
Mining for Structure Massive increase in both computational power - PowerPoint PPT Presentation
Deep Unsupervised Learning Russ Salakhutdinov Machine Learning Department Carnegie Mellon University Canadian Institute of Advanced Research 1 Mining for Structure Massive increase in both computational power and the amount of data available
Deep Unsupervised Learning Russ Salakhutdinov Machine Learning Department Carnegie Mellon University Canadian Institute of Advanced Research 1
Mining for Structure Massive increase in both computational power and the amount of data available from web, video cameras, laboratory measurements. Images & Video Text & Language Speech & Audio Gene Expression Relational Data/ Product fMRI Tumor region Social Network Recommendation Mostly Unlabeled • Develop statistical models that can discover underlying structure, cause, or statistical correlation from data in unsupervised or semi-supervised way. • Multiple application domains. 2
Mining for Structure Massive increase in both computational power and the amount of data available from web, video cameras, laboratory measurements. Images & Video Text & Language Speech & Audio Gene Expression Deep Learning Models that Relational Data/ Product fMRI Tumor region Social Network support inferences and discover Recommendation structure at multiple levels. Mostly Unlabeled • Develop statistical models that can discover underlying structure, cause, or statistical correlation from data in unsupervised or semi-supervised way. • Multiple application domains. 3
Impact of Deep Learning • Speech Recognition • Computer Vision • Recommender Systems • Language Understanding • Drug Discovery & Medical Image Analysis 4
Building Artificial Intelligence Develop computer algorithms that can: - See and recognize objects around us - Perceive human speech - Understand natural language - Navigate around autonomously - Display human like Intelligence Personal assistants, self-driving cars, etc. 5
Speech Recognition 6
Deep Autoencoder Model Reuters dataset: 804,414 Learned latent code newswire stories: unsupervised European Community Interbank Markets Monetary/Economic Energy Markets Disasters and Accidents Leading Legal/Judicial Economic Indicators Bag of words Government Accounts/ Borrowings Earnings 7 (Hinton & Salakhutdinov, Science 2006)
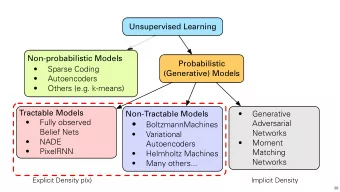
Unsupervised Learning Non-probabilistic Models Probabilistic (Generative) Models Ø Sparse Coding Ø Autoencoders Ø Others (e.g. k-means) Non-Tractable Models Tractable Models Ø Generative Adversarial Ø Boltzmann Machines Ø Fully observed Networks Ø Variational Belief Nets Ø Moment Matching Autoencoders Ø NADE Networks Ø Helmholtz Machines Ø PixelRNN Ø Many others… Explicit Density p(x) Implicit Density 8
Talk Roadmap • Basic Building Blocks: Sparse Coding Ø Autoencoders Ø • Deep Generative Models Restricted Boltzmann Machines Ø Deep Boltzmann Machines Ø Helmholtz Machines / Variational Autoencoders Ø • Generative Adversarial Networks • Open Research Questions 9
Sparse Coding • Sparse coding (Olshausen & Field, 1996). Originally developed to explain early visual processing in the brain (edge detection). • Objective: Given a set of input data vectors learn a dictionary of bases such that: Sparse: mostly zeros • Each data vector is represented as a sparse linear combination of bases. 10
Sparse Coding Natural Images Learned bases: “Edges” New example = 0.8 * + 0.3 * + 0.5 * x = 0.8 * + 0.3 * + 0.5 * [0, 0, … 0.8 , …, 0.3 , …, 0.5 , …] = coefficients (feature representation) 11 Slide Credit: Honglak Lee
Sparse Coding: Training • Input image patches: • Learn dictionary of bases: Reconstruction error Sparsity penalty • Alternating Optimization: 1. Fix dictionary of bases and solve for activations a (a standard Lasso problem). 2. Fix activations a , optimize the dictionary of bases (convex QP problem). 12
Sparse Coding: Testing Time • Input: a new image patch x* , and K learned bases • Output: sparse representation a of an image patch x*. = 0.8 * + 0.3 * + 0.5 * x* = 0.8 * + 0.3 * + 0.5 * [0, 0, … 0.8 , …, 0.3 , …, 0.5 , …] = coefficients (feature representation) 13
Image Classification Evaluated on Caltech101 object category dataset. Classification Algorithm (SVM) 9K images, 101 classes Learned Features (coefficients) Input Image bases Algorithm Accuracy Baseline (Fei-Fei et al., 2004) 16% PCA 37% Sparse Coding 47% 14 Lee, Battle, Raina, Ng, 2006 Slide Credit: Honglak Lee
