
Time-Varying Variable-Length Error-Correcting Codes Victor - PowerPoint PPT Presentation
Time-Varying Variable-Length Error-Correcting Codes Victor Buttigieg Johann A. Briffa ISITA 2018, 31 October 2018, Singapore Department of Communications and Computer Engineering University of Malta Msida MSD 2080, Malta Outline
Time-Varying Variable-Length Error-Correcting Codes Victor Buttigieg Johann A. Briffa ISITA 2018, 31 October 2018, Singapore Department of Communications and Computer Engineering University of Malta Msida MSD 2080, Malta
Outline Introduction and motivation Time-Varying Variable-Length Error-Correcting (TV-VLEC) codes Sequence-level MAP decoder Symbol-Constrained Free Distance (SCFD) Results Conclusions 2/21
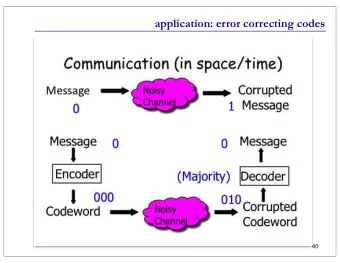
Introduction and Motivation Variable-Length Codes • Used mainly for source coding • Suffer from loss of synchronization under error conditions (Takishima et al ., 1994) • Symbols may be inserted and/or deleted at the decoder 3/21
Introduction and Motivation Variable-Length Codes • Used mainly for source coding • Suffer from loss of synchronization under error conditions (Takishima et al ., 1994) • Symbols may be inserted and/or deleted at the decoder Simple VL Code Message: b c Encoded Message: 10 11 a 0 Received: 00 11 b 10 Decoded Message: aa c c 11 3/21
Introduction and Motivation Motivation • Introduce mechanisms that aid in the detection and avoidance of inserted/deleted symbols • Redundancy – Variable-Length Error-Correcting (VLEC) codes • Decoder keeping track of number of symbols – Sequence MAP Decoder • Time-dependency – Time-Varying Variable-Length Error-Correcting (TV-VLEC) codes • Improves • symbol-level synchronization • error performance 4/21
TV-VLEC Codes Definitions • Define a TV-VLEC code of order m , as the set of m distinct sub-codes C = { C ✵ , C ✶ , . . . , C m − ✶ } , where each sub-code C i consists of s codewords. • Two sub-codes are distinct if they differ in at least one codeword. • The length of codeword ❝ is denoted by | ❝ | . • In regular TV-VLEC codes, all C i have the same length distribution Encoding • Let X = { x ✵ , x ✶ , . . . , x s − ✶ } be an s -symbol memoryless source. • Let P ( x j ) ≥ P ( x j + ✶ ) , where P ( x j ) is the probability of occurrence of symbol x j • The more probable symbols are encoded using the shorter codewords. For sub-code C i , symbol x j is mapped to codeword ❈ i ( x j ) , where | ❈ i ( x j ) | ≤ | ❈ i ( x j + ✶ ) | 5/21
TV-VLEC Codes TV-VLEC Sequence-Use • Consider the message ❛ = ( a ✵ , a ✶ , . . . , a K − ✶ ) consisting of K symbols from source X • Message ❛ is encoded as the sequence ❜ = ❈ u ✵ ( a ✵ ) � ❈ u ✶ ( a ✶ ) � . . . � ❈ u K − ✶ ( a K − ✶ ) • The TV-VLEC sequence-use is defined by ✉ = ( u ✵ , u ✶ , . . . , u K − ✶ ) , u k ∈ { ✵ , ✶ , . . . , m − ✶ } , k = ✵ , ✶ , . . . , K − ✶ • The sequence-use could be set to be • Sequential (each sub-code used in turn) • Random (sub-code selected randomly) • Fixed (sub-codes used in fixed repeating pattern) 6/21
