Associativity of caches full associative: a block can occupy any line in the cache, regardless of its address direct map: a block has only one designated “seat” ( set ), determined by its address K -way set associative: a block has K designated “seats”, determined by its set address direct map ≡ 1-way set associative full associative ≡ ∞ -way set associative 20 / 67
An example cache organization Haswell E5-2686 level line size capacity associativity L1 64B 32KB/core 8 L2 64B 256KB/core 8 L3 64B 46MB/socket 20 21 / 67
What you want to remember about associativity avoid frequently used addresses or addresses used together “a-large-power-of-two” bytes apart; corollary: avoid having a matrix with a-large-power-of-two number of columns (a common mistake) avoid managing your memory by chunks of large-powers-of-two bytes (a common mistake) avoid experiments only with n = 2 p (a very common mistake) why? ⇒ they tend to go to the same set and “conflict misses” result 22 / 67
Conflict misses consider 8-way set associative L2 cache with 256KB (line size = 64B) 256KB/64B = 4K (= 2 12 ) lines 4K/8 = 512 (= 2 9 ) sets ⇒ given an address a , a [6:14] (9 bits) designates the set it belongs to (indexing) 15 14 6 5 0 a address within a line (2 6 = 64 bytes) index the set in the cache (among 2 9 = 512 sets) if two addresses a and b are a multiple of 2 15 (32KB) bytes apart, they go to the same set 23 / 67
Conflict misses e.g., if you have a matrix: ✞ float a[100][8192]; 1 then a[i][j] and a[i+1][j] go to the same set; ⇒ scanning a column of such a matrix will experience almost 100% cache miss a remedy is as simple as: ✞ float a[100][8192+16]; 1 24 / 67
What are in the cache? consider K -way set associative cache with capacity = C bytes and line size = Z bytes approximation 0.0 (only consider C ; ≡ Z = 1 , K = ∞ ): Cache ≈ most recently accessed C distinct addresses 25 / 67
What are in the cache? consider K -way set associative cache with capacity = C bytes and line size = Z bytes approximation 0.0 (only consider C ; ≡ Z = 1 , K = ∞ ): Cache ≈ most recently accessed C distinct addresses approximation 1.0 (only consider C and Z ; K = ∞ ): Cache ≈ most recently accessed C/Z distinct lines more pragmatically, if you typically access data larger than cache line granularity (i.e., when you touch an element, you almost certainly touch the surrounding Z bytes), forget Z ; otherwise cache ≈ most recently accessed C/Z elements 25 / 67
What are in the cache? consider K -way set associative cache with capacity = C bytes and line size = Z bytes approximation 0.0 (only consider C ; ≡ Z = 1 , K = ∞ ): Cache ≈ most recently accessed C distinct addresses approximation 1.0 (only consider C and Z ; K = ∞ ): Cache ≈ most recently accessed C/Z distinct lines more pragmatically, if you typically access data larger than cache line granularity (i.e., when you touch an element, you almost certainly touch the surrounding Z bytes), forget Z ; otherwise cache ≈ most recently accessed C/Z elements approximation 2.0: large associativities of recent caches alleviate the need to worry too much about it pragmatically, avoid conflicts I mentioned 25 / 67
Contents 1 Introduction 2 Organization of processors, caches, and memory 3 Caches 4 So how costly is it to access data? Latency Bandwidth Many algorithms are bounded by memory not CPU Easier ways to improve bandwidth Memory bandwidth with multiple cores 5 How costly is it to communicate between threads? 26 / 67
Assessing the cost of data access we like to obtain cost to access data in each level of the caches as well as main memory latency: time until the result of a load instruction becomes available bandwidth: the maximum amount of data per unit time that can be transferred between the layer in question to CPU (registers) 27 / 67
