
Post-separation analysis Pierre-Alain Binz Swiss Institute of - PDF document
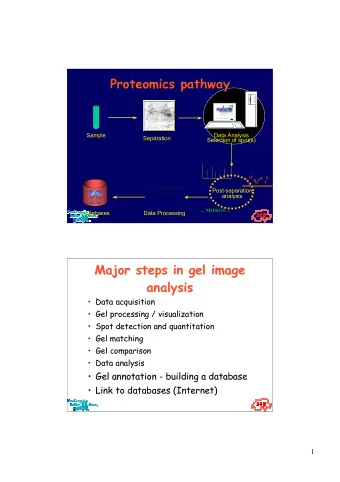
Post-separation analysis Pierre-Alain Binz Swiss Institute of Bioinformatics EMBNet course March 1-5, 2004 Proteomics pathway / generic workflow Sample Data Analysis, Separation Selection of spot(s) G Q E R N K M T E
Post-separation analysis Pierre-Alain Binz Swiss Institute of Bioinformatics EMBNet course March 1-5, 2004 Proteomics pathway / generic workflow Sample Data Analysis, Separation Selection of spot(s) G Q E R N K M T E Post-separation analysis ... NRTKGG ... Databases Data processing 1
Proteomics pathway / generic workflow Samples comparison Specific Identification tools choice of sample Statistical analysis sample collection Specific Characterisation tools Choice of fractions (LC) sample pre-fractionation Choice of gel spots (1-DE, 2-DE) Analysis tools Sample Edman sequencing Data Analysis, sample pre-treatment Separation Selection of spot(s) Systematic analysis AAA Sample and data tracking Validation tools Endoproteolytic cleavage LC (CEX, affinity, etc.) Mass Spectrometry G Q (MALDI-MS, ESI MS/MS) R E 1-DE (CE, SDS) N K T M E Post-separation 2-DLC, 2-DE analysis ... NRTKGG ... Databases Data processing Experimental attributes for Experimental attributes for proteome studies studies proteome species PTM biological sample, biological sample, cell extract, ... keyword cell extract, ... tissue Mw Entire protein extraction «spot» cut from 2-DE MALDI-MS, ESI-MS Peptide Peptide digestion fragments fragments peptide mass fingerprints 2D-PAGE Edman Transblot degradation on a MS/MS membrane HPLC PSD AA analysis CID, ISD sequence, pI Mr spot intensity AA composition sequence tags 2
Protein Identification Scheme Expert Protein Analysis System http://www.expasy.org Access Statistics Feb 1st 2004 Total number of connections 347'781'091 since August 1993: 4'101'804 Total number of hosts that accessed ExPASy: January 2004 (connections:) 6'296'007 Currently 8 mirrors available: Australia, Bolivia, Canada, China, Korea, Switzerland, Taiwan, USA And a secure server at 3
ExPASy tools page Identification: Identification: PeptIdent, PeptIdent, Aldente Aldente TagIdent, TagIdent, AAcompIdent, AAcompIdent, MultiIdent, MultiIdent, CombSearch CombSearch Characterization: Characterization: FindMod, FindMod, GlycoMod, GlycoMod, FindPept FindPept Analysis: Analysis: PeptideMass, PeptideMass, GlycanMass GlycanMass - Use annotation in SWISS-PROT and TrEMBL BioGraph, BioGraph, (preprocessing, PTMs, etc.) ProtScale, ProtScale, ProtParams - Hyper-links between tools and databases ProtParams 4
Proteins identification using proteomic analysis methods • Gel matching - • Co-migration Confidence index • AA composition analysis • Imunodetection + • Mass spectrometry Gel matching & protein co-migration 5
AA composition analysis MRSLLILVLC FLPLAALGKV FGRCELAAAM... Acid hydrolysis 6M HCl, 1 h, 160°C Cat: phenol cristal Free amino acids AA derivatisation HPLC separation Chromatogram Determination of the AA Quantification of material composition analysed 6
