Latency Trumps All Chris Saari twitter.com/chrissaari blog.chrissaari.com saari@yahoo-inc.com Thursday, November 19, 2009
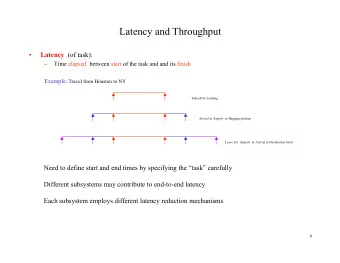
Packet Latency � Time for a packet to get between points A and B � Physical distance + time queued in devices along the way ~60ms Thursday, November 19, 2009
... Thursday, November 19, 2009
Anytime... � ... the system is waiting for data � The system is end to end - Human response time - Network card buffering - System bus/interconnect speed - Interrupt handling - Network stacks - Process scheduling delays - Application process waiting for data from memory to get to CPU, or from disk to memory to CPU - Routers, modems, last mile speeds - Backbone speed and operating condition - Inter-cluster/colo performance Thursday, November 19, 2009
Big Picture k k s i r D o w t e N CPU User Memory Thursday, November 19, 2009
Tubes? Thursday, November 19, 2009
Latency vs. Bandwidth Bandwidth Bits / Second Latency Time Thursday, November 19, 2009
Bandwidth of a Truck Full of Tape Thursday, November 19, 2009
Latency Lags Bandwidth -David Patterson f r- al e d s n f s s- a ts e r n s; n - r s- t- r t - Thursday, November 19, 2009
The Problem � Relative Data Access Latencies, Fastest to Slowest - CPU Registers (1) - L1 Cache (1-2) - L2 Cache (6-10) - Main memory (25-100) --- don’t cross this line, don’t go off mother board! --- - Hard drive (1e7) - LAN (1e7-1e8) - WAN (1e9-2e9) Thursday, November 19, 2009
Relative Data Access Latency Fast Slow CPU Register L1 L2 RAM Thursday, November 19, 2009
Relative Data Access Latency Fast Slow CPU Register L1 L2 RAM Hard Disk Thursday, November 19, 2009
Relative Data Access Latency Lower Higher Register L1 L2 RAM Hard Disk LANFloppy/CD-ROM WAN Thursday, November 19, 2009
CPU Register � CPU Register Latency - Average Human Height Thursday, November 19, 2009
L1 Cache Thursday, November 19, 2009
L2 Cache x 10 x 6 Thursday, November 19, 2009
RAM x 100 x 25 to Thursday, November 19, 2009
Hard Drive 0.4 x equatorial circumference of Earth x 10 M Thursday, November 19, 2009
WAN x 100 M 0.42 x Earth to Moon Distance Thursday, November 19, 2009
To experience pain... � Mobile phone network latency 2-10x that of wired - iPhone 3G 500ms ping x 500 M 2 x Earth to Moon Distance Thursday, November 19, 2009
500ms isn’t that long... Thursday, November 19, 2009
Google SPDY “It is designed specifically for minimizing latency through features such as multiplexed streams, request prioritization and HTTP header compression.” Thursday, November 19, 2009
Strategy Pattern: Move Data Up � Relative Data Access Latencies - CPU Registers (1) - L1 Cache (1-2) - L2 Cache (6-10) - Main memory (25-50) - Hard drive (1e7) - LAN (1e7-1e8) - WAN (1e9-2e9) Thursday, November 19, 2009
Batching: Do it Once Thursday, November 19, 2009
Batching: Maximize Data Locality Thursday, November 19, 2009
Let’s Dig In � Relative Data Access Latencies, Fastest to Slowest - CPU Registers (1) - L1 Cache (1-2) - L2 Cache (6-10) - Main memory (25-100) - Hard drive (1e7) - LAN (1e7-1e8) - WAN (1e9-2e9) Thursday, November 19, 2009
Network � If you can’t Move Data Up, minimize accesses Thursday, November 19, 2009
Network � If you can’t Move Data Up, minimize accesses � Souders Performance Rules � 1) Make fewer HTTP requests - Avoid going halfway to the moon whenever possible Thursday, November 19, 2009
Network � If you can’t Move Data Up, minimize accesses � Souders Performance Rules � 1) Make fewer HTTP requests - Avoid going halfway to the moon whenever possible � 2) Use a content delivery network - Edge caching gets data physically closer to the user Thursday, November 19, 2009
Network � If you can’t Move Data Up, minimize accesses � Souders Performance Rules � 1) Make fewer HTTP requests - Avoid going halfway to the moon whenever possible � 2) Use a content delivery network - Edge caching gets data physically closer to the user � 3) Add an expires header - Instead of going halfway to the moon (Network), climb Godzilla (RAM) or go 40% of the way around the Earth (Disk) instead Thursday, November 19, 2009
Network: Packets and Latency Less data = less packets = less packet loss = less latency Thursday, November 19, 2009
Network � 1) Make fewer HTTP requests � 2) Use a content delivery network � 3) Add an expires header � 4) Gzip components Thursday, November 19, 2009
Disk: Falling of the Latency Cliff Thursday, November 19, 2009