TV-VLEC Codes Encoding Example Source TV-VLEC Code B TV-VLEC Code B Symbol C 0 C 1 C 0 C 1 Message: x 0 x 0 x 2 x 1 Message: x 0 x 0 x 2 x 1 x 0 00 00 11 11 Encoded massage: 001110011000 Encoded massage: 001110011000 x 1 111 111 000 000 x 2 10011 10011 01100 01100 Sequence-Use: 0 1 0 1 Sequence-Use: 0 1 0 1 x 3 01001 01001 10110 10110 7/21
Sequence-Level MAP Decoder Decoders for VLEC Codes • In the literature, several decoders for VLEC codes are given • Maximum-likelihood (Buttigieg & Farrell, 1993) • Symbol-level and sequence-level MAP decoders – both exact and approximate (Park & Miller, 2000) • Different channel models were also considered - BSC, Gaussian and Additive-Markov (Subbalakshmi & Vaisey, 2003) • The changes required to accommodate TV-VLEC codes are minimal • Decoder complexity remains the same 8/21
Sequence-Level MAP Decoder Bit Index, n 19 18 17 16 Source TV-VLEC Code B TV-VLEC Code B Symbol C 0 C 1 C 0 C 1 15 x 0 00 00 11 11 14 x 1 111 111 000 000 13 x 2 10011 10011 01100 01100 12 x 3 01001 01001 10110 10110 11 10 Message: x 0 x 0 x 2 x 1 Message: x 0 x 0 x 2 x 1 Encoded massage: 001110011000 Encoded massage: 001110011000 9 Sequence-Use: 0 1 0 1 Sequence-Use: 0 1 0 1 8 7 6 5 4 3 2 1 0 Symbol Index, k 0 1 2 3 9/21
Sequence-Level MAP Decoder Path Metric • The path metric to be maximized is given by K − ✶ � a k ) , ② ( k ) � � ❛ ) � M (ˆ (log p − log ( ✶ − p )) d ❤ ❈ u k (ˆ + log P (ˆ a k ) k = ✵ • p is the BSC cross-over probability � a k ) , ② ( k ) � • d ❤ ❈ u k (ˆ is the Hamming distance between the codeword from sub-code u k corresponding to the k th decoded symbol ˆ a k and the corresponding received sub-sequence ② ( k ) • P (ˆ a k ) is the a priori probability of the k th decoded symbol • Maximization can be achieved using dynamic programming on a trellis 10/21
Symbol-Constrained Free Distance Distance Measures • In decoders that ignore the number of decoded symbols, paths merge when a sequence of codewords have an equal number of bits • The appropriate distance measure to use in this case is the free distance • In decoders that are constrained on the number of decoded symbols, paths merge when a sequence of codewords have an equal number of bits and an equal number of codewords • In this work we introduce the Symbol-Constrained Free Distance (SCFD) to take this into account 11/21
Symbol-Constrained Free Distance Bit Index, n 19 18 17 16 15 Source TV-VLEC Code B TV-VLEC Code B Symbol C 0 C 1 C 0 C 1 14 x 0 00 00 11 11 13 x 1 111 111 000 000 12 x 2 10011 10011 01100 01100 11 x 3 01001 01001 10110 10110 10 9 Message 1: x 0 x 1 x 2 Message 1: x 0 x 1 x 2 Encoded massage 1: 0000010011 Encoded massage 1: 0000010011 8 Sequence-Use: 0 1 0 Sequence-Use: 0 1 0 7 Encoded massage 2: 1001111111 6 Message 2: x 2 x 0 x 1 5 4 3 2 1 0 12/21