AA composition analysis AA composition analysis 7
AA composition analysis of Lysozyme AA LYC_CHICK STD [AA] en pmol % AA Theo AA % D & Q 900429 284708 790.7 19.2 21.4 E & N 355747 342065 260.0 6.3 5.1 Cys-PAM 0 1162 0.0 Cys-CAM 55843 0 0.0 Hyp 1299384 1145045 283.7 0.0 S 800004 500572 399.5 9.7 10.2 H 14344 263754 13.6 0.3 1.0 G 1260209 636948 494.6 12.0 12.2 T 491550 484090 253.9 6.2 7.1 A 727955 441015 412.7 10.0 12.2 P 192289 619034 77.7 1.9 2.1 Y 61184 276460 55.3 1.3 3.0 R 796946 471232 422.8 10.3 11.2 V 344061 577000 149.1 3.6 6.2 M 47795 355085 33.7 0.8 2.1 I 287566 521712 137.8 3.4 6.2 L 344061 503932 170.7 4.2 8.1 F 397367 259872 382.3 9.3 3.0 K 74344 325145 57.2 1.4 6.2 AACompIdent 8
Protein identification by amino acid analysis PVDF-bound gas phase one step AA protein hydrolysis in extraction in from 2-D glass vial same vial protein identification automated AA by database matching analysis AACompIdent output for single species identification : Spot ECOLItest ============== AMINO ACID COMPOSITION Asx: 17.90 Glx: 15.00 Ser: 3.40 Gly: 7.70 His: 0.30 Thr: 5.50 Ala: 14.10 Pro: 4.70 Tyr: 0.30 Arg: 1.40 Val: 9.30 Met: 0.70 Ile: 3.70 Leu: 4.50 Phe: 3.80 Lys: 8.50 Tagging: No_Tag pI: 4.68 Range: 4.43 - 4.93 Mw: 9741 Range: 7793 - 11689 The ECOLI entries having pI and Mw values in the specified range: Rank Score Protein pI Mw Description ======================================================================= 1 20 HDEA_ECOLI 4.68 9741 PROTEIN HDEA. 2 187 GLR1_ECOLI 4.81 9685 GLUTAREDOXIN 1 (GRX1). 3 187 YCCJ_ECOLI 4.70 8524 HYPOTHETICAL 8.5 KD PROTEIN IN AGP 4 224 YFHF_ECOLI 4.43 11536 HYPOTHETICAL 11.5 KD PROTEIN IN HSCA 5 224 THIO_ECOLI 4.67 11675 THIOREDOXIN. 9
Edman Degradation Edman Degradation 10
AACompIdent with tag option AACompIdent output for sequence tag and AAC identification SpotNb YEAST-JH7 =============== AMINO ACID COMPOSITION FOR UNKNOWN PROTEIN Asx: 15.68 Glx: 9.70 Ser: 6.63 His: 1.09 Gly: 12.17 Thr: 4.86 Ala: 11.52 Pro: 2.57 Tyr: 2.47 Arg: 2.51 Val: 8.95 Met: 0.50 Ile: 5.53 Leu: 6.30 Phe: 3.17 Lys: 6.35 Tagging: VRVA pI: 6.60 Range: 6.35 - 6.85 Mw: 33095 Range: 26476 - 39714 The YEAST entries having pI and Mw values in the specified range: Rank Score Protein pI Mw N-terminal Sequence ========================================================================== * 1 19 G3P3_YEAST 6.49 35615 vrvaINGFGRIGRLVMRIALSRPNVEVVALNDPFITNDYA 2 32 DHSO_YEAST 6.46 38165 MSQNSNPAVVLEKVGDIAIEQRPIPTIKDPHYVKLAIKAT 3 40 YKV8_YEAST 6.67 34899 MIVPTYGDVLDASNRIKEYVNKTPVLTSRMLNDRLGAQIY 4 43 YHQ6_YEAST 6.41 37087 MIKHIVSPFRTNFVGISKSVLSRMIHHKVTIIGSGPAAHT 5 44 MDHM_YEAST 6.79 33833 YKVTVLGAGGGIGQPLSLLLKLNHKVTDLRLYDLKGAKGV 11
Many proteins have unique N- and C- sequence tags 100 90 80 % proteins with unique tag 70 60 50 40 30 20 10 0 3AA N-term 4AA N-term 3AA C-term 4AA C-term M. genitalium (469) E. coli ( 4481) S. cerevisiae (4799) How frequent are non-unique E. coli N- and C- tags? 3AA N-Tags 4AA N-Tags 40 40 30 30 20 20 10 10 0 0 MKTL MKKI MKKL MALL MKIL MKNI MLKR MRVL MSEK MAKN MKK MSE MSK MKT MSN MSQ MKI MST MTT MKQ 3AA C-Tags 4AA C-tags 40 40 30 30 20 20 10 10 0 0 AKKK EAAQ FGSN KAGR LEDE RTIA VEKV VYQF AAAN AAGG AKK KKK RRR AAQ AVL EEE KAA LLK QGE YLS 12