Interpreting Sparse Coding a Sparse features a Implicit Explicit g (a) f (x) nonlinear Linear encoding Decoding x’ x • Sparse, over-complete representation a. • Encoding a = f( x ) is implicit and nonlinear function of x . • Reconstruction (or decoding) x’ = g( a ) is linear and explicit. 15
Autoencoder Feature Representation Feed-back, Feed-forward, generative, Decoder Encoder bottom-up top-down path Input Image • Details of what goes insider the encoder and decoder matter! • Need constraints to avoid learning an identity. 16
Autoencoder Binary Features z Decoder Encoder filters D filters W. z= σ (Wx) Dz Linear Sigmoid function function path Input Image x 17
Autoencoder Binary Features z • An autoencoder with D inputs, D outputs, and K hidden units, with K<D. z= σ (Wx) Dz • Given an input x, its reconstruction is given by: Input Image x Decoder Encoder 18
Autoencoder Binary Features z • An autoencoder with D inputs, D outputs, and K hidden units, with K<D. z= σ (Wx) Dz Input Image x • We can determine the network parameters W and D by minimizing the reconstruction error: 19
Autoencoder Linear Features z • If the hidden and output layers are linear, it will learn hidden units that are a linear function of the data and minimize the squared error. z=Wx Wz • The K hidden units will span the same space as the first k principal components. The weight vectors Input Image x may not be orthogonal. • With nonlinear hidden units, we have a nonlinear generalization of PCA. 20
Another Autoencoder Model Binary Features z Encoder filters W. σ ( W T z) z= σ (Wx) Sigmoid Decoder function filters D path Binary Input x • Need additional constraints to avoid learning an identity. • Relates to Restricted Boltzmann Machines (later). 21
Predictive Sparse Decomposition Binary Features z Encoder L 1 Sparsity filters W. D z z= σ (Wx) Sigmoid Decoder function filters D path Real-valued Input x At training time path Encoder Decoder 22 Kavukcuoglu, Ranzato, Fergus, LeCun, 2009
Stacked Autoencoders Class Labels Decoder Encoder Features Decoder Encoder Sparsity Features Decoder Encoder Sparsity Input x 23
Stacked Autoencoders Class Labels • Remove decoders and Encoder use feed-forward part. • Standard, or Features convolutional neural network architecture. Encoder • Parameters can be Features fine-tuned using backpropagation. Encoder Input x 24
Deep Autoencoders Decoder 30 W 4 Top 500 RBM T T W W + � 1 1 8 2000 2000 T T 500 W W + � 2 2 7 1000 1000 W 3 T T 1000 W W + � RBM 3 3 6 500 500 T T W W + � 4 4 5 30 Code layer 30 1000 W W + � 4 4 4 W 2 500 500 2000 RBM W W + � 3 3 3 1000 1000 W W + � 2 2 2 2000 2000 2000 W W W + � 1 1 1 1 RBM Encoder Pretraining Unrolling Fine � tuning 25
Deep Autoencoders • 25x25 – 2000 – 1000 – 500 – 30 autoencoder to extract 30-D real- valued codes for Olivetti face patches. • Top : Random samples from the test dataset. • Middle : Reconstructions by the 30-dimensional deep autoencoder. • Bottom : Reconstructions by the 30-dimentinoal PCA. 26
Information Retrieval 2-D LSA space European Community Interbank Markets Monetary/Economic Energy Markets Disasters and Accidents Leading Legal/Judicial Economic Indicators Government Accounts/ Borrowings Earnings • The Reuters Corpus Volume II contains 804,414 newswire stories (randomly split into 402,207 training and 402,207 test). • “Bag-of-words” representation: each article is represented as a vector containing the counts of the most frequently used 2000 words in the training set. 27 (Hinton and Salakhutdinov, Science 2006)
Semantic Hashing European Community Monetary/Economic Address Space Disasters and Accidents Semantically Similar Documents Semantic Hashing Government Function Borrowing Energy Markets Document Accounts/Earnings • Learn to map documents into semantic 20-D binary codes. • Retrieve similar documents stored at the nearby addresses with no search at all. 28 (Salakhutdinov and Hinton, SIGIR 2007)
Searching Large Image Database using Binary Codes • Map images into binary codes for fast retrieval. • Small Codes, Torralba, Fergus, Weiss, CVPR 2008 • Spectral Hashing, Y. Weiss, A. Torralba, R. Fergus, NIPS 2008 • Kulis and Darrell, NIPS 2009, Gong and Lazebnik, CVPR 20111 • Norouzi and Fleet, ICML 2011, 29
Talk Roadmap • Basic Building Blocks: Sparse Coding Ø Autoencoders Ø • Deep Generative Models Restricted Boltzmann Machines Ø Deep Boltzmann Machines Ø Helmholtz Machines / Variational Autoencoders Ø • Generative Adversarial Networks 30
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.