
COSC 5351 Advanced Computer Architecture Slides modified from - PowerPoint PPT Presentation
COSC 5351 Advanced Computer Architecture Slides modified from Hennessy CS252 course slides 11 Advanced Cache Optimizations Memory Technology and DRAM optimizations Virtual Machines Xen VM: Design and Performance AMD Opteron
COSC 5351 Advanced Computer Architecture Slides modified from Hennessy CS252 course slides
11 Advanced Cache Optimizations Memory Technology and DRAM optimizations Virtual Machines Xen VM: Design and Performance AMD Opteron Memory Hierarchy Opteron Memory Performance vs. Pentium 4 Fallacies and Pitfalls Conclusion COSC5351 Advanced Computer Architecture 10/26/2011 2
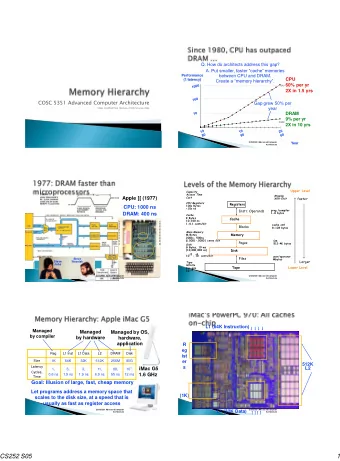
100,000 10,000 Performance 1,000 Processor Processor-Memory Performance Gap 100 Growing 10 Memory 1 1980 1985 1990 1995 2000 2005 2010 Year 10/26/2011 3
How does a memory hierarchy improve performance? What costs are associated with a memory access? COSC5351 Advanced Computer Architecture 10/26/2011 4
COSC5351 Advanced Computer Architecture 10/26/2011 5
VM is 2 64 64 or 16E 6Eb COSC5351 Advanced Computer Architecture 10/26/2011 6
Physic ical al Mem em is 2 41 41 or 2Tb Tb COSC5351 Advanced Computer Architecture 10/26/2011 7
Page e size e is 2 13 13 or 8Kb COSC5351 Advanced Computer Architecture 10/26/2011 8
2 13 13 (8Kb) b) direct ect mapped pped L1 lines nes with th 64b 4b blocks ocks COSC5351 Advanced Computer Architecture 10/26/2011 9
2 8 TLB B entries tries direct ect map apped ped in th this s case se (often ten fully ly assoc soc) Compare ompare 43-bit bit tag with th the tag in the e appropria ropriate te TLB B slot ot COSC5351 Advanced Computer Architecture 10/26/2011 10
If in TLB LB you u chec heck k the e L1 cache ache tag in the e appropr ropria iate e line ne to se if in L1 COSC5351 Advanced Computer Architecture 10/26/2011 11
If f not in L1, , build ld PA with th 28bit 8bit TLB B data a + page e offset set. Use e this is to acc cces ess s L2 cache che COSC5351 Advanced Computer Architecture 10/26/2011 12
2 22 22 (4Mb) Mb) direct ect mapped pped L2 lines nes with th 64b 4b blocks ocks COSC5351 Advanced Computer Architecture 10/26/2011 13
Compare ompare the L2 tag to see if actual tually ly in L2 cach ache COSC5351 Advanced Computer Architecture 10/26/2011 14
Reducing hit time 1. Giving Reads Priority over Writes • E.g., Read completes before earlier writes in write buffer 2. Avoiding Address Translation during Cache Indexing (use page offset) Reducing Miss Penalty 3. Multilevel Caches (avoid larger vs faster) Reducing Miss Rate 4. Larger Block size (Compulsory misses) 5. Larger Cache size (Capacity misses) 6. Higher Associativity (Conflict misses) Do these e always ys improve rove perform ormanc ance? COSC5351 Advanced Computer Architecture 10/26/2011 15
Reducing Miss Penalty Reducing hit time 7. Critical word first 1. Small and simple 8. Merging write buffers caches 2. Way prediction Reducing Miss Rate 3. Trace caches 9. Compiler optimizations Increasing cache Reducing miss penalty bandwidth or miss rate via 4. Pipelined caches parallelism 10. Hardware prefetching 5. Multibanked caches 11. Compiler prefetching 6. Nonblocking caches COSC5351 Advanced Computer Architecture 10/26/2011 16
Index tag memory and then compare takes time Small cache can help hit time since smaller memory takes less time to index ◦ E.g., L1 caches same size for 3 generations of AMD microprocessors: K6, Athlon, and Opteron ◦ Also L2 cache small enough to fit on chip with the processor avoids time penalty of going off chip Simple direct mapping ◦ Can overlap tag check with data transmission since no choice Access time estimate for 90 nm using CACTI model 4.0 ◦ Median ratios of access time relative to the direct-mapped caches are 1.32, 1.39, and 1.43 for 2-way, 4-way, and 8-way caches 2.50 Access time (ns) 1-way 2-way 4-way 8-way 2.00 1.50 1.00 0.50 - 16 KB 32 KB 64 KB 128 KB 256 KB 512 KB 1 MB Cache size 10/26/2011 17
Assume 2-way hit time is 1.1x faster than 4- way Miss rate will be .049 and .044 (from C.8) Hit is 1 clock cycle, miss penalty is 10 clocks (to go to L2 and it hits) Avg Mem Acces = Hit time + Miss Rate X Miss pen 2-way Avg Mem Acces = 1 + .049*10 = 1.49 Elapse sed time me shou ould ld be abou out t same me 4-way 9*1.1 .1 = 9.9 ~ 10 Avg Mem Acces = 1.1 + .044*9 = 1.50 This is means ns the cloc ock woul uld be slow ower er thoug ugh h so ever eryth thing ng else se slowe lower. r. COSC5351 Advanced Computer Architecture 10/26/2011 18
