JST-CREST Extreme Big Data Project (2013-2018) Future Non-Silo - PowerPoint PPT Presentation
JST-CREST Extreme Big Data Project (2013-2018) Future Non-Silo Extreme Big Data Scientific Apps Ultra Large Scale Massive Sensors and Graphs and Social Large Scale Data Assimilation in Issues
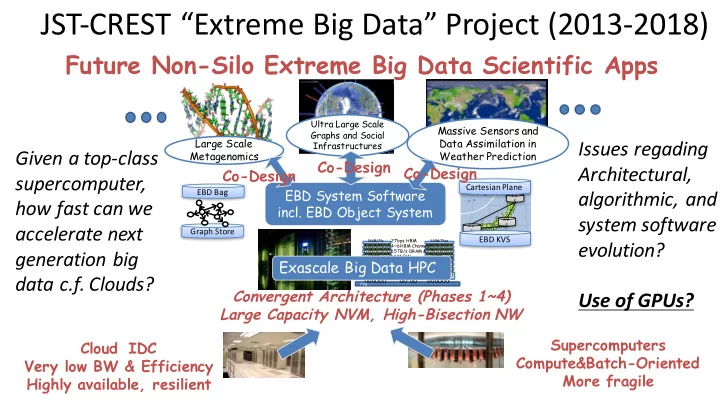
日本地図 ページ 日本地図 JST-CREST “Extreme Big Data” Project (2013-2018) Future Non-Silo Extreme Big Data Scientific Apps Ultra Large Scale Massive Sensors and Graphs and Social Large Scale Data Assimilation in Issues regading Infrastructures Given a top-class Metagenomics Weather Prediction Co-Design Architectural, Co-Design Co-Design supercomputer, Cartesian Plane EBD System Software algorithmic, and EBD Bag KV how fast can we S incl. EBD Object System system software KV accelerate next KV S Graph Store S EBD KVS evolution? 2Tbps HBM NVM/Fla NVM/Flas NVM/Fla sh 4~6HBM Channels NVM/Flas h generation big sh NVM/Fla NVM/Flas h 1.5TB/s DRAM & sh h DRAM NVM BW DRAM Exascale Big Data HPC DRAM DRAM DRAM Low DRAM Low 30PB/s I/O BW Possible High Powered Power Power Ma in CPU 1 Yottabyte / Year CPU data c.f. Clouds? CPU TSV Interposer PCB Convergent Architecture (Phases 1~4) Use of GPUs? Large Capacity NVM, High-Bisection NW Supercomputers Cloud IDC Compute&Batch-Oriented Very low BW & Efficiency More fragile Highly available, resilient
The Graph500 – June 2014 and June 2015 K Computer #1 Tokyo Tech[EBD CREST] Univ. Kyushu [Fujisawa Graph CREST], Riken AICS, Fujitsu 88,000 nodes, 73% total exec 700,000 CPU Cores time wait in 1.6 Petabyte mem 1500 Communi… Elapsed Time (ms) communication 20GB/s Tofu NW 1000 500 0 64 nodes 65536 nodes (Scale 30) (Scale 40) ≫ LLNL-IBM Sequoia 1.6 million CPUs List Rank GTEPS *Problem size is Implementation 1.6 Petabyte mem weak scaling 4 5524.12 November 2013 Top-down only “Brain-class” graph 1 17977.05 June 2014 Efficient hybrid 2 November 2014 Efficient hybrid Hybrid + Node 1 38621.4 June 2015 Compression
Large Scale Graph Processing Using NVM mSATA-SSD Card RAID [Iwabuchi, IEEE BigData2014] 1 . Hybrid-BFS ( Beamer’11 ) 2 . Proposal EBD Algorithm Kernels DRAM NVM Switching two approaches Holds full size of Graph Holds highly accessed data Top-down Bottom-up Load highly accessed graph data before BFS # of frontiers : n frontier , # of all vertices : n all, Parameter : α, β 3. Experiment Limit of DRAM Only (Giga Traversed Edges Per Seconds) 6.0 4.1 Median GigaTEPS 5.0 CPU Intel Xeon E5-2690 × 2 DRAM 256 GB 3.8 4.0 DRAM + EBD-I/O NVM EBD-I/O 2TB × 2 DRAM Only 3.0 × 8 2.0 www.crucial.com/ 4 times larger graph with mSATA mSATA 1.0 6.9 % of degradation ・・・ SSD SSD 0.0 23 24 25 26 27 28 29 30 31 SCALE(# vertices = 2 SCALE ) RAID Card (RAID 0) Ranked 3 rd www.adaptec.com Tokyo’s Institute of Technology GraphCREST-Custom #1 is ranked No.3 in Green Graph500 (June 2014) in the Big Data category of the Green Graph 500 Ranking of Supercomputers with 35.21 MTEPS/W on Scale 31 on the third Green Graph 500 list published at the International Supercomputing Conference, June 23, 2014. Congratulations from the Green Graph 500 Chair
GPU-based Distributed Sorting EBD Algorithm Kernels [Shamoto, IEEE BigData 2014, IEEE Trans. Big Data 2015] • Sorting: Kernel algorithm for various EBD processing • Fast sorting methods – Distributed Sorting: Sorting for distributed system • Splitter-based parallel sort • Radix sort • Merge sort – Sorting on heterogeneous architectures • Many sorting algorithms are accelerated by many cores and high memory bandwidth. • Sorting for large-scale heterogeneous systems remains unclear • We develop and evaluate bandwidth and latency reducing GPU-based HykSort on TSUBAME2.5 via latency hiding – Now preparing to release the sorting library
GPU implementation of splitter- HykSort 1thread based sorting (HykSort) HykSort 6threads HykSort GPU + 6threads x1.4 30 Weak scaling performance (Grand 0.25 • Keys/second(billions) Challenge on TSUBAME2.5) [TB/s] x3.61 20 1 ~ 1024 nodes (2 ~ 2048 GPUs) – 2 processes per node – Each node has 2GB 64bit integer – 10 C.f. Yahoo/Hadoop Terasort: • 0.02[TB/s] x389 Including I/O – 0 Performance prediction 0 500 1000 1500 2000 # of proccesses (2 proccesses per node) K20x x4 faster than K20x HykSort 6threads • PCIe_#: #GB/s bandwidth HykSort GPU + 6threads 60 PCIe_10 of interconnect between Keys/second(billions) PCIe_100 PCIe_200 CPU and GPU PCIe_50 Prediction of our implementation 40 x2.2 speedup compared to 8.8% reduction of overall CPU-based 20 runtime when the implementation when the accelerators work 4 times # of PCI bandwidth faster than K20x 0 increase to 50GB/s 0 500 1000 1500 2000 0 500 1000 1500 2000 # of proccesses (2 proccesses per node)
