
Pattern Matching in Genomic Sequences through ReRAM Technology - PowerPoint PPT Presentation
FindeR: Accelerating FM-Index-based Exact Pattern Matching in Genomic Sequences through ReRAM Technology Farzaneh Zokaee and Lei Jiang Indiana University Bloomington 3th HPCA Workshop on ACCELERATOR ARCHITECTURE IN COMPUTATIONAL BIOLOGY AND
FindeR: Accelerating FM-Index-based Exact Pattern Matching in Genomic Sequences through ReRAM Technology Farzaneh Zokaee and Lei Jiang Indiana University Bloomington 3th HPCA Workshop on ACCELERATOR ARCHITECTURE IN COMPUTATIONAL BIOLOGY AND BIOINFORMATICS
Executive summary 1. Designing PIM: for genome sequence analysis • Read alignment uses FM-Index algorithm to find exact locations of reads in reference genome . 2. Problems: • Accessing and finding exact matches for huge amount of generated reads by FM-Index (Billions of reads). 3. Proposed solutions: speeding up FM-Index • FindeR: ReRAM-based process-in-memory architecture • Remove cost of data transferring between cpu and memories • Hardware/algorithm co- design → operation parallelism ↑ 4. Results: • Throughput: 83% ~ 30k × over the state-of-the-art. • Throughput/power : 3.5 × ~ 42.5k × over the state-of-the-art. 26
Genome sequencing pipeline Nanopore CCCCC CTATATATACGTACTAGTACGT ACGACTTTAGTACGTACGT TATATATACGTACTAGTACGT ACGTACGCCCC TACGTA TATATATACGTACTAGTACGT ACGACTTTAGTACGTACGT organic DNA TATATATACGTACTAA AAAGTACGT TATATATACGTACTAGTACGT ACG TTTTT AAA ACGTA A T Illumina TATATATACGTACTAGTACGT PacBio ACGACGGG GGG GAGTACGTACGT C G ~3.2B bps Illumina HiSeq2000: short reads (100 bp) with error rate 1% PacBio and Nanopore: long reads (1k bp) with error rate 15-40% 27
Genome sequencing cost decreases $0.07 $0.06 Cost per mega-base $0.05 $0.04 $0.03 $0.02 $0.01 $0.00 Aug-13 Dec-14 May-16 Sep-17 Feb-19 Jun-20 28 [Wetterstrand_GSP’19] available at www.genome.gov/sequencingcostsdata
Genome sequencing pipeline 1 2 Sequencing Read Alignment 4 3 Discovery Variant Calling Billions of Short Reads CCTATAATACG A C T T A G C A C T CCCCC CTATATATACGTACTAGTACGT C 0 1 2 A A 1 0 1 2 C ACGACTTTAGTACGTACGT C 2 1 0 1 2 T T 2 1 0 1 2 A A 2 1 2 1 2 T TATATATACGTACTAGTACGT G 2 2 2 1 2 A A 3 2 2 2 2 T A 3 3 3 2 3 ACGTACGCCCC TACGTA A C 4 3 3 2 3 C T 4 4 3 2 G TATATATACGTACTAGTACGT T 5 4 3 Short Read Read ACGACTTTAGTACGTACGT Alignment TATATATACGTACTAA AAAGTACGT TATATATACGTACTAGTACGT ACG TTTTT AAA ACGTA TATATATACGTACTAGTACGT ... ... ACGACGGG GGG GAGTACGTACGT Reference Genome Illumina HiSeq2000 29 Onur Mutlu, Processing Data Where It Makes Sense in Modern Computing Systems: Enabling In-Memory Computation, 17 September 2018 Cordoba HiPerNav Workshop 2018 Keynote
The pipeline latency matters! Genome sequencing for profiling tumor • Variants → prioritize anti -cancer therapy and direct patient management life or death? which type? Such a test takes several days to weeks !!! 30 [MolecularTesting_2019] available at www.mycancergenome.org/content/page/molecular-testing
