
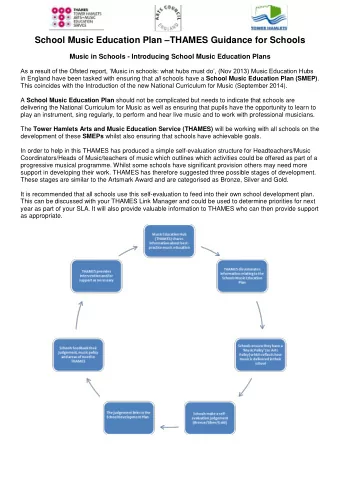
Developing Music Technology for Music & Wearable Technology for - PDF document
9/2/2018 Outline Developing Music Technology for Music & Wearable Technology for Health Health and Learning (MusicRx) Music Technology to Motivate Foreign Ye WANG Language Learning (SLIONS related) School of Computing 1. NUS 48E
9/2/2018 Outline Developing Music Technology for Music & Wearable Technology for Health Health and Learning • (MusicRx) Music Technology to Motivate Foreign Ye WANG • Language Learning (SLIONS related) School of Computing 1. NUS ‐ 48E corpus NUS Graduate School for Integrative Sciences and Engineering 2. Lexical Novelty Score (LNS) National University of Singapore 3. Intelligibility of Sung Lyrics (IoSL) 4. Pronunciation Evaluation of Sung Lyrics www.smcnus.org 5. Perceptual Evaluation of Singing Quality (PESnQ) Music & Wearable Technology for Health (MusicRx) Research Problems: 1) iRACE (2014) 2) Auditory Tempo Stability (2014) 3) Domain specific music recommendation 4) Domain specific music composition 4 1
9/2/2018 Music Technology to Motivate Foreign Language Learning (SLIONS Karaoke) Research Problems: 1) lyric complexity (ISMIR 2015) 2) Singing voice intelligibility (ISMIR 2017) 3) Singing ‐ to ‐ text transcription (ISMIR2017) 4) Domain specific song recommendation Subproject 1: The NUS Sung and Spoken Lyrics Corpus (NUS ‐ 48E): A Quantitative Comparison of Singing and Speech Zhiyan Duan, Haotian Fang, Bo Li, Khe Chai Sim and Ye Wang Participants, and Song Selection Creation of an Annotated Database for Comparative Analysis of Singing and Speech 6 males, 6 females • Varying levels of vocal training • experience (0 – 10+ years) SUNG Soprano, alto, tenor, baritone and • bass Phonetic balance (140 ~ 980 • phoneme per song) SPOKEN Tempo balance (68 ~ 150 bpm) • Popularity • Ease of learning • “Edelweiss, edelweiss Every morning you greet me” 2
9/2/2018 Annotation – Identifying Individual Subjects – A Wide Range of Accents Phonemes, based on CMU’s Dictionary Annotated spoken/sung tracks: 4 (4 tracks We use Audacity to annotate the sound files. • per subject) Total Length: 169 mins • Phoneme Count: 25,474 • Spoken data: alignment of labels from • sung data Motivation Subproject 2: Quantifying Lexical Novelty in Song Lyrics • Second ‐ language acquisition Robert J Ellis, Zhe Xing, Jiakun Fang, & Ye Wang – The complexity of the lyric should be matched to the level of the learner – A search engine that enables finding lyrics based upon topic, mood, and lyric complexity could be used to facilitate L2 learning programs 3
9/2/2018 Approaches to Lyric Novelty Analysis Quantify Lyric Novelty for Music Recommendation? A common text processing technique is to use the inverse document frequency (IDF). We explored this and came up with improvement relevant to lyrics. Herodias and I have led a phantom No more. No way. No more. I say. cavalcade You do it. I don’t. You will. I won’t. An issue we addressed was scaling. Through veiled and pagan history where superstitions reigned And Christendom sought to pervert — “Stop It” by Nomeansno (1985) We observed data via visualization. — “Haunted Shores” by Cradle of Filth (1996) First ‐ pass LNS: IDF M NUS ‐ 48E Lyric Corpus http://www.smcnus.org/lyrics/ There’s Syria, Lebanon, Israel, Jordan I can’t think straight Both Yemens, Kuwait, and Bahrain Help me now before it’s too late The Netherlands, Luxembourg, Belgium, and Now what do I care? Portugal ’Cause we’re going nowhere France, England, Denmark, and Spain — “Going Nowhere” by Cut Copy (2004) — “Yakko’s World” from Anamaniacs (1993) 4
9/2/2018 Automatic Assessment of Intelligibility for Language Learning Subproject 3: Intelligibility of Sung Lyrics: A Pilot Study Karim M. Ibrahim, David Grunberg, Kat Agres, Chitralekha Gupta and Ye Wang Approach Dataset Dataset Features Model Evaluation Selection Training collection Labelling Features Model Dataset Dataset Evaluation collection Selection Training Labelling Confusion matrix of SVM output • 3 classes of 33 9 1 High interpretability 1. Collect a dataset using five genres • SVM Classification 2. Estimate intelligibility of the songs according to human perception 10 30 2 accuracy: 66% Moderate 3. Extract feature set that reflects clarity of song 4 8 3 4. Train Support Vector Machine Low 5. Correlating model estimation to users’ ratings. 5