E. coli proteins with N-tag MKTL have different pI and MW 60000 50000 40000 predicted mass 30000 20000 10000 0 3 4 5 6 7 8 9 10 predicted pI Protein identification with TagIdent http://www.expasy.org/tools/tagident.html 13
Protein identification with sequence tag, pI & MW e.g. E. coli 2D-000KWF Search performed with following values: pI = 5.97 Mw = 45098 delta-pI = 0.50 delta-Mw = 9019 OS or OC = ECOLI Tagging = MDQT ----------------------------------------------------- 223 proteins found Results with tagging: 1 found DHE4_ECOLI (P00370) [pI = 5.98; Mw = 48581.1] mdqtYSLESFLNHVQKRDPNQTEFAQAVREVMTTLWPFLE --- Results without tagging: 222 found --- Protein identification with sequence tag, pI & MW Wilkins M.R., Gasteiger E. et.al., J.Mol.Biol.278:599-608(1998) Has advantages: - No pretreatment needed (e.g. digestion / extraction) - Data and results are quickly interpreted Best applications: - Organisms with a “small” proteome (e.g. bacteria) - Organisms with a known genome Means of generating terminal tags: - Edman degradation (automated Tag machine, 8-24 samples/day) - C-terminal chemical sequencing - Amino- or carboxypeptidases and mass spectrometry If results are ambiguous: - Use the same PVDF membrane for further analyses 14
Protein identification with sequence tag, pI & MW Has disadvantages: - slow - needs > 1 pmol of purified protein - 75% of high eukaryote proteins are N-term blocked - N-term tag of mature protein can be different from precursor - pI and MW not valid if protein highly modified Immunodetection 1st step Protein electroblotting from a gel to a PVDF membrane 2nd step Proteins on the membrane are incubated with specific antibody solution (diluted serum/plasma or purified antibody solution) 3rd step Peroxidase conjugated anti- antibodies are added and incubated 4th step Light is obtained 5 - 10 minutes after addition of the colouring solution and bands are visible at the sites on the membrane occupied by antibodies 15
Immunodetection Western immunoblots of food contaminated with Staphylococcal Enterotoxins A (SEA). Food samples were homogenized and spiked with purified SEA. The sample (40 µ l) was then applied directly to the gel and assayed by Western blot. Milk, potato salad and meat product with or without SEA were tested. Lane 1 -- Protein Standards; Lane 2 -- milk; Lane 3 -- milk+SEA; Lane 4 -- potato salad; Lane 5 -- potato salad+SEA; Lane 6 -- meat; Lane 7 - meat+SEA. Protein identification by immunodetection Has advantages: - No pretreatment needed (e.g. digestion / extraction) - Data and results are quickly interpreted (no bioinformatics) - Can highlight the presence of a protein in a complex mixture - Very sensitive Has disadvantages: - Some proteins are difficult to transfer on membranes - One protein (epitope) can be detected at a time - Specificity depends on the specificity of the antibody - Rarely allows to tackle the PTMs or splicing variant forms 16
Recommend





















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.