Table of contents 1. Introduction: You are already an - PowerPoint PPT Presentation
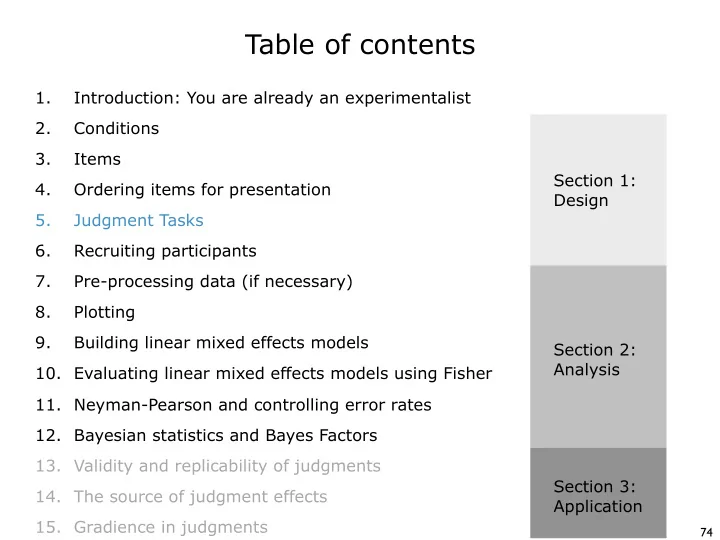
Table of contents 1. Introduction: You are already an experimentalist 2. Conditions 3. Items Section 1: 4. Ordering items for presentation Design 5. Judgment Tasks 6. Recruiting participants 7. Pre-processing data (if necessary) 8.
Table of contents 1. Introduction: You are already an experimentalist 2. Conditions 3. Items Section 1: 4. Ordering items for presentation Design 5. Judgment Tasks 6. Recruiting participants 7. Pre-processing data (if necessary) 8. Plotting 9. Building linear mixed effects models Section 2: Analysis 10. Evaluating linear mixed effects models using Fisher 11. Neyman-Pearson and controlling error rates 12. Bayesian statistics and Bayes Factors 13. Validity and replicability of judgments Section 3: 14. The source of judgment effects Application 15. Gradience in judgments 74
Four basic tasks There are four basic tasks in experimental syntax. I will briefly talk about all of them, but for most experiments, I believe the best choice is Likert Scale. Likert Scale: Participants judge each sentence individually along a numerical scale. The scale generally has an odd number of points (so there is a middle point), but in theory it could be even. Magnitude Participants judge each sentence individually, but judge it Estimation: relative to a reference sentence. The ratings are numerical. Yes-No: Participants indicate whether a sentence is grammatical/ ungrammatical (possible/impossible, acceptable/ unacceptable). This it technically a two-alternative forced- choice task (2AFC), but I use that label for the next task. Forced-Choice: Participants judge two (or more) sentences simultaneously, and indicate which is better (or worse). When there are two sentences, it is a two-alternative forced-choice (2AFC). 75
The Likert Scale Task Likert Scale: Participants judge each sentence individually along a numerical scale. The scale generally has an odd number of points (so there is a middle point), but in theory it could be even. least acceptable most acceptable 1 2 3 4 5 6 7 1. Who thinks that John bought a car? 2. What do you think that John bought? 3. Who wonders whether John bought a car? 4. What do you wonder whether John bought? For Likert Scale tasks you have to choose the number of scale points. The trick is to choose a number that is high enough for participants to report as many differences as they want, but not so high that they won’t use all of them. I like to use 7. It is also best to use an odd number so there is a middle point. You also need to label the two ends of the scale. I like to use least/most acceptable. I also like to make the low numbers the low ratings. The reverse seems confusing to some participants. 76
The Likert Scale Task What is the difference between an odd number and an even number of points? I think this question is most salient if you assume (i) a binary grammar (two types of strings: grammatical and ungrammatical), and (ii) a linking hypothesis between acceptability and grammaticality whereby the location on the continuum of acceptability indicates grammaticality (higher is grammatical, lower is ungrammatical). Both of these assumptions are open areas of research — there are plenty of non-binary approaches to grammar; and there are well-known examples of misalignment between acceptability and grammaticality: Unacceptable, but probably grammatical: *The reporter the senator the president insulted contacted filed the story. Initially acceptable, but ungrammatical: More people have been to Russian than I have. 77
The Likert Scale Task What is the difference between an odd number and an even number of points? An odd number of points gives participants the option of saying that they don’t know whether this should fall on the acceptable or unacceptable side of the spectrum. most acceptable least acceptable 1 2 3 4 5 6 7 Who thinks that John bought a car? An even number of points turns this into a type of binary forced-choice: participants have to choose a side of the scale. I like to keep the binary aspect out of the Likert scale because the nature of the relationship between acceptability and grammaticality is such an open question. most acceptable least acceptable 1 2 3 4 5 6 Who thinks that John bought a car? 78
