
Challenges in Organizing a Metagenomics Benchmarking Challenge - PowerPoint PPT Presentation
Challenges in Organizing a Metagenomics Benchmarking Challenge Alice C. McHardy Department for Computational Biology of Infection Research Helmholtz Centre for Infection Research and the CAMI Initiative Critical Assessment of Metagenome
Challenges in Organizing a Metagenomics Benchmarking Challenge Alice C. McHardy Department for Computational Biology of Infection Research Helmholtz Centre for Infection Research and the CAMI Initiative
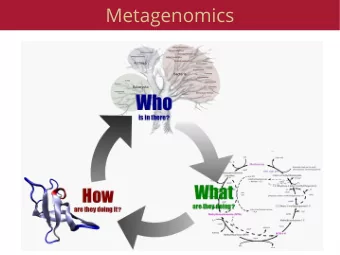
Critical Assessment of Metagenome Interpretation Tool development for shotgun metagenome data sets is a very active area: Assembly, (tax.) binning, taxonomic profiling Method papers present evaluations using many different metrics, simulated data sets (snapshots) and are difficult to compare It is unclear to everyone which tools are most suitable for a particular task and for particular data sets Comparative benchmarking requires extensive resources and there are pitfalls Towards a comprehensive, independent and unbiased evaluation of computational metagenome analysis methods
First CAMI challenge Benchmark assembly, (tax.) binning and taxonomic profiling software Extensive, high-quality benchmark data sets from unpublished data Publication with participants and data contributors Aims Standards Overview of tools and use cases Indicate promising directions for tool development Suggestions for experimental design Facilitate future benchmarking Contest opened in 2015
The most important challenge: Getting developers and the broader community involved • Spreading the news • Data sets must be „exciting“, reflect what people would like to see • Should facilitate benchmarking to developers • Tool results must be reproducible Page 10 |
IKey principles All design decisions (data sets, evaluation measures and principles) should involve the community Data sets should be as realistic as possible Evaluation measures should be informative to developers and understandable also by applied community Reproducibility (data generation, tools, evaluation) Participants should not see any of the data before Evaluation using anonymized tool names as long as possible
„Spreading the word“ & Community Involvement Google+ community ISME Roundtable, Hackathons & workshops Announcements in blogs & tweets www.cami-challenge.org with newsletter Page 12 |
Challenge Data sets – Design principles Challenging Common experimental setups and community types Unpublished data Strain-level variation Different taxonomic distances to sequenced genomes (deep branchers included) State-of-the-art sequencing technologies Non-bacterial sequences Fully reproducible with CAMI benchmark data set generation pipeline Provide freely accessible toy data sets upfront Seite 13 |
CAMI Datasets CAMI_medium CAMI_high CAMI_low (differential (time series) abundance) 1 sample 2 samples 5 samples 15 GBp 40 GBp 75 GBp 2 x150 bp 2 x150 bp 2 x150 bp Insert size: Insert sizes: Insert size: 270 bp 270 bp & 5kbp 270 bp Datasets simulated from ~700 unpublished microbial genomes and additional sequence material
Timeline first CAMI Challenge
CAMI participants Early 2015: Already >40 registered participants (currently 128) https://data.cami-challenge.org
Reproducibility and Standardization Standard formats for binning and profiling Standard interfaces for tool execution Bioboxes (docker containers) for tools and metrics Currently 25 tools in bioboxes – semi- automatic benchmarking in future challenges Challenge organization and benchmarking framework Barton et al ., Gigascience 2015
Further Challenges • Challenge Design Repeat with current setup, or new challenge setup (eg using real • samples)? Define challenge questions & performance metrics very specifically • from the start or leave flexibility? Include new tool categories (predict pathogens, antibiotic • resistance genes)? Measure runtimes • • Contest implementation (communication is an issue if geograpically distributed team) • Challenge data set generation – get data generators onboard, not many people routinely isolate hundreds of microbes for sequencing Seite 18 |
Alexander Sczyrba Thomas Rattei Peter Belmann Dmitri Turaev Liren Huang Isaak Newton Institute for Mathematical Sciences Alice McHardy Johannes Dröge, Ivan Gregor Peter Hofmann, Jessika Fiedler Stephan Majda, Eik Dahms, Stefan Janssen, Adrian Fritz, Tanja Woyke Andreas Bremges, Ruben Garrido- Nikos Kyrpides Tue Sparholt Oter Hans-Peter Klenk Eddy Rubin Jørgensen, Lars Hestbjerg Hansen Søren J Sørensen Paul Schulze-Lefert, Yang Bai Aaron Darling Matthew DeMaere Mihai Pop, Chris Hill David Koslicki Phil Blood Julia Vorholt Michael Barton
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.