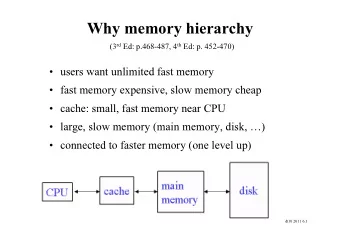
Data Management Systems • Storage Management • Basic principles • Memory hierarchy • The Buffer Cache • Segments and file storage • Management, replacement • Database buffer cache • Relation to overall system • Storage techniques in context Gustavo Alonso Institute of Computing Platforms Department of Computer Science ETH Zürich Storage - Buffer cache 1
Buffer Cache: basic principles • Data must be in memory to be processed but what if all the data does not fit in main memory? • Databases cache blocks in memory, writing them back to storage when dirty (modified) or in need of more space • Similar to OS virtual memory and paging mechanisms but: • The database knows the access patterns • The database can optimize the process much more • The buffer cache is a key component of any database with many implications for the rest of the system Storage - Buffer cache 2
Storage Management Relations, views Application Queries, Transactions (SQL) Logical data (tables, schemas) Logical view (logical data) Record Interface Logical records (tuples) Access Paths Record Access Physical records Physical data in memory Page access Page structure Pages in memory File Access Storage allocation Blocks, files, segments Physical storage 3 Storage - Buffer cache
Disclaimers • The Buffer manager, buffer cache, buffer pool, etc. is a complex system with significant performance implications: • Many tuning parameters • Many aspects affect performance and behavior • Many options to optimize its use and tailor it to particular data • We will cover the basic ideas and discuss the performance implications, we will not be able to cover all possible optimizations or system specifics. Storage - Buffer cache 4
Hash Linked list of buffer headers Latches buckets Buffer header Memory cache … Blocks in cache Storage - Buffer cache 5
Hash Latches buckets Buffer manager: latches • Databases distinguish between a lock and a latch: • Lock: mechanism to avoid conflicting updates to the data by transactions • Latch: mechanism to avoid conflicting updates in system data structures • The buffer cache latches do the following: • Avoid conflicting access to the hash buckets with the block headers • Cover several hash buckets (tunable parameter) • Why not a latch per bucket or per block header? • Way too many!!! • Very common trade-off in databases: how much space to devote to the engine data structures? Storage - Buffer cache 6
Performance issues of latches in buffer cache • When looking for a block, a query or a transaction scans the buffer cache looking to see if the block is in memory. This requires to acquire a latch per block accessed. • A latch can be owned by a single process and latches cover several link lists of block headers! • Contention on these latches may cause performance problems: • Hot blocks Hash • SQL statements that access too many blocks Latches buckets • Similar SQL statements executed concurrently Storage - Buffer cache 7
How to address latch performance issues • Reducing the amount of data in a block so that there is less contention on it (in Oracle, use PCTFREE, PCTUSED) • Configure the database engine with more latches and less buckets per latch (DBAdmin) • Use multiple buffer pools (DBAdmin but also at table creation) • Tune queries to minimize the number of blocks they access (avoid table scans) • Avoid many concurrent queries that access the same data • Avoid concurrent transactions and queries against the same data (see later for how updates are managed to see the problem) Storage - Buffer cache 8
Hash buckets Buffer manager: Hash buckets • The correct linked list where a block header resides is found by hashing on some form of block identifier (e.g., file ID and block number) • After hashing, the linked list is traversed looking for an entry for the corresponding block: • Expensive => lists should be kept short by having as many hash buckets as possible (tunable parameter by DBAdmin) => trade-off Storage - Buffer cache 9
Buffer manager: block headers, linked lists • The blocks that are in memory are located through a block header stored in the corresponding linked list. The header contains quite a bit of information: • Block number • Block type (typically refers to the segment where the block is but now we do not see the segment, only the block) • Format • LSN = log Sequence number (Change Number, Commit number, etc.) timestamp of the last transaction to modify the block • Checksum for integrity Hash • Latches/status flags Linked list of buffer headers buckets • Buffer replacement information (see later) Buffer header Storage - Buffer cache 10