How to combine fast hit time of Direct Mapped and have the lower conflict misses of 2-way SA cache? Way prediction: keep extra bits in cache to predict the “way,” or block within the set, of next cache access. ◦ Multiplexor is set early to select desired block, only 1 tag comparison performed that clock cycle in parallel with reading the cache data ◦ Miss 1 st check other blocks for matches in next clock cycle Hit Time Miss Penalty Way-Miss Hit Time Accuracy 85% (seen 97.9%) Drawback: CPU pipeline is harder if variable hit times ◦ Used for instruction caches (speculative) vs. data caches COSC5351 Advanced Computer Architecture 10/26/2011 19
Find more instruction level parallelism? How avoid translation from x86 to microops? Trace cache in Pentium 4 Dynamic traces of the executed instructions vs. static sequences of 1. instructions as determined by layout in memory Built-in branch predictor ◦ Cache the micro-ops vs. x86 instructions 2. Decode/translate from x86 to micro-ops on trace cache miss ◦ + 1. better utilize long blocks (don’t exit in middle of block, don’t enter at label in middle of block) 1. complicated address mapping since addresses no - longer aligned to power-of-2 multiples of word size - 1. instructions may appear in multiple dynamic traces due to different branch outcomes decreasing cache space usage efficiency COSC5351 Advanced Computer Architecture 10/26/2011 20
Pipeline cache access ◦ Allows higher clock ◦ Gives higher bandwidth ◦ But multiple clocks for a hit => higher latency Cycles to access instruction cache Example: 1: Pentium 2: Pentium Pro through Pentium III 4: Pentium 4 => greater penalty on mispredicted branches => more cycles between load issue & data use + Easier to have higher associativity COSC5351 Advanced Computer Architecture 10/26/2011 21
Non-blocking cache or lockup-free cache allow data cache to continue to supply cache hits during a miss ◦ requires F/E bits on registers or out-of-order execution ◦ requires multi-bank memories “ hit under miss ” reduces the effective miss penalty by working during miss vs. ignoring CPU requests “ hit under multiple miss ” or “ miss under miss ” may further lower the effective miss penalty by overlapping multiple misses ◦ Significantly increases the complexity of the cache controller as there can be multiple outstanding memory accesses ◦ Requires muliple memory banks (otherwise cannot support) ◦ Penium Pro allows 4 outstanding memory misses COSC5351 Advanced Computer Architecture 10/26/2011 22
Hit Under i Misses 2 1.8 1.6 1.4 0->1 0->1 1.2 1->2 1->2 1 2->64 2->64 0.8 Base Base 0.6 0.4 “Hit under n Misses” 0.2 0 espresso doduc ear nasa7 ora compress wave5 eqntott xlisp fpppp su2cor hydro2d spice2g6 tomcatv alvinn mdljsp2 swm256 mdljdp2 Integer Floating Point FP programs on average: AMAT= 0.68 -> 0.52 -> 0.34 -> 0.26 Int programs on average: AMAT= 0.24 -> 0.20 -> 0.19 -> 0.19 8 KB Data Cache, Direct Mapped, 32B block, 16 cycle miss, SPEC 92 COSC5351 Advanced Computer Architecture 10/26/2011 23
FP programs on average: AMAT= 0.68 -> 0.52 -> 0.34 -> 0.26 Int programs on average: AMAT= 0.24 -> 0.20 -> 0.19 -> 0.19 8 KB Data Cache, Direct Mapped, 32B block, 16 cycle miss, SPEC 92 COSC5351 Advanced Computer Architecture 10/26/2011 24
Previous study old with smaller cache New study: 32KL1 4cal, 256KBL2 10CAL, L3 2M 36CAL Li, Chen, Brockman, Jouppi (2011) ◦ COSC5351 Advanced Computer Architecture 10/26/2011 25
Rather than treat the cache as a single monolithic block, divide into independent banks that can support simultaneous access ◦ E.g.,T1 (“Niagara”) and Arm Cortex-A8 have 4 L2 banks ◦ Intel Core i7 has four L1 banks, L2 has 8. Banking works best when accesses spread across banks mapping of addresses to banks affects behavior of memory system Simple mapping that works well is sequential interleaving ◦ Spread block addresses sequentially across banks ◦ E,g, if there 4 banks, Bank 0 has all blocks whose address modulo 4 is 0; bank 1 has all blocks whose address modulo 4 is 1; … COSC5351 Advanced Computer Architecture 10/26/2011 26
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.