K. Goto and R. A. van de Geijn +:= ❅ gepp var2 gepb ✲ ✲ Fig. 10 Fig. 4. ✲ +:= +:= Layered approach to implementing GEMM . gepb gemp var1 Fig. 11 ✲ +:= +:= ✲ gemm var2 ✲ � +:= +:= ❅ gemp var2 gepdot ✲ ✲ +:= +:= gepm var2 gepdot ✲ +:= +:= ✲ ✲ gemm var3 � +:= ❅ gepm var1 gebp ✲ Fig. 9 ✲ +:= +:=
The Inner Loop 6 operations Modern CPUs do other things during memory Theme: Overlap 7 Second) = 7.2 Gfmop/s (Giga Floating Point Operation Per 3.6 GHz: 7.2B adds or multiplies per second This CPU: 2 double adds or multiplies per cycle Theoretical maximum performance 8 5 GFLOP/s 100 7 6 80 dgemm Kernel 5 Pack A Pack B 60 Percentage GFlops 4 3 40 2 20 1 0 0 0 500 1000 1500 2000 m = n = k 100 Fig. 5. The algorithm that corresponds to the path through Figure 4 that always takes the top 7 branch expressed as a triple-nested loop. , we focus on that algorithm: 6 80 dgemm Kernel 5 Pack A n r k c Pack B 60 Percentage GFlops 4 3 40 m c 2 + : = 20 1 0 0 0 500 1000 1500 2000 k (m = n = 2000) Fig. 14. Pentium4 Prescott (3.6 GHz). king ideal: no added latency
Cache/Register Blocking … 806 805 804 803 802 801 800 799 561 808 560 559 558 557 556 555 554 minimize data movements 807 809 551 unused parts of cache blocks busy computation The Balanced System 11 less of relevant matrix in each page nearby matrix entries map to same set confmict misses if close-to-power-of-two irrelevant 310 in same block as 309 1549 810 … 1300 1301 1302 1303 1304 1305 1306 1307 1308 1309 1310 1311 1299 … 1050 1051 1052 1053 1054 1055 1056 1057 1058 1059 1060 1061 1049 … 811 552 553 550 301 … by reordering computation best orders — all computations within ‘block’ 9 Load into Cache? 549 10 Why packing? 250 x ??? matrix at memory address 300, working on fjrst part: 300 12 302 311 308 303 310 309 … 307 306 305 304 Algorithm: C := gebp ( A , B , C ) n r k c m c +:= Load A into cache ( m c k c memops) for j = 0 , . . . , N − 1 Load B j into cache ( k c n r memops) Load C j into cache ( m c n r memops) +:= ( C j := AB j + C j ) Store C j into memory ( m c n r memops) endfor Fig. 7. Basic implementation of GEBP . much of the cache as possible and should be roughly square n r ≥ R comp 2 R load C = AB overlap loads (at rate R load ) from L2 with enough of C , B ( n r ) in L1/registers to keep FPU extra TLB misses
TLB capacities virtual 0x00448aaa 0x0044a999 0x0044c777 etc. 13 Hierarchical page tables Diagram: Wikimedia / RokerHRO 0x00444ccc 14 Large pages (1) Diagram: Intel 64 and IA-32 Architectures Software Developer’s Manual, Volume 3A 15 Large pages (2) Diagram: Intel 64 and IA-32 Architectures Software Developer’s Manual, Volume 3A 0x00446bbb 16 e.g. 0x024 0x01f 0x00448 0x0044a 0x01c 0x00446 worst case: each entry only useful for 1 byte of data: TLB (cache of page table) 0x007 physical physical (machine) address virtual (program) address 0x00444 Linear address: 63 56 55 48 47 40 39 32 31 24 23 16 15 8 7 0 sign extended virtual page # page ofgset 9 9 9 9 12 PML4 table page-directory- pointer table page directory page table ... ... ... ... 4K memory page ... physical page # page ofgset PML4 entry PDP entry 64 bit PD ... entry 64 bit PT ... entry ... ... 40* ... CR3 *) 40 bits aligned to a 4-KByte boundary reach: page size × # entries = 16K with 4K pages
Data TLB reach on my laptop Intuition: why no locality …unless value actually needed modern fast CPUs: keep executing instructions What happens on a cache miss? Preview: Out-of-order 19 Proof of locality? 18 Amazon recommendation network from Lehmann and Kottler, “Visualizing Large and Clustered Networks” 17 4KB pages: 256 KB — smaller than L3 cache 4 GB 4 pages = 1GB pages: 64 MB 32 pages = 2M pages: 64 pages = 256 KB 20
Preview: Reorder bufger holds pending instructions used to make computation appear in-order (more later in the course) key feature here: need to have enough room for every instruction run out-of-order 21 Non-Uniform Memory Access Some memory closer to one core than another 22 Memory Request Limits 23 Page table overhead 24 Exists within a socket (single chip)
Pointer chasing (more later in the course) Conditions 27 “In practice, the variation between threads is modest…” cache misses) could execute instructions quickly to increase IPM.” a high efgective MLP while the other thread (unencumbered by “One thread could generate most of the cache misses sustaining Beamer’s theory about SMT 26 Same machinary as out-of-order void **pointer = /* initialize array */ ; Run a difgerent thread! What happens on cache miss? Preview: SMT 25 } pointer = *pointer; for ( int i = 0; i < MAX_ITER; ++i) { 28 Needs: extra set of registers
Where to do graph processing? done Note on Paper Reviews (1) Make it clear where you answer each part You can copy-and-paste the questions Better to explain one well (including evidence) than three poorly What experiments showed, not what experiments were 31 Extreme: Cray XMT Note on Paper Reviews (2) Evidence: not just that there were experiments What kind of experiments? How big is the efgect? Weakness/improvement: don’t be afraid Often the discussion identifjes these for you 30 cycles/read array size (B) in random order no data cache 100s of outstanding memory acccesses (“memory-level parallelism”) 29 Homework 1 Example: measure sizes of each data/unifjed cache Benchmark: speed of accessing array of varying size 32 10 2 10 1 10 3 10 4 10 5 10 6 10 7 Only need one signifjcant insight Your insight should be a result
Next time “Performance from architecture: comparing a RISC and CISC with similar hardware organization” CISC (VAX) v RISC (MIPS) both pipelined microinstructions to implement complex instructions ”The RISC V Instruction Set Manual: Volume I: only motivation (chapter 1 only) for a recent ISA design 33 User-Level ISA”, Chapter 1 (including commentary)
Recommend
















![arXiv:1606.06235v2 [cs.DS] 4 Feb 2017 Abstract We develop new methods based on graph motifs for](https://c.sambuz.com/798399/arxiv-1606-06235v2-cs-ds-4-feb-2017-s.webp)





More recommend
Explore More Topics
Stay informed with curated content and fresh updates.