
Cache design overview ANY cache can be viewed as k-way associative. - PowerPoint PPT Presentation
Cache design overview ANY cache can be viewed as k-way associative. What are the pros and cons of each? Fully associative: k = N/B IC220 Caching 2: Memory Hierarchy (more from Chapter 5 - specifically 5.7, 5.8) 4-way set associative,
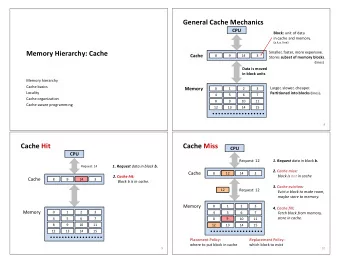
Cache design overview ANY cache can be viewed as k-way associative. What are the pros and cons of each? • Fully associative: k = N/B IC220 Caching 2: Memory Hierarchy (more from Chapter 5 - specifically 5.7, 5.8) • 4-way set associative, k = 4 • Direct-mapped, k = 1 1 2 Improving Cache Performance Cache performance key tradeoff Inherent conflict: Remember key metrics: Miss Rate, Hit Time, Miss Penalty What happens if we: HIT TIME vs MISS RATE • Increase the cache size (N)? • Increase the block size (keeping N the same)? • Increase associativity (keeping N the same)? 3 4
More hierarchy – L2 cache? Memory Hierarchy • Problem: CPUs get faster, DRAM gets bigger – Must keep hit time small (1 or 2 cycles) – But then cache must be small too (fast SRAM is expensive) – So miss rate gets higher... • Solution: Add another level of cache: – try and optimize the ____________ on the 1st level cache – try and optimize the ____________ on the 2nd level cache 5 6 Questions Split Caches • Instructions and data have different properties – May benefit from different cache organizations (block size, assoc…) • Will the miss rate of a L2 cache be higher or lower than for the L1 cache? ICache DCache (L1) (L1) L2 Cache CPU • Claim: “The register file is really the lowest level cache” L3, L4, …? What are reasons in favor and against this statement? Main memory 7 8
What does an address refer to? Virtual memory: Main idea The old way: CPU works with (fake) virtual addresses. • Address refers to a specific byte in main memory (DRAM). Operating system translates to physical addresses. • This is called a physical address. Advantages: Problems with this: CPU CPU Virtual address Physical OS Translation address New challenge: Physical address Cache Cache Memory Memory 9 10 Pages and virtual address translation Page Tables • Translation from virtual to physical pages stored in page table. • Virtual AND physical addresses divided into blocks called pages. • Typical page size is 4KiB (means 12 bits for offset) Cache Disk Memory 11 12
Pages: virtual memory blocks Address Translation Terminology: • Page faults: the data is not in memory, retrieve it from disk •Cache block – huge miss penalty (slow disk), thus •Cache miss •Cache tag • pages should be fairly •Byte offset • Replacement strategy: – can handle the faults in software instead of hardware • Writeback or write-through? 13 14 Making Address Translation Fast Virtual Memory Take-Aways • A cache for address translations: translation lookaside buffer (TLB) • CPU/programs deal with virtual addresses (virtual page number + page offset). • Translated to physical addresses (physical page # + page offset) between CPU and cache. • Memory is divided into blocks called pages, commonly 4KiB (therefore 12 bits for page offset). • Page tables, managed by the operating system for each process, store virtual->physical page number mapping, as well as that process’s permissions (read/write). • TLB is a special CPU cache for page table lookups. • Physical addresses can reside in DRAM (typical), or be stored on disk (making RAM “look” larger to CPU), or can even refer to other devices (memory-mapped I/O). Typical values: 16-512 PTEs (page table entries), miss-rate: .01% - 1% 15 16 miss-penalty: 10 – 100 cycles
Modern Systems Program Design 2D array layout • Consider this C declaration: int A[4][3] = { {10, 11, 12}, {20, 21, 22}, {30, 31, 32}, {40, 41, 42} }; • How is this array stored in memory? 17 20 Program Design for Caches – Example 1 Program Design for Caches – Example 2 • Option #1 • Why might this code be problematic? for (j = 0; j < 20; j++) int A[1024][1024]; for (i = 0; i < 200; i++) int B[1024][1024]; x[i][j] = x[i][j] + 1; for (i = 0; i < 1024; i++) for (j = 0; j < 1024; j++) • Option #2 A[i][j] += B[i][j]; for (i = 0; i < 200; i++) for (j = 0; j < 20; j++) x[i][j] = x[i][j] + 1; • How to fix it? 21 22
Concluding Remarks • Fast memories are small, large memories are slow – We really want fast, large memories – Caching gives this illusion • Principle of locality – Programs use a small part of their memory space frequently • Memory hierarchy – L1 cache ↔ L2 cache ↔ … ↔ DRAM memory ↔ disk • Memory system design is critical for multiprocessors 23
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.