Contents 1 Introduction 2 Organization of processors, caches, and memory 3 Caches 4 So how costly is it to access data? Latency Bandwidth Many algorithms are bounded by memory not CPU Easier ways to improve bandwidth Memory bandwidth with multiple cores 5 How costly is it to communicate between threads? 28 / 67
How to measure a latency (need a little creativity)? prepare an array of N records and access them repeatedly to measure a latency , make sure N load instructions make a chain of dependencies (link list traversal) ✞ for ( N times) { 1 p = p->next; 2 } 3 make sure p->next links all the elements in a random order (so the processor cannot prefetch them) next pointers (link all elements in a random order) cache line size N elements 29 / 67
Data size vs. latency main memory is local to the accessing thread ✞ numactl --cpunodebind 0 --interleave 0 ./traverse 1 latency per load in a list traversal (local) [ ≥ 0] 250 local 200 latency/load chip (socket, node, CPU) (physical) core 150 hardware thread (virtual core, CPU) L2 cache L1 cache memory controller L3 cache interconnect 100 50 0 1 × 10 6 1 × 10 7 1 × 10 8 1 × 10 9 10000 100000 size of the region (bytes) 30 / 67
How long are latencies heavily depends on in which level of the cache data fit compare them with the latency of flops 250 200 size level latency main (cycles) memory 150 12736 L1 3.73 latency/load 101312 L2 9.69 L3 1047232 L3 47.46 100 104387776 main 184.37 L2 50 L1 0 1x10 6 1x10 7 1x10 8 1x10 9 10000 100000 size of the region (bytes) 31 / 67
Latency when main memory is remote make main memory remote to the accessing thread ✞ numactl --cpunodebind 0 --interleave 1 ./traverse 1 latency per load in a list traversal (local and remote) [ ≥ 0] 350 local remote 300 250 latency/load chip (socket, node, CPU) (physical) core hardware thread (virtual core, CPU) L2 cache L1 cache 200 memory controller L3 cache interconnect 150 100 50 0 1 × 10 6 1 × 10 7 1 × 10 8 1 × 10 9 10000 100000 size of the region (bytes) 32 / 67
Contents 1 Introduction 2 Organization of processors, caches, and memory 3 Caches 4 So how costly is it to access data? Latency Bandwidth Many algorithms are bounded by memory not CPU Easier ways to improve bandwidth Memory bandwidth with multiple cores 5 How costly is it to communicate between threads? 33 / 67
Bandwidth of a random link list traversal bandwidth = total bytes read elapsed time in this experiment, we set record size = 64 bandwidth (local and remote) [ ≥ 0] 40 local 35 remote bandwidth (GB/sec) 30 chip (socket, node, CPU) (physical) core 25 hardware thread (virtual core, CPU) L1 cache L2 cache memory controller L3 cache 20 interconnect 15 10 5 0 1 × 10 6 1 × 10 7 1 × 10 8 1 × 10 9 10000 100000 size of the region (bytes) 34 / 67
Zooming into the “main memory” bandwidth (local and remote) [ ≥ 100000000] 0 . 8 local 0 . 7 remote bandwidth (GB/sec) 0 . 6 0 . 5 0 . 4 0 . 3 0 . 2 0 . 1 0 1 × 10 8 1 × 10 9 size of the region (bytes) much lower than the memcpy bandwidth we have seen (4 . 5 GB/s) not to mention the “memory bandwidth” in the processor spec (68 GB/s) 35 / 67
Why is the bandwidth so low? while traversing a single link list, only a single load operation is “in flight” at a time next pointers (link all elements in a random order) cache line size N elements in other words, bandwidth = a record size latency assuming frequency = 2 . 0GHz, ≈ 64 bytes 200 cycles = 0 . 32 bytes/cycle ≈ 0 . 64 GB/s 36 / 67
How to get more bandwidth? just like flops/clock, the only way to get a better throughput (bandwidth) is to perform many load operations concurrently in this example, we can increase throughput by traversing multiple link lists ✞ for ( N times) { 1 p1 = p1->next; 2 p2 = p2->next; 3 ... 4 } 5 let’s increase the number of lists and observe the bandwidth 37 / 67
Bandwidth (local main memory) bandwidth with a number of chains (local) [ ≥ 0] 100 1 chains 90 2 chains 4 chains 80 bandwidth (GB/sec) 8 chains 70 10 chains 12 chains 60 14 chains 50 40 30 20 10 0 1 × 10 6 1 × 10 7 1 × 10 8 1 × 10 9 1000 10000 100000 size of the region (bytes) Let’s focus on “main memory” regime (size > 100MB) 38 / 67
