
Gradient for Cross-Entropy Loss with Sigmoid For a single example ( x - PowerPoint PPT Presentation
Gradient for Cross-Entropy Loss with Sigmoid For a single example ( x , y ): K L 1 L y k log k ( x ) + (1 y k ) log k ( x ) k =1 s l 1 L s l + 2 w l ij 2 m l =1 i =1
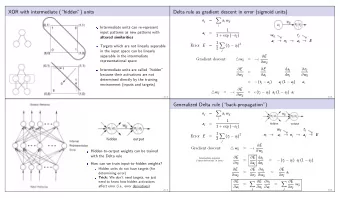
Gradient for Cross-Entropy Loss with Sigmoid For a single example ( x , y ): � K �� � � � � σ L 1 − σ L − y k log k ( x ) + (1 − y k ) log k ( x ) k =1 s l − 1 L s l + λ � 2 � � � � w l ij 2 m l =1 i =1 j =1 s l − 1 � kj σ l − 1 1 sum l w l and σ l j = i = k 1+ e − suml i k =1 ∂σ l ∂ sum l ∂ E = ∂ E + λ j j m w l ∂ w l ∂σ l ∂ sum l ∂ w l ij ij j j ij ∂σ l � � � � 1 1 j = σ l j ( 1 − σ l = 1 − j ) ∂ sum l 1+ e − suml 1+ e − suml j i i � s l − 1 � ∂ sum l � kj σ l − 1 = σ l − 1 j ∂ w l = ∂ w l ∂ w l k i ij ij k =1
Backpropagation in Action ( l − 1) th layer ∂ E ∂σ l j . . σ l +1 1 . ∂σ l ∂ sum l ∂ E = ∂ E + λ j j m w l ∂ w l ∂σ l ∂ sum l ∂ w l ij ij j j ij . . . σ l − 1 i . . . σ l +1 s l +1 . ∂ E ∂σ l sl
Gradient for Cross-Entropy Loss with Sigmoid: ∂ E ∂σ l j For a single example ( x , y ): � K �� � � � � σ L 1 − σ L y k log k ( x ) + (1 − y k ) log k ( x ) − k =1 s l − 1 s l L + λ � 2 � � � � w l ij 2 m l =1 i =1 j =1 ∂ E j = ∂σ l
Gradient for Cross-Entropy Loss with Sigmoid: ∂ E ∂σ l j For a single example ( x , y ): � K �� � � � � σ L 1 − σ L y k log k ( x ) + (1 − y k ) log k ( x ) − k =1 s l − 1 s l L + λ � 2 � � � � w l ij 2 m l =1 i =1 j =1 s l +1 s l +1 ∂ sum l +1 ∂σ l + 1 ∂ E ∂ E ∂ sum l +1 p p ∂ E � � w l +1 = w l +1 j = = since p ∂σ l jp ∂σ l jp ∂ sum l +1 ∂σ l ∂σ l + 1 ∂ sum l + 1 j p p p j p =1 p =1 ∂ E j = ∂σ L
Gradient for Cross-Entropy Loss with Sigmoid: ∂ E ∂σ l j For a single example ( x , y ): � K �� � � � � σ L 1 − σ L y k log k ( x ) + (1 − y k ) log k ( x ) − k =1 s l − 1 s l L + λ � 2 � � � � w l ij 2 m l =1 i =1 j =1 s l +1 s l +1 ∂ sum l +1 ∂σ l + 1 ∂ E ∂ E ∂ sum l +1 p p ∂ E � � w l +1 = w l +1 j = = since p ∂σ l jp ∂σ l jp ∂ sum l +1 ∂σ l ∂σ l + 1 ∂ sum l + 1 j p p p j p =1 p =1 j = − y j j − 1 − y j ∂ E ∂σ L σ L 1 − σ L j
