
Lexical analysis CS440/540 Lexical Analysis Process: converting - PowerPoint PPT Presentation
Lexical analysis CS440/540 Lexical Analysis Process: converting input string (source program) into substrings (tokens) Input: source program Output: a sequence of tokens Also called: lexer, tokenizer, scanner Token and Lexeme
Lexical analysis CS440/540
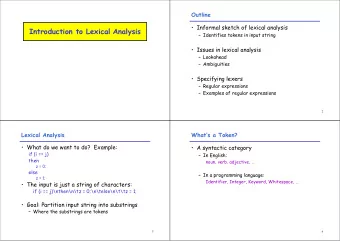
Lexical Analysis • Process: converting input string (source program) into substrings (tokens) • Input: source program • Output: a sequence of tokens • Also called: lexer, tokenizer, scanner
Token and Lexeme • Token: a syntactic category • Lexeme: instance of the token Token Sample lexemes keyword if, else, for, while,… whitespace ‘ ’, ‘ \ t’, ‘ \ n’, … comparison <,>,==,!=,… identifier total, score, name, … number 1, 3.14159, 0, … literal “Super nice cool compiler ”, “ ComS ”, …
Basic design 1. Define a finite set of tokens. • Keyword, whitespace, identifier, … 2. Describe which strings belong to each token • Keyword: “if” or “else” or “for” or … • whitespace: non-empty sequence of blanks, newlines, and tabs • identifier: strings of letters or digits, starting with a letter
Analysis example if (i == j) z = 0; \tif (i == j)\n\t\tz = 0;\n\telse\n\t\tz = 1; else z = 1; • Identifier: ? • Keyword: ? • Comparison: ? • Number: ? • Whitespace: ?
Analysis example if (i == j) z = 0; \tif (i == j)\n\t\tz = 0;\n\telse\n\t\tz = 1; else z = 1; • Identifier: i, j, z • Keyword: if, else • Comparison: == • Number: 0, 1 • Whitespace: ‘ ’, \t, \n
What would you do? • Foo<Bar<Bazz>> • This is nested templates in C++. • However, do you see any conflict?
What would you do? • Foo<Bar<Bazz>> • This is nested templates in C++. • However, do you see any conflict? • Foo<Bar<Bazz >> • cin >> var
Alphabet, String, and Language • Alphabet ( Σ ) • Any finite set of symbols. • String over an alphabet • A finite sequence of symbols drawn from that alphabet. • Language ( 𝑀 ) • Any countable set of strings over some fixed alphabet. • Formally, Let S be a set of characters. A language over S is a set of strings of characters drawn from S. Alphabet Language English characters English sentences ASCII C programs
Operations on Languages • Single character • ′𝑑 ′ = {"c"} • Epsilon • 𝜗 = {""} • Union • 𝐵 + 𝐶 = {𝑡|𝑡 ∈ 𝐵 𝑝𝑠 𝑡 ∈ 𝐶} • Concatenation • 𝐵𝐶 = {𝑏𝑐|𝑏 ∈ 𝐵 𝑏𝑜𝑒 𝑐 ∈ 𝐶} • Iteration • 𝐵 ∗ =∪ 𝑗≥0 𝐵 𝑗 where 𝐵 𝑗 = 𝐵 … 𝑗 𝑢𝑗𝑛𝑓𝑡 … 𝐵
Example • 𝑀 = {𝐵, 𝐶, … , 𝑎, 𝑏, 𝑐, … , 𝑨} , 𝐸 = {0,1, … , 9} • 𝑀 + 𝐸 • set of letters and digits, each of which strings is either one letter or one digit • 𝐵 , , 1 , … • 𝑀𝐸 • set of strings of length two, each consisting of one letter followed by one digit • 𝑑4 , 𝑘8 , 𝑧6 , … • 𝑀 4 • set of all 4-letter strings • 1234 , 7416 , 2592 , …
Regular Expressions • Describing the language by a combination of language operations of some alphabet.
Example • Keyword • “if” or “else” or “for” or … • keyword = ?
Example • Keyword • “if” or “else” or “for” or … • keyword = ‘if’ + ‘else’ + ‘for’ + …
Examples • Integer • non-empty string of digits • digit = ‘0’ + ‘1’ + … + ‘9’ • integer = ?
Examples • Integer • non-empty string of digits • digit = ‘0’ + ‘1’ + … + ‘9’ • integer = digit digit* • Definition • A*: zero or more of the preceding element • A + =AA*: one or more of the preceding element • integer = digit + • A?: zero or one of the preceding element
Examples • Identifier • Strings of letters or digits, starting with a letter • letter = ‘A’ + … + ‘Z’ + ‘a’ + … + ‘z’ • digit = ‘0’ + ‘1’ + … + ‘9’ • identifier = ?
Examples • Identifier • Strings of letters or digits, starting with a letter • letter = ‘A’ + … + ‘Z’ + ‘a’ + … + ‘z’ • digit = ‘0’ + ‘1’ + … + ‘9’ • identifier = letter (letter + digit)*
More Examples • Phone number • (515)-294-8813 • Σ =? • 𝑏𝑠𝑓𝑏 =? • 𝑓𝑦𝑑ℎ𝑏𝑜𝑓 =? • 𝑞ℎ𝑝𝑜𝑓 =? • phone number = ?
