Neural Tangent Kernel Convergence and Generalization in Neural - PowerPoint PPT Presentation
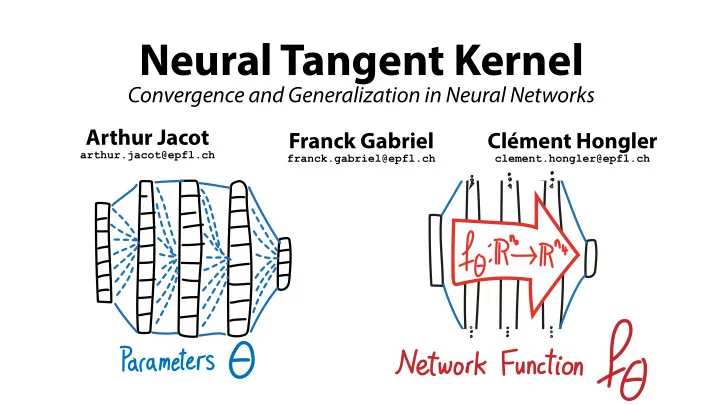
Neural Tangent Kernel Convergence and Generalization in Neural Networks Arthur Jacot Franck Gabriel Clment Hongler arthur.jacot@epfl.ch franck.gabriel@epfl.ch clement.hongler@epfl.ch What happens during training? One step of Gradient
Neural Tangent Kernel Convergence and Generalization in Neural Networks Arthur Jacot Franck Gabriel Clément Hongler arthur.jacot@epfl.ch franck.gabriel@epfl.ch clement.hongler@epfl.ch
What happens during training? One step of Gradient Descent Neural Tangent Kernel: One datapoint x0 Describes the effect of gradient descent on the network function
Determines the trajectory of the network function during training In the Infinite width limit: - Deterministic - Fixed in time - Explicit formula
Kernel methods Neural Networks Kernel Gradient Descent Gradient Descent Positive definite NTK Convergence to a global min. Least-squares loss Kernel ridge regression
What happens inside a very wide network? - The activations of the hidden neurons become independent - The parameters and activations evolve less and less - However all layers learn: The sum of all microscopic changes yields a macroscopic effect
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.