det ( I + zK ) = i , j = 1 K ( t i , t j ) dt det ( m) (d) n ! - PowerPoint PPT Presentation
Z ENTRUM M ATHEMATIK T ECHNISCHE U NIVERSITT M NCHEN Very Special Functions unbeknownst to Mathematica and kinship numerical explorations of random matrix distributions operator determinants (b) (a) 1000 b 500 Ku ( x ) = a K ( x ,
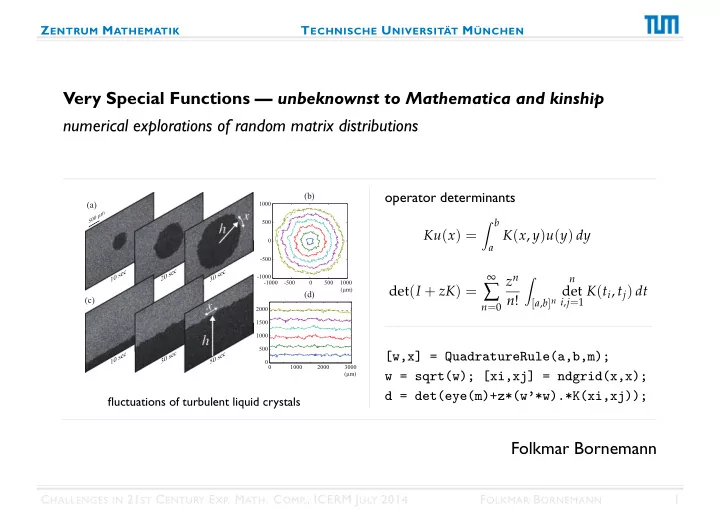
Z ENTRUM M ATHEMATIK T ECHNISCHE U NIVERSITÄT M ÜNCHEN Very Special Functions — unbeknownst to Mathematica and kinship numerical explorations of random matrix distributions operator determinants (b) (a) 1000 � b 500 Ku ( x ) = a K ( x , y ) u ( y ) dy 0 -500 ∞ z n � -1000 n -1000 -500 0 500 1000 ∑ det ( I + zK ) = i , j = 1 K ( t i , t j ) dt det ( µ m) (d) n ! (c) [ a , b ] n n = 0 2000 1500 1000 500 [w,x] = QuadratureRule(a,b,m); 0 0 1000 2000 3000 ( µ m) w = sqrt(w); [xi,xj] = ndgrid(x,x); d = det(eye(m)+z*(w’*w).*K(xi,xj)); fluctuations of turbulent liquid crystals Folkmar Bornemann C HALLENGES IN 21 ST C ENTURY E XP . M ATH . C OMP ., ICERM J ULY 2014 F OLKMAR B ORNEMANN 1
S CALING L IMITS OF R ANDOM M ATRICES Wigner semicircle law (1955) example: GUE 0.5 Gaussian unitary ensemble 0.4 probability density A = randn(n) + i*randn(n); 0.3 A = (A+A’)/2; 0.2 spectrum as n → ∞ ? fluctuations? 0.1 0 − 2 − 1 0 1 2 eigenvalues/ √ n edge: Tracy–Widom distribution F 2 bulk: Gaudin–Mehta distribution E 2 1 0.5 0.8 0.4 probability density probability density 0.6 0.3 0.4 0.2 0.2 0.1 0 0 0 0.5 1 1.5 2 2.5 3 − 5 − 4 − 3 − 2 − 1 0 1 2 normalized eigenvalue spacing normalized maximum eigenvalue universality: fluctuation statistics does only depend on symmetry class (Soshnikov; Tao; L. Erd˝ os, . . . ) C HALLENGES IN 21 ST C ENTURY E XP . M ATH . C OMP ., ICERM J ULY 2014 F OLKMAR B ORNEMANN 2
U NIVERSALITY WITHIN M ATHEMATICS Montgomery–Odlzyko “law” (’73/’87) Montgomery−Odlyzko law 1 0.9 nontrivial zeros 1 2 + i γ n of Riemann ζ -function 0.8 0.7 Probability density large n statistics of the spacings of 0.6 0.5 2 π log γ n γ n 0.4 2 π 0.3 0.2 0.1 → Gaudin–Mehta distribution E 2 0 0 0.5 1 1.5 2 2.5 3 Normalized consecutive spacings fluctuations in Ulam’s problem (Baik/Deift/Johansson ’99) l n = length of longest increasing subsequence of a random permutation of order n l n − 2 √ n → Tracy–Widom distribution F 2 n 1/6 C HALLENGES IN 21 ST C ENTURY E XP . M ATH . C OMP ., ICERM J ULY 2014 F OLKMAR B ORNEMANN 3
U NIVERSALITY : A V ERY S HORT I NTRODUCTION B./Ferrari/Prähofer '08 H. Spohn: Random Matrices and the KPZ Equation (June 1, ’12, HCM, Bonn) Universality: The macroscopic statistics depend on the models, but the microscopic statistics are independent of the details of the systems except the symmetries. — L. Erd˝ os ’10 C HALLENGES IN 21 ST C ENTURY E XP . M ATH . C OMP ., ICERM J ULY 2014 F OLKMAR B ORNEMANN 4