Symbol-Constrained Free Distance Free Distance • The free distance of a TV-VLEC code C = { C ✵ , C ✶ , . . . , C m − ✶ } of order m and with sequence-use ✉ = ( u ✵ , u ✶ , . . . , u K − ✶ ) is the minimum Hamming distance between any two codeword concatenations ❈ u i ′ ( a ′ ✵ ) � ❈ u i ′ + ✶ ( a ′ � a ′ � ✶ ) � . . . � ❈ u i ′ + K ′− ✶ and K ′ − ✶ � � ❈ u i ′′ ( a ′′ ✵ ) � ❈ u i ′′ + ✶ ( a ′′ ✶ ) � . . . � ❈ u i ′′ + K ′′− ✶ a ′′ , K ′′ − ✶ where a ′ j , a ′′ j are two source symbols such that a ′ ✵ � = a ′′ ✵ , K ′ − ✶ K ′′ − ✶ k ′ − ✶ k ′′ − ✶ � �� � �� � �� � �� � � � � � � � � a ′ � = a ′′ a ′ � � = a ′′ � ❈ u i ′ + j � ❈ u i ′′ + j � ❈ u i ′ + j � ❈ u i ′′ + j � � � � � � � � � and j j j j � j = ✵ j = ✵ j = ✵ j = ✵ for any k ′ < K ′ and k ′′ < K ′′ , K ′ , K ′′ = ✶ , ✷ , . . . , K , i ′ = ✵ , ✶ , . . . , K − K ′ , and i ′′ = ✵ , ✶ , . . . , K − K ′′ . 13/21
Symbol-Constrained Free Distance Bit Index, n 19 18 17 16 15 14 Source TV-VLEC Code B TV-VLEC Code B Symbol C 0 C 1 C 0 C 1 13 x 0 00 00 11 11 12 x 1 111 111 000 000 11 x 2 10011 10011 01100 01100 10 x 3 01001 01001 10110 10110 9 8 Message 1: x 0 x 1 x 2 Message 1: x 0 x 1 x 2 Encoded massage 1: 0000010011 Encoded massage 1: 0000010011 7 Sequence-Use: 0 1 0 Sequence-Use: 0 1 0 6 Encoded massage 2: 1001111111 5 Message 2: x 2 x 0 x 1 4 3 2 1 0 Symbol Index, k 0 1 2 3 14/21
Symbol-Constrained Free Distance Symbol-Constrained Free Distance • The symbol-constrained free distance of a TV-VLEC code C = { C ✵ , C ✶ , . . . , C m − ✶ } of order m and with sub-code sequence-use ✉ = ( u ✵ , u ✶ , . . . , u K − ✶ ) is the minimum Hamming distance between any two codeword concatenations ❈ u i ( a ′ ✵ ) � ❈ u i + ✶ ( a ′ � a ′ � ✶ ) � . . . � ❈ u i + K ′− ✶ and K ′ − ✶ � � ❈ u i ( a ′′ ✵ ) � ❈ u i + ✶ ( a ′′ ✶ ) � . . . � ❈ u i + K ′− ✶ a ′′ , K ′ − ✶ where a ′ j , a ′′ j are two source symbols such that a ′ ✵ � = a ′′ ✵ , K ′ − ✶ K ′ − ✶ k − ✶ k − ✶ � � = � � � � = � � � �� � � �� � � �� � � �� a ′ a ′′ a ′ a ′′ � ❈ u i + j � ❈ u i + j � and � ❈ u i + j � ❈ u i + j j j j j � j = ✵ j = ✵ j = ✵ j = ✵ for k < K ′ , K ′ = ✶ , ✷ , . . . , K and i = ✵ , ✶ , . . . , K − K ′ . 15/21
Symbol-Constrained Free Distance Problem with Order One TV-VLEC Codes • An order one TV-VLEC code is a VLEC code • A symbol-constrained MAP decoder can recover symbol sync by a "reverse" error event 16/21
Symbol-Constrained Free Distance Problem with Order One TV-VLEC Codes • An order one TV-VLEC code is a VLEC code • A symbol-constrained MAP decoder can recover symbol sync by a "reverse" error event 0101111010 Source Symbol VLEC Code A 1101001011 x 0 0 x 1 1011 x 2 11010 16/21
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.