Backpropagation in Action: Identify Sigmoid+Cross-Entropy-speci fi c steps sl +1 ∂σ l + 1 ∂ E p w l +1 ∂ E � = ∂σ l ∂σ l + 1 ∂ sum l + 1 jp j p p p =1 σ l +1 ( l − 1) th layer 1 w l 1 j w l 2 j σ l − 1 1 w l ij w l σ l − 1 s l − 1 j w l 2 1 s l w l 2 s l σ l − 1 i w l is l sl +1 ∂σ l + 1 ∂ E σ l +1 p w l +1 ∂ E � = s l +1 w l ∂σ l ∂σ l + 1 ∂ sum l + 1 sl +1 p σ l − 1 sl s l − 1 s l p sl + 1 p =1 s l − 1
Backpropagation in Action: Identify Sigmoid+Cross-Entropy-speci fi c steps ( l − 1) th layer ∂ E ∂σ l j . . σ l +1 1 . ∂σ l ∂ sum l ∂ E = ∂ E + λ j j m w l ∂ w l ∂σ l ∂ sum l ∂ w l ij ij j j ij . . . σ l − 1 i . . . σ l +1 s l +1 . ∂ E ∂σ l sl
Recall and Substitute: Sigmoid+Cross-Entropy-speci fi c s l − 1 � kj σ l − 1 w l 1 sum l and σ l j = i = k 1+ e − suml i k =1 ∂σ l ∂ sum l ∂ E ij = ∂ E ij + λ m w l j j ij ∂ w l ∂σ l ∂ sum l ∂ w l j j ∂σ l j = σ l j ( 1 − σ l j j ) ∂ sum l ∂ sum l ij = σ l − 1 j ∂ w l i s l +1 ∂σ l + 1 ∂ E j � ∂ E w l +1 j = ∂σ l jp ∂σ l + 1 ∂ sum l + 1 p =1 j j j = − y j j − 1 − y j ∂ E ∂σ L σ L 1 − σ L j
Backpropagation in Action: Sigmoid+Cross-Entropy-speci fi c ( l − 1) th layer ∂ E j , σ l ∂σ l j . σ l +1 . 1 . ∂ E ∂ E j σ l j ( 1 − σ l j ) σ l − 1 + λ m w l ij = ∂ w l ∂σ l i ij . . . σ l − 1 i . . σ l +1 . s l +1 . , σ l ∂ E s l ∂σ l sl
Backpropagation in Action ( l − 1) th layer ∂ E ∂σ l j . σ l +1 . 1 . ij − η ∂ E w l ij = w l ∂ w l ij . . . σ l − 1 i . . σ l +1 . s l +1 . ∂ E ∂σ l sl
The Backpropagation Algorithm: Identify Sigmoid+Cross-Entropy-speci fi c steps Randomly initialize weights w l ij for l = 1 , . . . , L , i = 1 , . . . , s l , j = 1 , . . . , s l +1 . 1 Implement forward propagation to get f w ( x ) for every x ∈ D . 2 Execute backpropagation on any misclassi fi ed x ∈ D by performing gradient descent to 3 minimize (non-convex) E ( w ) as a function of parameters w . y j 1 − y j ∂ E j = − j for j = 1 to s L . 4 j − ∂σ L σ L 1 − σ L For l = L − 1 down to 2: 5 s l +1 ∂ E � σ l + 1 ( 1 − σ l + 1 ) w l +1 ∂ E j = 1 ∂σ l j j jp ∂σ l + 1 j p =1 ∂ E ij = ∂ E j σ l j ( 1 − σ l j ) σ l − 1 + λ m w l 2 ∂ w l ∂σ l i ij w l ij = w l ij − η ∂ E 3 ∂ w l ij Keep picking misclassi fi ed examples until the cost function E ( w ) shows signi fi cant reduction; 6 else resort to some random perturbation of weights w and restart a couple of times.