Bandwidth to local main memory (not cache) an almost proportional improvement up to 10 lists bandwidth with a number of chains (local) [ ≥ 100000000] 6 1 chains 2 chains 5 4 chains bandwidth (GB/sec) 8 chains 10 chains 4 12 chains 14 chains 3 2 1 0 1 × 10 8 1 × 10 9 size of the region (bytes) 39 / 67
Bandwidth to remote main memory (not cache) pattern is the same (improve up to 10 lists) remember the remote latency is longer, so the bandwidth is accordingly lower bandwidth with a number of chains (remote) [ ≥ 100000000] 4 1 chains 3 . 5 2 chains 4 chains bandwidth (GB/sec) 3 8 chains 10 chains 2 . 5 12 chains 14 chains 2 1 . 5 1 0 . 5 0 1 × 10 8 1 × 10 9 size of the region (bytes) 40 / 67
The number of lists vs. bandwidth observation: bandwidth increased up to 10 lists and then plateaus 41 / 67
The number of lists vs. bandwidth observation: bandwidth increased up to 10 lists and then plateaus question: why 10? 41 / 67
The number of lists vs. bandwidth observation: bandwidth increased up to 10 lists and then plateaus question: why 10? answer: each core can have only so many load operations in flight at a time 41 / 67
The number of lists vs. bandwidth observation: bandwidth increased up to 10 lists and then plateaus question: why 10? answer: each core can have only so many load operations in flight at a time line fill buffer (LFB) is the processor resource that keeps track of outstanding loads, and its size is 10 in Haswell 41 / 67
The number of lists vs. bandwidth observation: bandwidth increased up to 10 lists and then plateaus question: why 10? answer: each core can have only so many load operations in flight at a time line fill buffer (LFB) is the processor resource that keeps track of outstanding loads, and its size is 10 in Haswell this gives the maximum attainable bandwidth per core cache line size × LFB size latency 41 / 67
The number of lists vs. bandwidth observation: bandwidth increased up to 10 lists and then plateaus question: why 10? answer: each core can have only so many load operations in flight at a time line fill buffer (LFB) is the processor resource that keeps track of outstanding loads, and its size is 10 in Haswell this gives the maximum attainable bandwidth per core cache line size × LFB size latency with cache line size = 64, latency = 200, it’s ≈ 3 bytes/clock ≈ 6 GB/sec still much lower than the spec! 41 / 67
The number of lists vs. bandwidth observation: bandwidth increased up to 10 lists and then plateaus question: why 10? answer: each core can have only so many load operations in flight at a time line fill buffer (LFB) is the processor resource that keeps track of outstanding loads, and its size is 10 in Haswell this gives the maximum attainable bandwidth per core cache line size × LFB size latency with cache line size = 64, latency = 200, it’s ≈ 3 bytes/clock ≈ 6 GB/sec still much lower than the spec! how can we go beyond this? ⇒ the only way is to use multiple cores 41 / 67
Contents 1 Introduction 2 Organization of processors, caches, and memory 3 Caches 4 So how costly is it to access data? Latency Bandwidth Many algorithms are bounded by memory not CPU Easier ways to improve bandwidth Memory bandwidth with multiple cores 5 How costly is it to communicate between threads? 42 / 67
What do these numbers imply to FLOPS? many computationally efficient algorithms do not touch the same data too many times 43 / 67
What do these numbers imply to FLOPS? many computationally efficient algorithms do not touch the same data too many times e.g., O ( n ) algorithms → touches a single element only a constant number of times 43 / 67
What do these numbers imply to FLOPS? many computationally efficient algorithms do not touch the same data too many times e.g., O ( n ) algorithms → touches a single element only a constant number of times if data > cache for such an algorithm, the algorithm’s performance is often limited by memory bandwidth (or, worse, latency), not CPU 43 / 67