Jim Gray, Microsoft 2006 Tape is Dead Disk is Tape Flash is Disk RAM Locality is King Thursday, November 19, 2009
Strategy: Move Up: Disk to RAM � RAM gets you above the exponential latency line - Linear cost and power consumption = $$$ Main memory (25-50) Hard drive (1e7) Thursday, November 19, 2009
Strategy: Avoidance: Bloom Filters - Probabilistic answer to question if a member is in a set - Constant time via multiple hashes - Constant space bit string - Used in BigTable, Cassandra, Squid Thursday, November 19, 2009
In Memory Indexes � Haystack keeps file system indexes in RAM - Cut disk access per image from 3 to 1 � Search index compression � GFS master node prefix compression of names Thursday, November 19, 2009
Managing Gigabytes -Witten, Moffat, and Bell Thursday, November 19, 2009
SSDs Disk SSD ~ 180 - 200 (15K RPM) I/O Ops / Sec ~ 10K - 100K ~ 70 - 100 Seek times ~ 7 - 3.2 ms ~ 0.085 - 0.05 ms SSDs < 1/5th power consumption of spinning disk Thursday, November 19, 2009
Sequential vs. Random Disk Access - James Hamilton Thursday, November 19, 2009
1TB Sequential Read Thursday, November 19, 2009
1TB Random Read Sunday Monday Tuesday Wednes Thursda Friday Saturda day y y 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Done! Thursday, November 19, 2009
Strategy: Batching and Streaming � Fewer reads/writes of large contiguous chunks of data - GFS 64MB chunks Thursday, November 19, 2009
Strategy: Batching and Streaming � Fewer reads/writes of large contiguous chunks of data - GFS 64MB chunks � Requires data locality - BigTable app specified data layout and compression Thursday, November 19, 2009
The CPU Thursday, November 19, 2009
“CPU Bound” CPU access to that Data in RAM data Thursday, November 19, 2009
The Memory Wall Thursday, November 19, 2009
Latency Lags Bandwidth -Dave Patterson Thursday, November 19, 2009
Multicore Makes It Worse! � More cores accelerates the rate of divergence - CPU performance doubled 3x over the past 5 years - Memory performance doubled once Thursday, November 19, 2009
Evolving CPU Memory Access Designs � Intel Nehalem integrated memory controller and new high- speed interconnect � 40 percent shorter latency and increased bandwidth, 4-6x faster system Thursday, November 19, 2009
More CPU evolution � Intel Nehalem-EX - 8 core, 24MB of cache, 2 integrated memory controllers - ring interconnect on-die network designed to speed the movement of data among the caches used by each of the cores � IBM Power 7 - 32MB Level 3 cache � AMD Magny-Cours - 12 cores, 12MB of Level 3 cache Thursday, November 19, 2009
Cache Hit Ratio Thursday, November 19, 2009
Cache Line Awareness � Linked list - Each node as a separate allocation is Bad Thursday, November 19, 2009
Cache Line Awareness � Linked list - Each node as a separate allocation is Bad � Hash table - Reprobe on collision with stride of 1 Thursday, November 19, 2009
Cache Line Awareness � Linked list - Each node as a separate allocation is Bad � Hash table - Reprobe on collision with stride of 1 � Stack allocation - Top of stack is usually in cache, top of the heap is usually not in cache Thursday, November 19, 2009
Cache Line Awareness � Linked list - Each node as a separate allocation is Bad � Hash table - Reprobe on collision with stride of 1 � Stack allocation - Top of stack is usually in cache, top of the heap is usually not in cache � Pipeline processing - Stages of operations on a piece of data do them all at once vs. each stage separately Thursday, November 19, 2009
Cache Line Awareness � Linked list - Each node as a separate allocation is Bad � Hash table - Reprobe on collision with stride of 1 � Stack allocation - Top of stack is usually in cache, top of the heap is usually not in cache � Pipeline processing - Stages of operations on a piece of data do them all at once vs. each stage separately � Optimize for size - Might be faster execution than code optimized for speed Thursday, November 19, 2009
Cycles to Burn � 1) Make fewer HTTP requests � 2) Use a content delivery network � 3) Add an expires header � 4) Gzip components - Use excess compute for compression Thursday, November 19, 2009
Datacenter Thursday, November 19, 2009
Datacenter Storage Heiracrchy - Jeff Dean, Google Thursday, November 19, 2009
Intra-Datacenter Round Trip ~500 miles ~NYC to Columbus, OH x 500,000 Thursday, November 19, 2009
Recommend
More recommend
Unleash a World of Digital Possibilities—Browse, Share, and Explore Content Without Boundaries