
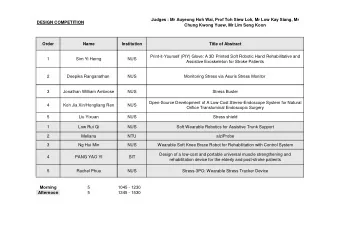
GloVe: Global Vectors for Word Representation Fengyang Zhang, - PowerPoint PPT Presentation
GloVe: Global Vectors for Word Representation Fengyang Zhang, Yutong Wang Presentation Overview 2. GloVe 1. What Model 3. Demo 4. Result is GloVe? Inference What is GloVe? Word Embedding: Word embeddings are in fact a class of
GloVe: Global Vectors for Word Representation Fengyang Zhang, Yutong Wang
Presentation Overview 2. GloVe 1. What Model 3. Demo 4. Result is GloVe? Inference
What is GloVe? Word Embedding: Word embeddings are in fact a class of techniques where individual words are represented as real-valued vectors in a predefined vector space.
One-hot Word Embedding: Simple and easy Relationship
GloVe GloVe is essentially a log-bilinear model with a weighted least-squares objective. It is an unsupervised learning algorithm for obtaining vector representations for words, trained on the non-zero entries of a global word-word co-occurrence matrix.
GloVe: Encoding meaning in vector differences. Crucial insight: Ratio of co-occurence probabilities can encode meaning. K = solid K = gas K = water K = fashion P(k|ice) large small large small P(k|steam) small large large small P(k|ice)/P(k|steam) large small ~1 ~1
Inference The appropriate starting point for word vector learning should be with ratios of co-occurrence probabilities rather than the probabilities themselves.
Inference Log-bilinear model: Vector differences: Think: a = “ice”, b = “steam”
Inference ● X - cooccurrence matrix ● w - word vectors ● b - bias ● ŵ - context word vectors
Demo
Result
Result Word analogy tasks
Result Word similarity tasks
Thanks! Any questions ?
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.