Challenges in training Deep Neural Networks Actual evaluation function � = Surrogate Loss function (most often) 1 Classi fi cation: F measure � = MLE/Cross-entropy/Hinge Loss Regression: Mean Absolute Error � = Sum of Squares Error Loss Sequence prediction: BLEU score � = Cross-entropy Appropriately exploiting decomposability of surrogate loss functions 2 Stochasticity vs. redundancy, Mini-batch, etc. Local minima, extremely fl uctuating curvature 2 , large gradients, ill-conditioning 3 Momentum (gradient accummulator), Adaptive gradient, Clipping Over fi tting ⇒ Need for generalization 4 Universal Approximation Properties and Depth (Section 6.4): With a single hidden layer of a su ffi cient size, one can represent any smooth function to any desired accuracy The greater the desired accuracy, the more hidden units are required L 1 ( L 2 ) regularization, Early stopping, dropout, etc. 2 see demo
Generalization through Parameter Tying/Sharing, Sparse Representations The Lego World of Neural Networks, Convolutional Neural Networks, Recurrent Neural Networks
Challenges and Opportunities with Neural Networks Local Optima: Only Approximately Correct Solution. But stochastic gradient descent by 1 avoiding even local minima 3 often gives good generalization Training data: Need for large number of training instances. Pre-training 4 2 Extensive Computations and Numerical Precision: With lots of gradient computations and 3 backpropagation, errors can be compounding. Advances in numerical computing tricks/matrix multiplication and GPUs! Architecture Design: How many nodes and edges in each hidden layer? How many layers? 4 Network structures can be overestimated and then regularized using Dropout, i.e. , randomly � l s l across all multiply the output of a node with 0 using a random dropout bit vector d ∈ � nodes: Pr( y | x ) = � d Pr( d ) Pr( y | x , d ) Associating Semantics by Parameter Tying/Sharing & Sparse Representations (Secs 7.9, 7.10): 5 Architectures to suit particular tasks? Architectures can be designed keeping the problem in mind: Examples of CNNs, RNNs, Memory Cells, LSTMs, BiLSTMs, Embeddings, Inception, Attention Networks, etc. 3 See Quiz 2, Problem 3 for when optimal solution can hurt. 4 Unsupervised learning of parameters in the fi rst few layers of the NN
Recap: Regularization Lowering Neural Network bias : Increase (i) the epochs (ii) network size Lowering Neural Network variance : (i) Increase the training set data (ii) A smarter/more Intelligent Neural Network architecture (iii) Regularize Methods of Regularization Norm Penalties (Sec 7.1) & Dropout (Sec 7.12) Bagging and Other Ensemble Methods (Sec 7.11) Domain knowledge based methods Dataset Augmentation (Sec 7.4) Manifold Tangent Classi fi er (Sec 7.14) Optional : Multi-Task (Sec 7.7), Semi-Supervised & Adversarial Learning Parameter Tying & Sharing, Sparse Representations (Secs 7.9, 7.10, Chapters 9 & 10)
Neural Networks: Towards Intelligence Great Expressive power Recall VC dimension Recall from Tutorial 3, Curse of Dimensionality: Given n variables we can have 2 2 n boolean functions Varied degrees of non-linearity using activation functions Catch? Training Scalable Fast Stable Generalizable Intelligent
The Lego Blocks in Modern Deep Learning Depth/Feature Map 1 Patches/Filters (provide for spatial interpolations) 2 Non-linear Activation unit (provided for 3 detection/classi fi cation) Strides (enable downsampling) 4 Padding (shrinking across layers) 5 Pooling (non-linear downsampling) 6 Inception [Optional: Extra slides] 7 RNN, Attention and LSTM (Backpropagation through time 8 and Memory cell) [Optional: Extra slides] Embeddings (Unsupervised learning) [Optional: Extra slides] 9
[Optional] What Changed with Neural Networks? Origin: Computational Model of Threshold Logic from Warren McCulloch and Walter Pitts (1943) Big Leap: For ImageNet Challenge, AlexNet acheived 85 % accuracy (NIPS 2012). Previous best was 75 % (CVPR 2011). Subsequent best was 96.5 % MSRA (arXiv 2015). Comparable to human level accuracy. Challenges involved were varied background, same object with di ff erent colors ( e.g. , cats), varied sizes and postures of same objects, varied illuminated conditions. Tasks like OCR, Speech recognition are now possible without segmenting the word image/signal into character images/signals.
LeNet(1989 and 1998) v/s AlexNet(2012)
Recommend

















![Activation Functions Activation Functions In [1]: % matplotlib inline import d2l from mxnet](https://c.sambuz.com/791682/activation-functions-activation-functions-s.webp)





More recommend
Explore More Topics
Stay informed with curated content and fresh updates.