Bottleneck in genome sequencing pipeline Genome Read Alignment Sequencing 2 Million 300 Million bases/minute bases/minute Bottlenecked in Alignment!! 31 Onur Mutlu, Processing Data Where It Makes Sense in Modern Computing Systems: Enabling In-Memory Computation, 17 September 2018 Cordoba HiPerNav Workshop 2018 Keynote
The explosion in the genomic data capacity 1.00E+10 Cumulative # of Human Genomes projection 1.00E+08 Nanopore Moore’s Law 1.00E+06 PacBio 1.00E+04 1.00E+02 Sanger Illumina 1.00E+00 2000 2005 2010 2015 2020 2025 2030 32 [Stephens_PLoSBiol2015]
Read alignment Reference A T C C G T A T C C G TA C A G A T T T T T C C A T C C G T A Reads C G T A A A G A T T C A C A T A 33
Read alignment Reference A T C C G T A T C C G TA C A G A T T T T T C C A T C C G T A C G T A Reads hit A A G A T T C A C A T A 34
Read alignment Reference A T C C G T A T C C G TA C A G A T T T T T C C A T C C G T A C G T A A A G A Reads hit insert T T C A C A T A 35
Read alignment Reference A T C C G T A T C C G TA C A G A T T T T T C C A T C C G T A C G T A A A G A T T C A Reads hit delete insert C A T A 36
Read alignment Reference A T C C G T A T C C G TA C A G A T T T T T C C A T C C G T A C G T A A A G A C A T A T T C A Reads hit substitute delete insert 37
Read alignment Reference A T C C G T A T C C G TA C A G A T T T T T C C A T C C G T A C G T A A A G A C A T A T T C A Reads hit substitute delete insert Seed extension Read alignment Seeding : Find inexact matches Seed-and-Extend Find exact matches (FM-Index) Seeding is slow due to FM-Index search algorithm. 38
Burrows-wheeler transform Ref: A T C C G T $ 0 A T C C G T $ 1 T C C G T $ A 2 C C G T $ A T 3 C G T $ A T C 4 G T $ A T C C 5 T $ A T C C G 6 $ A T C C G T 39
Burrows-wheeler transform Ref: A T C C G T $ 0 A T C C G T $ 1 T C C G T $ A 2 C C G T $ A T 3 C G T $ A T C 4 G T $ A T C C 5 T $ A T C C G 6 $ A T C C G T 40
Burrows-wheeler transform Ref: A T C C G T $ 0 A T C C G T $ 1 T C C G T $ A 2 C C G T $ A T 3 C G T $ A T C 4 G T $ A T C C 5 T $ A T C C G 6 $ A T C C G T BWT: T $ T C C G A 41
FM-Index Ref: A T C C G T $ BWT: T $ T C C G A Occ( S , i) i A C G T 0 0 0 0 0 1 0 0 0 1 Count 2 0 0 0 1 A C G T 3 0 0 0 2 1 2 4 5 4 0 1 0 2 5 0 2 0 2 6 0 2 1 2 7 1 2 1 2 42
FM-Index Ref: A T C C G T $ BWT: T $ T C C G A 0 1 2 3 4 Occ( S , i) i A C G T 0 0 0 0 0 1 0 0 0 1 Count 2 0 0 0 1 A C G T 3 0 0 0 2 1 2 4 5 1 4 0 0 2 4 0 1 0 2 5 0 2 0 2 6 0 2 1 2 7 1 2 1 2 43
FM-Index Ref: A T C C G T $ BWT: T $ T C C G A 0 1 2 3 4 Occ( S , i) i A C G T 0 0 0 0 0 1 0 0 0 1 Count 2 0 0 0 1 A C G T 3 0 0 0 2 1 1 2 4 5 1 4 0 0 2 4 0 1 0 2 5 0 2 0 2 6 0 2 1 2 7 1 2 1 2 44
FM-Index Ref: A T C C G T $ BWT: T $ T C C G A 0 1 2 3 4 Occ( S , i) i A C G T 0 0 0 0 0 1 0 0 0 1 Count 2 0 0 0 1 A C G T 3 0 0 0 2 1 1 2 4 5 1 4 0 0 2 4 0 1 0 2 5 0 2 0 2 8 entries! 6 0 2 1 2 7 1 2 1 2 45
FM-Index Ref: A T C C G T $ 0 BWT: T $ T C C G A 0 1 2 3 4 tag Occ( S , i) i A C G T 0 0 0 0 0 1 0 0 0 1 Count 1 2 0 0 0 1 A C G T 3 0 0 0 2 1 1 2 4 5 1 4 0 0 2 4 0 1 0 2 5 0 2 0 2 8 entries! 6 0 2 1 2 7 1 2 1 2 46
