
CS 6354: Branch Prediction (cont) / Multiple Issue blt $t0, 10000, - PowerPoint PPT Presentation
CS 6354: Branch Prediction (cont) / Multiple Issue blt $t0, 10000, loop addiu $t0, $t0, 1 ... loop : } ... for ( int i = 0; i < 10000; i += 1) { Why bimodal: loops 3 unroll loops to have more to fjt in delays can be more than
CS 6354: Branch Prediction (con’t) / Multiple Issue blt $t0, 10000, loop addiu $t0, $t0, 1 ... loop : } ... for ( int i = 0; i < 10000; i += 1) { Why bimodal: loops 3 unroll loops to have more to fjt in delays can be more than loads/stores track required delays between instructions fjnd all dependencies Last time: scheduling to avoid stalls 2 don’t start ‘execute’ of sub before ‘execute’ of add 14 September 2016 1 Last time: forwarding/stalls add $a0, $a2, $a3 ; zero or more instructions sub $t0, $a0, $a1 sub depends on calcuation from add No forwarding: get $a0 via register fjle ‘write back’ of add completes before ‘decode’ of sub Forwarding: transfer values via pipeline registers instead ‘execute’ of add completes before ‘execute’ of sub Stall: Delay instruction 4 li $t0, 0 ; i < − 0 software pipelining: even across loop iterations
Why bimodal: non-loops … counter before iteration } } if (i == 3) break ; ... for ( int i = 0;; ++i) { for ( int j = 0; j < 10000; ++j) { Saturating counters (2) 7 … … … yes correct? taken 2 (MAX) 6 yes taken 1 5 no taken 2 (MAX) 4 yes taken 2 (MAX) prediction 0 yes 0 … … … … yes not taken -1 (MIN) 6 yes not taken -1 (MIN) 5 no not taken 4 0? yes not taken -1 (MIN) 3 yes not taken -1 (MIN) 2 yes not taken -1 (MIN) 1 — — 3 taken char *data = malloc(...); 1 yes 4 yes taken yes 3 yes taken yes 2 yes taken yes — no — — 0 correct? prediction last taken iteration } } ... for ( int j = 0; j < 10000; ++j) { Why more than 1-bit? 5 if (!data) handleOutOfMemory(); taken 5 2 (MAX) no 2 yes taken 1 1 — — 0? 0 correct? prediction counter before iteration } } ... yes not taken no 6 yes taken … … … … 6 Saturating counters (1) for ( int j = 0; j < 10000; ++j) { 8 for ( int i = 0; i < 4; ++i) { for ( int i = 0; i < 4; ++i) {
Local history: loops N Global history identifes branches 11 N …T T …N prediction result for prior branches if (x <= 0) ... if (x >= 0) ... Global history 10 Local history predictor 9 NNNTN for ( int j = 0; j < 10000; ++j) { N NNTNN T NTNNN N TNNNT prediction prior fjve results construct table: NNNTNNNTNNNT … observation: taken/not-taken pattern is } } 12 for ( int i = 0; i < 4; ++i) {
Global history predictor 13 Combining local and global hash together history and branch location 14 Combining generally branch predictor predictor counter per branch: increment when fjrst predictor is better decrement when fjrst predictor is worse use fjrst predictor if non-negative 2-bit saturating — predictor gets ‘second chance’ 15 The experiments 16
Return address stack } 98 … … … loop count table for ( int i = 0; i < 128; ++i) { ... 18 Predicting function call return addresses Speculation: More register value prediction will two loads/stores alias each other? … 19 Very Long Instruction Word ADD R1, R2, R3 MOV R4, 10(R5) bundle of instructions issued and execute together 128 0x040102 current # last # iters baz saved registers baz return address bar saved registers bar return address foo local variables foo saved registers foo return address foo saved registers stack in memory baz return address bar return address foo return address shadow stack in CPU registers 17 Speculation: Loop termination prediction Predicting loops with fjxed iteration counts (times since change of branch result) address 20 Solution: stack in processor registers Solution: record last iteration count ADD R1, R2, R3 short MUL R6, R7, R8 long
VLIW Pipeline fancy register fjle of VLIW Called EPIC — tries to address some shortcomings VLIW-derived processor Itanium 21 specialize slots more specialize slots fancy cache?? Fetch 1. Slot 1 — Usually Memory or Integer Longer instruction word pipeline Write Back Int/Mul ALU 2 Int/Mul ALU 1 Read Regs Fetch Write Back Memory Intel designed ISA, introduced c. 2001 2. Slot 2 — Usually Memory or Integer or Floating Point Read Regs Bundles of 24+ ‘instructions’: put a no-op in that slot Don’t want, e.g., a memory access? ?? register-register movements 1 very fancy conditional jump 32 register accesses 8 memory accesses 8 64-bit integer/fmoating point operations 8 32-bit integer operations ELI-512 3. Slot 3 — Usually Integer or Floating Point or Branch 22 ... { .mmi ; Bundle of Memory/Memory/Integer } LDFD f89 = [r16], r21 LDFD f83 = [r35], r21 { .mmf ; Bundle of Memory/Memory/Float Example assembly: Fetch Address ALU Fetch Memory Read Regs Fetch Write Back Memory Execute (ALU) Read Regs Fetch Write Back Execute (ALU) Write Back Read Regs Fetch time Normal RISC-like pipeline Write Back Memory Execute (ALU) Read Regs Execute (ALU) Memory Write Back Fetch — Simple ALU Read Regs Fetch time Normal RISC-like pipeline Write Back Memory Execute (ALU) Read Regs VLIW Pipeline 21 specialize slots more specialize slots fancy cache?? fancy register fjle Fetch Longer instruction word pipeline 23 “Bundles” of 3 instructions: ; f83 < − MEM[r35+r21] ; f89 < − MEM[r16+r21] FMA f11 = f43, f91, f11 ; f11 < − f43 * f91 + f11