V ERY S PECIAL F UNCTIONS , I NDEED spacing distributions of GUE @ bulk � P ( exactly n eigenvalues in ( 0, s )) = ( − 1 ) n ∂ n � ∂ z n E 2 ( s ; z ) � n ! � z = 1 Jimbo/Miwa/Môri/Sato ’80 Gaudin ’61 � π s � � � � σ ( x ; z ) E 2 ( s ; z ) = det I − zK | L 2 ( 0, s ) E 2 ( s ; z ) = exp − dx x 0 w/ σ -form of Painlevé V w/ kernel ( x σ ′′ ) 2 = 4 ( σ − x σ ′ )( x σ ′ − σ − σ ′ 2 ) K ( x , y ) = sinc ( π ( x − y )) π x + z 2 σ ( x ; z ) ≃ z π 2 x 2 can be expressed in terms of ( x → 0 ) radial prolate spheroidal wave functions C HALLENGES IN 21 ST C ENTURY E XP . M ATH . C OMP ., ICERM J ULY 2014 F OLKMAR B ORNEMANN 5
V ERY S PECIAL F UNCTIONS , V ERY M UCH S O I NDEED spacing distributions of GUE @ soft edge � P ( exactly n eigenvalues in ( s , ∞ )) = ( − 1 ) n ∂ n � ∂ z n F 2 ( s ; z ) � n ! � z = 1 Forrester ’93 Tracy/Widom ’93 � � � ∞ � � F 2 ( s ; z ) = det I − z K | L 2 ( s , ∞ ) s ( x − s ) u ( x ; z ) 2 dx F 2 ( s ; z ) = exp − w/ kernel w/ Painlevé II K ( x , y ) = Ai ( x ) Ai ′ ( y ) − Ai ′ ( x ) Ai ( y ) u ′′ = 2 u 3 + xu x − y u ( x ; z ) ≃ √ z Ai ( x ) ( x → ∞ ) Without the Painlevé representations, the numerical evaluation of the Fredholm determinants is quite involved. — Tracy/Widom ’00 Recently a numerical analyst has shown that the most efficient way to compute spacing distributions in classical RMT is to use Fredholm determinant formulas. — Forrester ’10 C HALLENGES IN 21 ST C ENTURY E XP . M ATH . C OMP ., ICERM J ULY 2014 F OLKMAR B ORNEMANN 6
F REDHOLM D ETERMINANTS VS . P AINLEVÉ T RANSCENDENTS very special functions: nonlinear ode, but integrable Ivar Fredholm (1866–1927) Paul Painlevé (1863–1933) six families of irreducible transcendental functions (1895) determinant of integral operator (1899) � b u ′′ = 6 u 2 + x Ku ( x ) = a K ( x , y ) u ( y ) dy u ′′ = 2 u 3 + xu − α u ′′ = u − 1 u ′ 2 − x − 1 u ′ + x − 1 ( α u 2 + β ) + γ u 3 + δ u − 1 � . ∞ z n � n . ∑ . det ( I + zK ) = i , j = 1 K ( t i , t j ) dt det n ! [ a , b ] n n = 0 C HALLENGES IN 21 ST C ENTURY E XP . M ATH . C OMP ., ICERM J ULY 2014 F OLKMAR B ORNEMANN 7
C OMPARING D IFFERENT N UMERICAL A PPROACHES numerical evaluation of the Tracy–Widom distribution F 2 • via Painlevé II as IVP (backwards) Painlevé II by IVP 0 10 F 2 (x) by IVP Prähofer (’04): 16 digits (1500 internally!) Painlevé II by BVP F 2 (x) by BVP Bejan (’05): 3 digits F 2 (x) by Fredholm −5 10 machine precision Edelman/Persson (’05): 8 digits @ 8.9 sec absolute error • via Painlevé II as BVP −10 10 Tracy/Widom (’94): 10 digits (75 internally!) Dieng (’05): 9 digits @ 3.7 sec −15 10 Driscoll/B./Trefethen (’08): 13 digits @ 1.3 sec • via Fredholm determinant −20 10 −8 −6 −4 −2 0 2 4 6 8 x B. (’10): 15 digits @ 0.69 sec absolute error using IEEE double precision C HALLENGES IN 21 ST C ENTURY E XP . M ATH . C OMP ., ICERM J ULY 2014 F OLKMAR B ORNEMANN 8
T HE N EED FOR C ONNECTION F ORMULAE instability solution of Painlevé II, u ( x ) ≃ √ u xx = 2 u 3 + xu , z Ai ( x ) ( x → ∞ ) , separatrix for z = 1 � IVP highly unstable u � x � u � x � 4 4 2 2 x x � 14 � 12 � 10 � 8 � 6 � 4 � 2 2 4 � 14 � 12 � 10 � 8 � 6 � 4 � 2 2 4 � 2 � 2 u ( x ) with √ z = 1 − 10 − 8 , 1, 1 + 10 − 8 u ( x ) with √ z = 1 − 10 − 16 , 1, 1 + 10 − 16 consequence • calculate F 2 via a BVP solution � connection formula needed: u ( x ) ≃ √ z Ai ( x ) ( x → ∞ ) ⇒ u ( x ) ≃ ? ( x → − ∞ ) C HALLENGES IN 21 ST C ENTURY E XP . M ATH . C OMP ., ICERM J ULY 2014 F OLKMAR B ORNEMANN 9