Example: matrix-vector multiply compute Ax ( A : M × N matrix; x : N -vector; 4 bytes/element) ✞ for (i = 0; i < M; i++) 1 for (j = 0; j < N; j++) 2 y[i] += a[i][j] * x[j]; 3 44 / 67
Example: matrix-vector multiply compute Ax ( A : M × N matrix; x : N -vector; 4 bytes/element) ✞ for (i = 0; i < M; i++) 1 for (j = 0; j < N; j++) 2 y[i] += a[i][j] * x[j]; 3 2 MN flops, 4 MN bytes (ignore x ) in fact, it touches each matrix element only once! 44 / 67
Example: matrix-vector multiply compute Ax ( A : M × N matrix; x : N -vector; 4 bytes/element) ✞ for (i = 0; i < M; i++) 1 for (j = 0; j < N; j++) 2 y[i] += a[i][j] * x[j]; 3 2 MN flops, 4 MN bytes (ignore x ) in fact, it touches each matrix element only once! to sustain Haswell’s CPU peak (e.g., 16 fmadds per cycle), a core must access 16 elements (= 64 bytes) per cycle 44 / 67
Example: matrix-vector multiply compute Ax ( A : M × N matrix; x : N -vector; 4 bytes/element) ✞ for (i = 0; i < M; i++) 1 for (j = 0; j < N; j++) 2 y[i] += a[i][j] * x[j]; 3 2 MN flops, 4 MN bytes (ignore x ) in fact, it touches each matrix element only once! to sustain Haswell’s CPU peak (e.g., 16 fmadds per cycle), a core must access 16 elements (= 64 bytes) per cycle if A is not on the cache, assuming 2.0GHz processor, it requires memory bandwidth of: ≈ 64 × 2 . 0 GHz = 128 GB/s per core, or ≈ 20 × more than the processor provides 44 / 67
Note about matrix-matrix multiply the argument does not apply to matrix-matrix multiply (we’ve been trying to get close to CPU peak) 45 / 67
Note about matrix-matrix multiply the argument does not apply to matrix-matrix multiply (we’ve been trying to get close to CPU peak) 2 N 3 flops, 12 N 2 bytes (for square matrices) 45 / 67
Note about matrix-matrix multiply the argument does not apply to matrix-matrix multiply (we’ve been trying to get close to CPU peak) 2 N 3 flops, 12 N 2 bytes (for square matrices) any straightforward algorithm uses a single element O ( N ) times, so it may be possible to design a clever algorithm that brings an element into a cache, and uses that element many times before it’s evicted 45 / 67
Note about matrix-matrix multiply the argument does not apply to matrix-matrix multiply (we’ve been trying to get close to CPU peak) 2 N 3 flops, 12 N 2 bytes (for square matrices) any straightforward algorithm uses a single element O ( N ) times, so it may be possible to design a clever algorithm that brings an element into a cache, and uses that element many times before it’s evicted I don’t mean this does not happen automatically for any algorithm; the order of computation is important 45 / 67
Contents 1 Introduction 2 Organization of processors, caches, and memory 3 Caches 4 So how costly is it to access data? Latency Bandwidth Many algorithms are bounded by memory not CPU Easier ways to improve bandwidth Memory bandwidth with multiple cores 5 How costly is it to communicate between threads? 46 / 67
Other ways to perform many loads concurrently we’ve learned: maximum bandwidth ≈ many ( ≈ 10) memory accesses always in flight 47 / 67
Other ways to perform many loads concurrently we’ve learned: maximum bandwidth ≈ many ( ≈ 10) memory accesses always in flight so far, we have been using link list traversal, so the only way to issue multiple concurrent loads was to have multiple lists (the worst case scenario) 47 / 67
Other ways to perform many loads concurrently we’ve learned: maximum bandwidth ≈ many ( ≈ 10) memory accesses always in flight so far, we have been using link list traversal, so the only way to issue multiple concurrent loads was to have multiple lists (the worst case scenario) fortunately, the life is not always that tough; CPU can extract instruction level parallelism for certain access patterns 47 / 67