FM-Index Ref: A T C C G T $ 0 BWT: T $ T C C G A 0 1 2 3 4 tag Occ( S , i) i A C G T BWT 0 0 0 0 0 BWT 1 0 0 0 1 Count 1 2 0 0 0 1 A C G T 3 0 0 0 2 1 1 2 4 5 1 4 0 0 2 4 0 1 0 2 BWT 5 0 2 0 2 8 entries! 6 0 2 1 2 2 entries 7 1 2 1 2 47
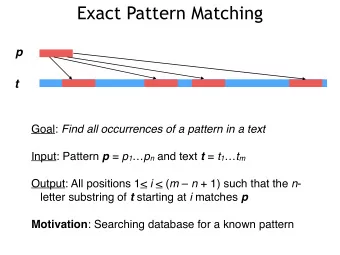
Backward search BWT: T $ T C C G A Ref: A T C C G T $ Query: C G T 00 BackwardSearch (BWT, Q) { tag tag 01 int low = 0 ; 02 int high = max_occ ; 03 for ( int i = len ; i >= 0 ; i --){ 04 low = LFM( BWT [ low /4 ] , Q [ i ] , low ); BWT BWT 05 high =LFM( BWT [ high /4 ] , Q [ i ] , high ); if ( low >= high ) return ; 06 07 } 09 int LFM( BWT [ x /4], Q[index] , x ){ 08 } 10 int co = 0 ; 11 int tag = TAG [ Q[index] ]; 12 for ( int j = 0 ; j < x % 4 ; j ++) 13 if ( BWT [ x /4][ j ] == s ) co ++; 14 return co + tag ; 15 } 48
Problem: operations in backward search • Random memory accesses due to pointer chasing 04 low = LFM( BWT [ low /4 ] , Q [ i ] , low ); 05 high =LFM( BWT [ high /4 ] , Q [ i ] , high ); Processing-in-memory! 49
Problem: operations in backward search • Random memory accesses due to pointer chasing 04 low = LFM( BWT [ low /4 ] , Q [ i ] , low ); 05 high =LFM( BWT [ high /4 ] , Q [ i ] , high ); Processing-in-memory! • Counting a symbol S in a string 12 for ( int j = 0 ; j < x % 4 ; j ++) 13 if ( BWT [ x /4][ j ] == s ) c ++; Hamming distance between “SSSSS” and the string Hardware/algorithm co- design → operation parallelism ↑ 50
Solution: ReRAM Hamming Distance Unit
ReRAM basics V metal layer SET metal Form oxide RESET metal layer 0 low resistivity high resistivity high resistivity 52
ReRAM-based Hamming Distance Unit Counting G in “ CG ”, Hamming distance between “ GG ” and “ CG ” bit-line Reram array word-line ADC 53
ReRAM-based Hamming Distance Unit Counting G in “ CG ”, Hamming distance between “ GG ” and “ CG ” bit-line Reram array word-line ADC 54
ReRAM-based Hamming Distance Unit Counting G in “ CG ”, Hamming distance between “ GG ” and “ CG ” bit-line Reram array HR word-line HR HR HR ADC 55
ReRAM-based Hamming Distance Unit Counting G in “ CG ”, Hamming distance between “ GG ” and “ CG ” bit-line A : 00 C : 01 Reram array G : 10 HR T : 11 word-line HR HR HR ADC 56
ReRAM-based Hamming Distance Unit Counting G in “ CG ”, Hamming distance between “ GG ” and “ CG ” G G bit-line A : 00 1 0 1 0 C : 01 Reram array G : 10 0 HR T : 11 C 1 word-line HR 1 HR G HR 0 ADC 57
ReRAM-based Hamming Distance Unit Counting G in “ CG ”, Hamming distance between “ GG ” and “ CG ” G G bit-line A : 00 1 0 1 0 C : 01 Reram array G : 10 0 HR LR T : 11 C 1 word-line LR HR 1 HR G HR 0 2 1 ADC 58
ReRAM-based Hamming Distance Unit Counting G in “ CG ”, Hamming distance between “ GG ” and “ CG ” G G bit-line A : 00 1 0 1 0 C : 01 Reram array G : 10 0 HR HR LR T : 11 C 1 word-line HR LR HR 1 HR HR G HR HR 0 ADC 59
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.