T HE N EED FOR C ONNECTION F ORMULAE instability solution of Painlevé II, u ( x ) ≃ √ u xx = 2 u 3 + xu , z Ai ( x ) ( x → ∞ ) , separatrix for z = 1 � IVP highly unstable u � x � u � x � 4 4 2 2 x x � 14 � 12 � 10 � 8 � 6 � 4 � 2 2 4 � 14 � 12 � 10 � 8 � 6 � 4 � 2 2 4 � 2 � 2 u ( x ) with √ z = 1 − 10 − 8 , 1, 1 + 10 − 8 u ( x ) with √ z = 1 − 10 − 16 , 1, 1 + 10 − 16 consequence • calculate F 2 via a BVP solution � connection formula needed: √ u ( x ) ≃ Ai ( x ) ( x → ∞ ) ⇒ u ( x ) ≃ − x /2 ( x → − ∞ ) C HALLENGES IN 21 ST C ENTURY E XP . M ATH . C OMP ., ICERM J ULY 2014 F OLKMAR B ORNEMANN 9
Q UADRATURE M ETHOD Nyström (1930) solved a Fredholm equation ( I + zK ) u = f of the 2 nd kind, � b u ( x ) + z a K ( x , y ) u ( y ) dy = f ( x ) ( x ∈ ( a , b )) , using an m -point quadrature formula w/ weights w j & nodes x j Evert Nyström (1895–1960) m ∑ u ( x i ) ≈ u i : u i + z w j K ( x i , x j ) u j = f ( x i ) ( i = 1, . . . , m ) j = 1 straightforward idea (B. ’08) approximate det ( I + zK ) simply by the corresponding n × n determinant � � I + z ( w j K ( x i , x j )) m det i , j = 1 C HALLENGES IN 21 ST C ENTURY E XP . M ATH . C OMP ., ICERM J ULY 2014 F OLKMAR B ORNEMANN 10
C ONVERGENCE R ATE OF THE Q UADRATURE M ETHOD Matlab code [w,x] = QuadratureRule(a,b,m); w = sqrt(w); [xi,xj] = ndgrid(x,x); d = det(eye(m)+z*(w’*w).*K(xi,xj)); Theorem (B. ’10) for quadrature formula of order ν w/ positive weights: • if kernel is C k − 1,1 ([ a , b ] 2 ) , error = O ( ν − k ) ; • if kernel is bounded analytic, there is ρ > 1 w/ error = O ( ρ − ν ) . C HALLENGES IN 21 ST C ENTURY E XP . M ATH . C OMP ., ICERM J ULY 2014 F OLKMAR B ORNEMANN 11
P ROOF idea of proof (Hilbert 1904, B. ’10) m -point quadrature formula � b m ∑ a f ( t ) dt ≈ w k f ( x k ) k = 1 yields � b � b ∞ z n n Fredholm ∑ det ( I + zK ) = dt 1 · · · i , j = 1 K ( t i , t j ) dt n det n ! 1903 a a n = 0 ∞ m m z n n Hadamard ∑ ∑ ∑ ≈ w k 1 · · · i , j = 1 K ( x k i , x k j ) w k n det n ! 1893 n = 0 k 1 = 1 k n = 1 v. Koch = det ( I + zK m ) 1892 w/ the m × m -matrix � � m w 1/2 K ( x i , x j ) w 1/2 K m = i j i , j = 1 C HALLENGES IN 21 ST C ENTURY E XP . M ATH . C OMP ., ICERM J ULY 2014 F OLKMAR B ORNEMANN 12
E XAMPLE 1 Gaudin–Mehta distribution E 2 � � E 2 ( 0; s ) = det I − K | L 2 ( 0, s ) K ( x , y ) = sinc ( π ( x − y )) , 0 10 approximation error for E 2 (0;2) −5 10 −10 10 −15 10 −20 10 0 5 10 15 20 25 dimension stars: Gaudin’s method, dots: Gauss–Legendre, circles: Clenshaw–Curtis C HALLENGES IN 21 ST C ENTURY E XP . M ATH . C OMP ., ICERM J ULY 2014 F OLKMAR B ORNEMANN 13
Recommend



![TDR Assumptions for Pulsed Neutron Yield [/keV] Neutron Yield [/keV] 2500 2000 2000 2500](https://c.sambuz.com/892356/tdr-assumptions-for-pulsed-s.webp)
















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.