Other ways to perform many loads concurrently we’ve learned: maximum bandwidth ≈ many ( ≈ 10) memory accesses always in flight so far, we have been using link list traversal, so the only way to issue multiple concurrent loads was to have multiple lists (the worst case scenario) fortunately, the life is not always that tough; CPU can extract instruction level parallelism for certain access patterns two important patterns CPU can optimize sequential access ( → prefetch ) loads whose addresses do not depend on previous loads 47 / 67
Pattern 1: a linked list with sequential addresses again build a (single) linked list, but this time, p->next always points to the immediately following block note that the instruction sequence is identical to before; only addresses differ the sequence of addresses triggers CPU’s hardware prefetcher next pointers (link all elements in the sequential order) cache line size N elements 48 / 67
Bandwidth of traversing address-ordered list a factor of 10 faster than random case, but this time with only a single list bandwidth of random list traversal vs address-ordered list traversal [ ≥ 0] 40 address-ordered 35 randomly ordered bandwidth (GB/sec) 30 25 20 15 10 5 0 1 × 10 6 1 × 10 7 1 × 10 8 1 × 10 9 10000 100000 size of the region (bytes) 49 / 67
Pattern 2: random addresses but not by traversing a list generate address unlikely to be prefetched by CPU set s to a prime number ≈ n/ 5 and access the array as follows ✞ for ( N times) { 1 a[j]; 2 j = (j + s) % N ; 3 } 4 prefetch won’t happen, but the CPU can go ahead to the next element while bringing a[j] 50 / 67
Bandwidth when not traversing a list a similar improvement over link list traversal bandwidth of random list traversal vs random array traversal [ ≥ 0] 45 random 40 traverse bandwidth (GB/sec) 35 30 25 20 15 10 5 0 1 × 10 6 1 × 10 7 1 × 10 8 1 × 10 9 10000 100000 size of the region (bytes) 51 / 67
Bandwidth of various access patterns bandwidth of various access patterns [ ≥ 100000000] 12 list, ordered, 1 list, ordered, 10 10 list, random, 1 bandwidth (GB/sec) index, random, 1 sequential, 1 8 list, random, 10 index, random, 10 6 sequential, 10 4 2 0 1 × 10 8 1 × 10 9 size of the region (bytes) 52 / 67
Contents 1 Introduction 2 Organization of processors, caches, and memory 3 Caches 4 So how costly is it to access data? Latency Bandwidth Many algorithms are bounded by memory not CPU Easier ways to improve bandwidth Memory bandwidth with multiple cores 5 How costly is it to communicate between threads? 53 / 67
Memory bandwidth with multiple cores run up to 16 threads, all in a single socket each thread runs on a distinct physical core all memory allocated to socket 0 ( numactl -N 0 -i 0 ) bandwidth with a number of threads (local) [ ≥ 100000000] 50 10 chains, 1 threads 45 10 chains, 2 threads 10 chains, 4 threads 40 bandwidth (GB/sec) 10 chains, 8 threads 35 10 chains, 12 threads 10 chains, 16 threads 30 25 20 15 10 5 0 1 × 10 8 1 × 10 9 size of the region (bytes) 54 / 67
Contents 1 Introduction 2 Organization of processors, caches, and memory 3 Caches 4 So how costly is it to access data? Latency Bandwidth Many algorithms are bounded by memory not CPU Easier ways to improve bandwidth Memory bandwidth with multiple cores 5 How costly is it to communicate between threads? 55 / 67
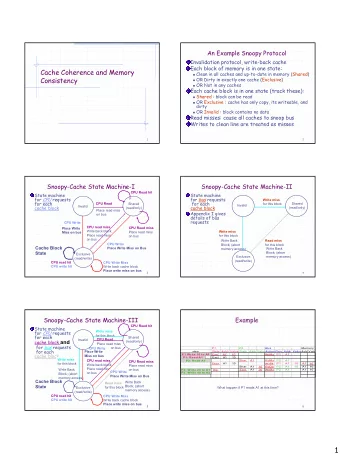
Shared memory if thread P writes to an address a and then another thread B reads from a , Q observes the value written by P x = 100; ... = x; x ordinary load/store instructions accomplish this (hardware shared memory) this should not be taken for granted; processors have caches and a single address may be cached by multiple cores/sockets 56 / 67
Shared memory ⇒ processors sharing memory are running a complex, cache coherence protocol to accomplish this roughly, chip (socket, node, CPU) (physical) core hardware thread (virtual core, CPU) L1 cache L2 cache memory controller L3 cache interconnect 57 / 67