More Examples • Phone number • (515)-294-8813 • Σ = 𝑒𝑗𝑗𝑢𝑡 ∪ {−, , } • 𝑏𝑠𝑓𝑏 = 𝑒𝑗𝑗𝑢 3 • 𝑓𝑦𝑑ℎ𝑏𝑜𝑓 = 𝑒𝑗𝑗𝑢 3 • 𝑞ℎ𝑝𝑜𝑓 = 𝑒𝑗𝑗𝑢 4 • phone number = ‘(’area ‘) - ’ exchange ‘ - ’ phone
More Examples • email address • weile@iastate.edu • Σ =? • 𝑜𝑏𝑛𝑓 =? • address = ?
More Examples • email address • weile@iastate.edu • Σ = 𝑚𝑓𝑢𝑢𝑓𝑠𝑡 ∪ {. , @} • 𝑜𝑏𝑛𝑓 = 𝑚𝑓𝑢𝑢𝑓𝑠 + • address = name ‘@’ name ‘.’ name
An algorithm of lexical analysis • Transition diagram • Flowchart with states and edges; each edge is labelled with characters; certain subset of states are marked as “final states.” • Transition from state to state proceeds along edges according to the next input character. • Every string that ends up at a final state is accepted. • If get “stuck”, there is no transition for a given character, it is an error. • Transition diagrams can be easily translated to programs using if or case statements
Implementation state0: c = getchar(); if (isalpha(c)) token += c; goto state1; error(); state1: c = getchar(); if (isalpha(c) || isdigit(c)) token += c; goto state1; if (isdelimiter(c)) goto state2; error(); state2: return(token);
Finite automata • Finite automata • Deterministic Finite Automata (DFAs) • Non-deterministic Finite Automata (NFAs)
Notation • Given a string s and a regxp R, is 𝑡 ∈ 𝑀(𝑆) • There is variation in regular expression notation • Union: A + B ≡ A | B • Option: A + ε ≡ A? • Range: ‘a’+’b’+…+’z’ ≡ [a -z] • Excluded range: complement of [a- z] ≡ [^a -z]
Lexical Spec Regular Expressions (1) 1. Write a rexp for the lexemes of each token • Number = digit + • Keyword = ‘if’ + ‘else’ + … • Identifier = letter (letter + digit)* • OpenPar = ‘(‘ • ClosePar = ‘)’ 2. Construct R, matching all lexemes for all tokens • R = Keyword + Identifier + Number + … • = R 1 + R 2 + R 3 + …
Lexical Spec Regular Expressions (2) 3. Let input be x 1 … x n • For 1 ≤ i ≤ n check • x 1 …x i ∈ L(R) 4. If success, then we know that • x 1 …x i ∈ L(R j ) for some j 5. Remove x 1 …x i from input and go to (3) \tif (i == j)\n\t\tz = 0;\n\telse\n\t\tz = 1;
Ambiguities • What if x 1 …x i ∈ L(R) and also x 1 …x j ∈ L(R)? • note that i ≠ j • Possible rule • pick longest possible string in L(R) • What if x 1 …x i ∈ L(R j ) and also x 1 …x i ∈ L(R k )? • note that j ≠ k • Possible rule • use the listed first
Finite Automata • A finite automaton consists of • An input alphabet Σ • A set of states S • A start state n • A set of accepting states F ⊆ S • A set of transitions state → input state
Finite Automata • Transition • s 1 → a s 2 • Is read: • In state s 1 on input “a” go to state s 2 • If end of input and in accepting state accept • Otherwise reject
Finite Automata State Graphs
Simple examples • A finite automaton that accepts only “1” • A finite automaton accepting any number of 1’s followed by a single 0
And Another Example • Alphabet {0,1} • What language does this recognize?
And Another Example • Alphabet {0,1} • What language does this recognize? • (1*0(0 + 1?|1)) +
Epsilon Moves • Machine can move from state A to state B without reading input
Deterministic and Nondeterministic Automata • Deterministic Finite Automata (DFA) • One transition per input per state • No ε -moves • Nondeterministic Finite Automata (NFA) • Can have multiple transitions for one input in a given state • Can have ε -moves
Execution of Finite Automata • A DFA can take only one path through the state graph • Completely determined by input • NFAs can choose • Whether to make ε -moves • Which of multiple transitions for a single input to take
Acceptance of NFAs • An NFA can get into multiple states • Rule: NFA accepts if it can get to a final state • Input: 100
NFA vs. DFA • NFAs and DFAs recognize the same set of languages (regular languages) • DFAs are faster to execute • DFA can be exponentially larger than NFA • For a given language NFA can be simpler than DFA (1*0(0|1)0*1?) +
Regular Expressions to NFA (1) • For each kind of rexp, define an NFA • Notation: NFA for rexp M • For ε • For input a
Regular Expressions to NFA (2) • For AB • For A | B
Regular Expressions to NFA (3) • For A*
Example: RegExp NFA conversion • Consider the regular expression • (1|0)*1 • The NFA is
Example: RegExp NFA conversion • Consider the regular expression • (1|0)*1 • The NFA is
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.