The Likert Scale Task Why 7 points? Why not 5 or 9? Bard et al. 1996 demonstrated that 5 was not enough. Participants can distinguish more than 5 levels of acceptability. To my knowledge, nobody has demonstrated that 7 is not enough, or that some higher number is preferable. This is a gap in our methodological knowledge. But a bit later in this lecture, I will show you that completely unconstrained scales do not increase statistical power over 7 point scales… suggesting that there is a finite number that is ideal. And, I can tell you that I have never had a participant tell me that they felt constrained by a 7 point scale. I only ran in-person studies from 2004 to 2010. Since 2010, nearly all of my experiments have been online, so there is little opportunity for them to tell me (unless they email me). 79
LS Benefit: Effect sizes One of the primary benefits of LS tasks is that they provide a clear mechanism for assessing the sizes of differences between conditions s1 s2 s3 s4 s5 participant 1: 1 2 3 4 5 6 7 There will be some variability in the cases where a sentence falls on the boundary between two ratings (the way that s3 falls on the 4/5 boundary), but in general, the numerical ratings of LS tasks lend themselves to the types of analyses that we want for factorial designs. However, this rests on several assumptions about how participants use the scales. Can you think of what those assumptions are? We will go through them in the “drawbacks” slides for LS! 80
LS Benefit: Multiple comparisons Even though each sentence is rated in isolation in an LS task, because those ratings are made relative to a scale, it is possible to make comparisons between any and all of the sentences in the experiment. s1 s2 s3 s4 s5 participant 1: 1 2 3 4 5 6 7 This means that you do not need to know which comparisons you are going to make before you run the experiment. Although in practice, there is no point in running an experiment if you don’t know what you are looking for! 81
LS Benefit: Location on the scale The responses in LS tasks tell you where along the scale a given sentence is. This means that you can interpret the location on the scale if you want to. For example, if you assume a binary theory of grammaticality, you could interpret the location of the rating as indicative of the grammaticality of the sentence: s1 s2 s3 s4 s5 participant 1: 1 2 3 4 5 6 7 grammaticality: Of course, this rests on a number of assumptions about how the participant uses the scale, how grammars work, and how acceptability maps to grammaticality (a linking hypothesis)! So it isn’t an argument, but rather an assumption, or better yet, a research question. 82
LS Drawback: Scale biases Scale Bias: Different participants might choose to use a scale in different ways. s1 s2 s3 s4 s5 participant 1: 1 2 3 4 5 6 7 participant 2: 3 4 5 participant 3: 1 2 3 participant 4: 5 6 7 We can eliminate basic scale bias with a z-score transformation, which we will talk about a bit later. 83
LS Drawback: Finite options The LS task gives participants a finite number of response options. This means that there may be certain differences between conditions that they cannot report: s1 s2 participant 1: 1 2 3 4 5 6 7 The two sentences above would both be rated a 3, even though they do have a small difference between them. The obvious solution to this is to increase the number of responses in the scale. But this runs the risk of introducing too many response options. If the scale defines units that are smaller than the units that humans can use, it could introduce noise in the measurements (or stress in the participants). 84
LS Drawback: Non-linear scales One of the assumptions in the LS task is that each of the response categories is exactly the same size (that they define the same interval). But this need not be the case: s1 s2 s3 s4 s5 participant 1: 1 2 3 4 5 6 7 participant 2: 1 2 3 4 5 6 7 participant 3: 1 2 3 4 5 6 7 There is no easy solution to this (although one could imagine building a model to try to estimate these non-linearities for each participant). 85
The Magnitude Estimation Task Magnitude Participants judge each sentence individually, but judge it Estimation: relative to a reference sentence. The ratings are numerical. The first step is to define a reference stimulus. Usually this is chosen to be in approximately the middle of the range of acceptability. The reference stimulus is called the standard . It is assigned a number that represents its acceptability rating. This number is called the modulus . Usually the modulus is a nice round number like 100. Who said my brother was kept tabs on by the FBI? 100 Participants are then asked to rate each sentence in the experiment relative to the standard and modulus. The idea is that if the sentence is twice as acceptable, they would rate the sentence as twice the modulus (e.g., 200). If it is half as acceptable, they would rate it as half the modulus (e.g., 50): What do you wonder whether John bought? ??? 86
Recommend

















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.