ELI-512 16 modules Write Back Longer instruction word pipeline Fetch fancy register fjle fancy cache?? specialize slots specialize slots more 24 ELI-512: Multiple Register Banks 25 Bundles of 24+ ‘instructions’: ELI-512 Bundles of 24+ ‘instructions’: 8 32-bit integer operations 8 64-bit integer/fmoating point operations 8 memory accesses 32 register accesses 1 very fancy conditional jump ?? register-register movements Don’t want, e.g., a memory access? put a no-op in that slot Read Regs Fetch Write Back Fetch 8 32-bit integer operations 8 64-bit integer/fmoating point operations 8 memory accesses 32 register accesses 1 very fancy conditional jump ?? register-register movements Don’t want, e.g., a memory access? put a no-op in that slot 23 VLIW Pipeline 26 Memory Read Regs Execute (ALU) Memory Write Back Normal RISC-like pipeline time Fetch Read Regs Write Back Fetch Read Regs each has own registers explicitly move values between modules
VLIW Pipeline Compiler challenges specialize slots specialize slots more 27 ELI-512: Multiple Memory Banks 16 modules 28 need 24+ indepedent instructions to fjll bundle Fetch not found in natural code 29 Solution for loops Unroll it! How do we know this is safe (e.g. no array overlap)? Compiler does fancy equation solving Doesn’t work? Can’t generate good code. fancy cache?? fancy register fjle Fetch Write Back Read Regs Execute (ALU) Memory Write Back Normal RISC-like pipeline time Fetch Read Regs Fetch Longer instruction word pipeline Read Regs Memory Write Back Fetch Read Regs Write Back 30 each M module has own memory explicitly choose which module to use
Solution for non-loops } newB = b * c; a += 1; /* common case: */ original code } } else { b *= c; if (x <= 0) { if (y > 0) { a += 1; if (x > 0) { Trace scheduling 33 wrong answer if compiler doesn’t schedule properly /* compensation code: */ newB = b; ELI-512 and TRACE had no “interlocks” 1st bundle: one cycle common case is conditional jump subtract multiply add conditional jump newD = d reason for fancy guess x > 0 and y > 0 } newD = d; newB = b; } else if (y <= 0) { Guess most common branches no forwarding — longer delays Trace scheduling: Interlocks? a[i+0] *= 2; a2 = a[i+2]; /* bundle 1: */ loop: unroll x 3 } a[i+2] *= 2; a[i+1] *= 2; for (i = 0; i < 15; i += 3) { 32 original code } a[i] *= 2; for (i = 0; i < 15; i += 1) { Loop unroling for VLIW 31 Generate that code a0 *= 2; 34 // loaded last iter a1 *= 2; unroll x 3 + schedule if (nextI < 15) goto loop; i = nextI; a[i+2] = a2; /* bundle 4: */ a2 *= 2; a1 = a[nextI+1]; a0 = a[nextI+0]; // load for next iter /* bundle 3: */ nextI = i + 3; a[i+1] = a1; a[i+0] = a0; /* bundle 2: */ Then generate compensation code for wrong guesses newD = d − e; d − = e; a − = 1; a − = 1; Forwarding logic would be too complex/slow
Assisting compilers chk.a : branch if that address was written since load The Itanium story 37 Itanium solution: prefetch, speculative loads will load use cache or take a long time? compilers don’t know enough to schedule otherwise, CPU can start at same time assembler sets stop bit if dependency Itanium solution: bundles have ‘stop’ bit bet on good compilers VLIW problems 36 ld.a : load value, watch for stores to address many registers Itanium: aliasing detection Itanium: explicit speculative loads Compiler speculation 35 avoid expensive branches for short fjxup code Itanium: every instruction can be conditional conditional instructions makes unrolling + rescheduling loops easier Itanium: 128 integer, 128 fmoat, 128 condition 38 Trace schedule ≈ compiler branch prediction ld.s : load value only if valid address e.g. add if condition register true recompile to increase bundle size
Recommend







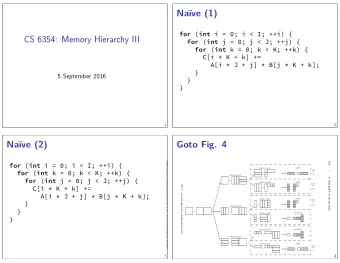

![CS 6354: SMT sum2 += array[i]; thread_one_func( int offset) { for ( int i = 0; i < N / 2; ++i)](https://c.sambuz.com/1018376/cs-6354-smt-s.webp)












More recommend
Explore More Topics
Stay informed with curated content and fresh updates.