GPU + NVM + PCIe SSD Sorting our new Xtr2sort library [H.Sato et.al. SC15 Poster] Single Node Xeon - 2 socket 36 cores in-core GPU - 128GB DDR4 - K40 GPU (12GB) - SSD PCIe card Xtr2sort GPU+CPU+NVM (2.4TB) CPU+NVM
Object Storage Design in OpenNVM [Takatsu et al GPC 2015] New interface - Sparse address • space, atomic batch operations Super Region Region Region … … Region 1 2 N and persistent trim Simple design by fixed-size Region • enabled by sparse address space Next Region ID[] and persistent trim 746Kops/sec – Free’ed by persistent trim and no Object Creation Performance with reuse Optimizations – Enough region size to store one object 128 reservations + 32 initializations 800 Optimization techniques for • 600 object creation 2.8x K OPS – Bulk reservation and bulk initialization 400 128 reservations 1.5x XFS 15.6 Kops/s 200 Baseline DirectFS 61.3 Kops/s 0 1 2 4 8 16 32 Proposal 746 Kops/s # thread Fuyumasa Takatsu, Kohei Hiraga, and Osamu Tatebe, “Design of object storage using OpenNVM for high-performance distributed file system”, the 10th International Conference on Green, Pervasive and Cloud Computing (GPC 2015), May 4, 2015
Concurrent B+Tree Index for Native NVM-KVS [Jabri] • Enable range-queries support NVM-KVS supporting range-queries for KVS running natively on In-memory B+ Tree NVM like fusionio ioDrive • Design of Lock-free concurrent B+Tree OpenNVM like KVS Interface Lock-free operations – search, • insert and delete NVM (Fusion-io flash device) • Dynamic rebalancing of the Tree • Nodes to be split or merged are frozen until replaced by new nodes • Asynchronous interface using future/promise in C++11/14
Performance Modeling of a Large Scale Asynchronous Deep Learning System under Realistic SGD Settings Yosuke Oyama 1 , Akihiro Nomura 1 , IkuroSato 2 , Hiroki Nishimura 3 , Yukimasa Tamatsu 3 , and Satoshi Matsuoka 1 1 Tokyo Institute of Technology 2 DENSO IT LABORATORY , INC. 3 DENSO CORPORATION Background Proposal and Evaluation Deep Convolutional Neural Networks (DCNNs) have • We propose a empirical performance model for an ASGD • achieved stage-of-the-art performance in various training system on GPU supercomputers, which predicts machine learning tasks such as image recognition CNN computation time and time to sweep entire dataset Asynchronous Stochastic Gradient Descent (SGD) • – Considering “effective mini-batch size”, time-averaged mini- method has been proposed to accelerate DNN training batch size as a criterion for training quality Our model achieves 8% prediction error for these metrics • It may cause unrealistic training settings and – in average on a given platform, and steadily choose the degrade recognition accuracy on large scale fastest configuration on two different supercomputers systems, due to large non-trivial mini-batch size which nearly meets a target effective mini-batch size 40" 0.9" Top$5&valida,on&error&[%] � 48"GPUs" processed in one iteration 5e+02 sec 35" 10 0.8" Computa(on*(me*[sec] � 1e+03 sec 30" 0.7" 1"GPU" 2e+03 sec Number of samples 8 25" 0.6" 5e+03 sec Better 1e+04 sec 0.5" 20" 6 2e+04 sec 0.4" Model"A" The best configuration 15" 5e+04 sec 4 0.3" 1e+05 sec 10" to achieve the shortest Model"B" Worse than 1 GPU training 0.2" 5" epoch time 2 Model"C" 0.1" 0" 0" 0" 100" 200" 300" 400" 500" 600" 10 20 30 40 1" 2" 3" 4" 5" 6" 7" 8" 9" 10" 11" Number of nodes Epoch � Number*of*samples*processed*in*one*itera(on � Validation Error of ILSVRC 2012 Predicted Epoch Time of ILSVRC 2012 Classification Task: Measured Time (Solid) and Predicted Time (Dashed) Classification Task on Two Platforms: Shaded area indicate the effective mini-batch size of CNN Computation of Three 15-17 Layer Models Trained 11 layer CNN with ASGD method is in 138 ± 25%
Recommend
























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.