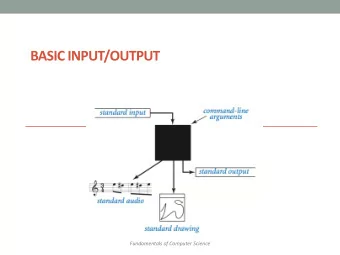
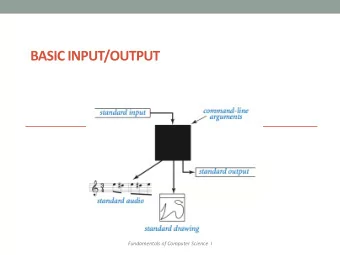
recap: Three Learning Principles Scientist 1 Scientist 2 Scientist 3 resistivity ρ resistivity ρ resistivity ρ Occam’s razor: simpler is better; falsifiable. Learning From Data temperature T temperature T temperature T Lecture 15 not falsifiable falsifiable Reflecting on Our Path - Epilogue to Part I Sampling bias: ensure that training and test What We Did distributions are the same, or else acknowl- The Machine Learning Zoo edge/account for it. You cannot sample from one Moving Forward bin and use your estimates for another bin. M. Magdon-Ismail CSCI 4100/6100 ? ? Data snooping: you are charged for h ∈ H every choice influenced by D . Choose the Data learning process (usually H ) before looking at D . g ? We know the price of choosing g from H . your choices − → g D � A M Reflecting on Our Path : 2 /11 c L Creator: Malik Magdon-Ismail Zen Moment − → Our Plan 1. What is Learning? � Output g ≈ f after looking at data ( x n , y n ). 2. Can We do it? E in ≈ E out simple H , finite d vc , large N E in ≈ 0 good H , algorithms 3. How to do it? Linear models, nonlinear transforms Algorithms: PLA, pseudoinverse, gradient descent concepts theory 4. How to do it well? practice Overfitting: stochastic & deterministic noise Cures: regularization, validation. Zen Moment 5. General principles? Occams razor, sampling bias, data snooping 6. Advanced techniques. 7. Other Learning Paradigms. � A c M Reflecting on Our Path : 3 /11 � A c M Reflecting on Our Path : 4 /11 L Creator: Malik Magdon-Ismail Our Plan − → L Creator: Malik Magdon-Ismail LFD Jungle − →
Learning From Data: It’s A Jungle Out There Navigating the Jungle: Theory THEORY stochastic noise K -means stochastic gradient descent exploration overfitting Lloyds algorithm reinforcement Gaussian processes VC-analysis augmented error bootstrapping ill-posed deterministic noise exploitation data snooping bias-variance unlabelled data expectation-maximization distribution free learning Q -learning logistic regression complexity linear regression Rademacher complexity learning curve gan s transfer learning CART bagging Bayesian Bayesian VC dimension Gibbs sampling decision trees nonlinear transformation sampling bias Rademacher neural networks Markov Chain Monte Carlo (MCMC) support vectors Mercer’s theorem SRM adaboost training versus testing extrapolation SVM linear models no free lunch . . graphical models bioinformatics . ordinal regression cross validation HMMs bias-variance tradeoff RBF DEEP LEARNING PAC-learning biometrics error measures active learning data contamination types of learning multiclass MDL perceptron learning random forests unsupervised one versus all weak learning conjugate gradients momentum is learning feasible? RKHS online-learning Levenberg-Marquardt Occam’s razor kernel methods mixture of experts noisy targets boosting weight decay ranking multi-agent systems ensemble methods AIC classification PCA LLE kernel-PCA Big Data permutation complexity regularization primal-dual colaborative filtering semi-supervised learning Boltzmann machine clustering � A M Reflecting on Our Path : 5 /11 � A M Reflecting on Our Path : 6 /11 c L Creator: Malik Magdon-Ismail Theory − → c L Creator: Malik Magdon-Ismail Techniques − → Navigating the Jungle: Techniques Navigating the Jungle: Models THEORY TECHNIQUES THEORY TECHNIQUES VC-analysis VC-analysis Models Methods Models Methods bias-variance bias-variance linear complexity complexity neural networks Bayesian Bayesian SVM Rademacher Rademacher similarity SRM SRM . . Gaussian processes . . . . graphical models bilinear/SVD . . . � A c M Reflecting on Our Path : 7 /11 � A c M Reflecting on Our Path : 8 /11 L Creator: Malik Magdon-Ismail Models − → L Creator: Malik Magdon-Ismail Methods − →
Navigating the Jungle: Methods Navigating the Jungle: Paradigms THEORY TECHNIQUES THEORY TECHNIQUES PARADIGMS VC-analysis VC-analysis Models Methods Models Methods supervised bias-variance bias-variance unsupervised linear linear regularization regularization complexity complexity reinforcement neural networks neural networks validation validation Bayesian Bayesian active SVM SVM aggregation aggregation Rademacher Rademacher online similarity similarity preprocessing preprocessing SRM SRM unlabeled . . . . Gaussian processes . Gaussian processes . . . . . . . transfer learning graphical models graphical models big data bilinear/SVD bilinear/SVD . . . . . . . . . � A M Reflecting on Our Path : 9 /11 � A M Reflecting on Our Path : 10 /11 c L Creator: Malik Magdon-Ismail Paradigms − → c L Creator: Malik Magdon-Ismail Moving Forward − → Moving Forward 1. What is Learning? Output g ≈ f after looking at data ( x n , y n ). 2. Can We do it? E in ≈ E out simple H , finite d vc , large N E in ≈ 0 good H , algorithms 3. How to do it? Linear models, nonlinear transforms Algorithms: PLA, pseudoinverse, gradient descent concepts 4. How to do it well? theory Overfitting: stochastic & deterministic noise practice Cures: regularization, validation. 5. General principles? Occams razor, sampling bias, data snooping 6. Advanced techniques. Similarity, neural networks, SVMs, preprocessing & aggregation 7. Other Learning Paradigms. Unsupervised, reinforcement � A c M Reflecting on Our Path : 11 /11 L Creator: Malik Magdon-Ismail
Recommend
More recommend
Unleash a World of Digital Possibilities—Browse, Share, and Explore Content Without Boundaries