Status of a block • Relevant for the management of the buffer are the following states • Pinned: if a block is pinned, it cannot be evicted • Usage count: (in some systems), how many queries are using or have used the block, also counts of accesses • Clean/dirty: block has not been / has been modified • This information is used when implementing cache replacement policies Storage - Buffer cache 11
Hash Linked list of buffer headers buckets What is in the linked list Buffer header • Depending on how the database engine works, the nature of the blocks in the linked list might be different. Besides normal blocks, one can have, for instance (Oracle): • Version blocks: every update to a block results in a copy of the block being inserted in the list with the timestamp of the corresponding transaction • Undo blocks/redo blocks (for recovery) • Dirty blocks • Pinned blocks • … • In the case of Oracle, the version blocks play a big role in transaction management and implementing snapshot isolation Storage - Buffer cache 12
Performance implications of version blocks • It is a form of shadow paging: keep the old block in the linked list, add a new entry for the modified block. The same discussion as for shadow paging applies. However: • It allows queries to read data as of the time they started without having to worry about writes => huge advantage for concurrency control (see later) • One can find older versions, enabling reading “in the past” • Facilitates recovery (as in shadow paging) • If many concurrent transactions update the same data, the linked list will grow too long, creating a performance problem (see earlier discussion on latches) Storage - Buffer cache 13
Buffer replacement • Any form of caching requires a cache replacement policy: • What to cache • What to keep in the cache • What to evict from the cache and when • How to avoid thrashing the cache with unnecessary traffic • Similar to OS but, as usual, the database has much more information on how and when the data will be used. • Real systems have many parameters and many options to determine how to manage the buffer cache (and even how to avoid it) Storage - Buffer cache 14
LRU: Least Recently Used Buffer pool 1 2 4 3 LRU List 8 5 6 7 MRU 11 9 10 12 13 16 15 14 Idea is to keep track of when a page was used using a list. When a block is used, it goes on top (Most Recently Used), to decide … T R which blocks to evict, pick those at the bottom (Least Recently Used). P S LRU 15 Storage - Buffer cache
LRU: Least Recently Used Buffer pool LRU List MRU 7 SELECT * FROM T 6 5 4 3 … T R P S LRU … 16 Storage - Buffer cache
LRU: Least Recently Used Buffer pool LRU List MRU 11 SELECT * FROM T 10 SELECT * FROM S 9 8 7 … T R P S LRU 17 Storage - Buffer cache
LRU: Least Recently Used Buffer pool LRU List MRU 16 SELECT * FROM T 15 SELECT * FROM S SELECT * FROM R 14 13 At this point, the cache is full and we cannot bring more blocks from R without removing 12 something: we will remove the block at the … T R end of the list 4 3 2 P S LRU 1 18 Storage - Buffer cache
LRU: Least Recently Used Buffer pool LRU List MRU 1 SELECT * FROM T 16 SELECT * FROM S SELECT * FROM R 15 14 13 … T R 5 4 3 P 2 S LRU 19 Storage - Buffer cache
Buffer pool The trouble with LRU LRU List • LRU is a common strategy in OS but does MRU 1 not really work in databases (although it 16 was used in some systems years ago). 15 • Table scan flooding = a large table loaded 14 to be scanned once will pollute the cache 13 • Index range scan = a range scan using an … T R index will pollute the cache with random pages 5 • Note how we can use the knowledge of 4 what queries do to see the problems. 3 P These two types of queries pollute the S 2 LRU cache but do not benefit from it as they do not reuse the data 20 Storage - Buffer cache 20
Buffer pool Modified LRU LRU List MRU • A way to avoid polluting the 11 10 cache when using data that is rarely accessed is to put those 9 blocks at the bottom of the 8 list rather than at the top. 7 That way they are thrown … T R away quickly. 14 SELECT * FROM T 13 SELECT * FROM S 12 P SELECT * FROM R S 11 LRU • Another modification is to simply not cache large tables 21 Storage - Buffer cache 21
Recommend
More recommend
Unleash a World of Digital Possibilities—Browse, Share, and Explore Content Without Boundaries