9/2/2018 Applications • Language immersion is important for learning a foreign language • Recommending music based on intelligibility for learning purposes may aid Subproject 4: in motivation Towards automatic mispronunciation • We intend to make our detection in singing dataset available to the research community Chitralekha Gupta, David Grunberg, Preeti Rao, Ye Wang Overview Problem Statement • Automatic pronunciation error detection in • Learning a second language (L2) South ‐ East Asian English accents singing through singing is shown to be (Malaysian: M, Indonesian: I, Singaporean: S) : effective and is used in pedagogy What are the error patterns observed in non ‐ native • Automatic pronunciation singing compared to non ‐ native speech? evaluation of singing is desirable for L2 learning If only native English speech models are available, can we detect pronunciation errors in non ‐ native English singing, given that we know the singer’s L1 (native language)? • But finding training data is challenging 24 6
9/2/2018 Error patterns in South ‐ East Asian English Subjective analysis accents From speech analysis literature Dataset • 26 sung and 26 spoken songs by 8 ID Error Examples unique subjects (4M, 4F) ‐ 3 /dh/ /d/ thy die; mother moder Indonesian, 3 Singaporean, and 2 C1 Malaysian /th/ /t/ thought taught; nothing noting C2 /t/ /th/ to thu; sitting sithing C3 • All of the error patterns were subjectively rated by 3 English /d/ /dh/ dear dhear C4 speaking judges moment momen CD Word ‐ end consonant deletion ray rray R Rolling /r/ Findings: fool full; sleeping slipping V vowel error • Consonant Deletion and Vowel errors are significantly lower in singing than in speech • Key Insight: Only a subset of the error patterns that occur in speech occur in Are all of these error patterns also observed in singing? singing ‐ suggests a possible learning strategy Mispronunciation detection with limited data System Overview Sub ‐ phonetic Modeling Converted all pronunciation patterns into a dictionary of words with acceptable and unacceptable pronunciation variants for LEX n ah th ih ng American method “Nothing” Dental Fricative /th/ Indonesian s ih cl th ih ng “Sitting” “sithing” Dental Stop /closure/+/th/ “LEX” method 27 7
9/2/2018 Results Contributions • We derive the error patterns in singing compared to Dictionary A Dictionary B speech in South ‐ East Asian English accents and obtain Definition only American American mispronunciation rules for singing English phones phones+modified (L1 ‐ (L2) adapted) phone • Combine acoustic models of sub ‐ phonetic segments Example /th/ /th/, /cl/+/th/ to represent missing L1 phone models F ‐ score for M 0.63 0.67 & S • Incorporate the above two methods in ASR F ‐ score for I 0.33 0.47 framework to detect mispronunciation in singing 29 Application • Automated pronunciation analysis alongside singing may be useful for language learning Subproject 5: Perceptual Evaluation of Singing Quality (PESnQ) Chitralekha Gupta, Haizhou Li, Ye Wang 8
9/2/2018 How do experts perceptually evaluate singing quality? Goal To develop a perceptually ‐ valid score for evaluating singing quality Motivation Reference Good Bad ? ? Rhythm Consistency Such a score could serve as • • a complement to singing lessons Intonation Accuracy • • make singing training more Appropriate Vibrato • accessible to learners Voice Quality • Pitch Dynamic Range • Pronunciation • PESnQ Formulation Results Objective Reference characterization signal PESnQ Cognitive of pitch, Regression score Modeling rhythm, vibrato Test signal etc. Based on the telecommunication standard PESQ [Rix2001] : a localized error in time has a larger subjective Baseline – distance features PESnQ impact than a distributed error Adopting the cognitive modeling theory of PESQ to design a PESnQ score shows 96% improvement over baseline scores in correlating with the music ‐ expert human judges 35 36 9
9/2/2018 Putting all together: SLIONS Project Singing and Listening to Improve Our Natural Speaking Singing can be intrinsically motivating , attention focusing , and Children were tested on their abilities to recall the passage simply enjoyable for learners of all ages. verbatim, pronounce English vowel sounds, and translate target terms from English to Spanish. As predicted, children in the sung condition outperformed children in the spoken condition. The song advantage preserved after a 6-month delay . 10
9/2/2018 Acknowledgements SLIONS Karaoke Prototyping Zhiyan Duan • Michael Barone • Zhe Xing • Rob Ellis • Jiakun Fang • David Grunberg • Karim M. Ibrahim • Kat Agres • Chitralekha Gupta • Douglas Turnbull • Dania Murad • Thank you! Ye Wang wangye@comp.nus.edu.sg www.smcnus.org 11
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.