Shared memory ⇒ processors sharing memory are running a complex, cache coherence protocol to accomplish this roughly, a write to an address by a processor “invalidates” all other 1 cache lines holding the address, so that no caches hold “stale” values chip (socket, node, CPU) (physical) core hardware thread (virtual core, CPU) L1 cache L2 cache memory L3 cache controller interconnect 57 / 67
Shared memory ⇒ processors sharing memory are running a complex, cache coherence protocol to accomplish this roughly, a write to an address by a processor “invalidates” all other 1 cache lines holding the address, so that no caches hold “stale” values a read to an address searches for a “valid” line holding the 2 address chip (socket, node, CPU) (physical) core hardware thread (virtual core, CPU) L1 cache L2 cache memory controller L3 cache interconnect 57 / 67
An example protocol : the MSI protocol each line of a cache is one of the following state Modified ( ), Shared ( ), Invalid ( ) 1 chip (socket, node, CPU) (physical) core hardware thread (virtual core, CPU) L1 cache L2 cache memory L3 cache controller interconnect 58 / 67
An example protocol : the MSI protocol each line of a cache is one of the following state Modified ( ), Shared ( ), Invalid ( ) 1 a single address may be cached in multiple caches (lines) chip (socket, node, CPU) (physical) core hardware thread (virtual core, CPU) L1 cache L2 cache memory L3 cache controller interconnect 58 / 67
An example protocol : the MSI protocol each line of a cache is one of the following state Modified ( ), Shared ( ), Invalid ( ) 1 a single address may be cached in multiple caches (lines) there are only two legitimate states for each address one Modified (owner) + others Invalid ( , , , , , . . . ) 1 chip (socket, node, CPU) (physical) core hardware thread (virtual core, CPU) L1 cache L2 cache memory L3 cache controller interconnect 58 / 67
An example protocol : the MSI protocol each line of a cache is one of the following state Modified ( ), Shared ( ), Invalid ( ) 1 a single address may be cached in multiple caches (lines) there are only two legitimate states for each address one Modified (owner) + others Invalid ( , , , , , . . . ) 1 no Modified ( , , , , , . . . ) 2 chip (socket, node, CPU) (physical) core hardware thread (virtual core, CPU) L1 cache L2 cache memory L3 cache controller interconnect 58 / 67
Cache states and transaction suppose a processor reads or writes an address and finds a line caching it what happens when the line is in each state: Modified Shared Invalid read hit hit read miss write hit write miss read miss; write miss read miss: → there may be a cache holding it in Modified state (owner) searches for the owner and if found, downgrade it to Shared , , , [ ], , . . . ⇒ , , , [ ], , . . . write miss: → there may be caches holding it in Shared state (sharer) searches for sharers and downgrade them to Invalid , , , [ ], , . . . ⇒ , , , [ ], , . . . 59 / 67
MESI and MESIF exntensions to MSI have been commonly used MESI: MSI + Exclusive (owned but clean) when a read request finds no other caches that have the line, it owns it as Exclusive Exclusive lines do not have to be written back to main memory when discarded MESIF: MESI + Forwarding (a cache responsible for forwarding a line) used in Intel QuickPath when a line is shared by many readers, one is designated as the Forwarder when another cache requests the line, only the forwarder sends it and the new requester becomes the forwarder (in MSI or MESI, all shares forward it) 60 / 67
How to measure communication latency? measure “ping-pong” latency between two threads ✞ volatile long x = 0; 1 volatile long y = 0; 2 ✞ ✞ (ping thread) (pong thread) 1 1 for (i = 0; i < n; i++) { for (i = 0; i < n; i++) { 2 2 x = i + 1; while (x <= i) ; 3 3 while (y <= i) ; y = i + 1; 4 4 } } 5 5 i + 1 i + 1 x i x = i + 1; while (x <= i) ; while (y <= i) ; y y = i + 1; i i + 1 i + 1 61 / 67
Recommend
More recommend
Unleash a World of Digital Possibilities—Browse, Share, and Explore Content Without Boundaries