
Counting is Hard: Probabilistically Counting Views at Reddit - PowerPoint PPT Presentation
Counting is Hard: Probabilistically Counting Views at Reddit Krishnan Chandra, Data Engineer What is probabilistic counting? How did probabilistic counting help us scale? Overview What issues did we face along the way? What is
Counting is Hard: Probabilistically Counting Views at Reddit Krishnan Chandra, Data Engineer
● What is probabilistic counting? ● How did probabilistic counting help us scale? Overview ● What issues did we face along the way?
What is Reddit? Reddit is the frontpage of the internet A social network where there are tens of thousands of communities around whatever passions or interests you might have It’s where people converse about the things that are most important to them
Reddit by the numbers 4th/7th Alexa Rank (US/World) 330M+ MAU 138K+ Active Communities 10.7M Posts per month 14B Screenviews per month
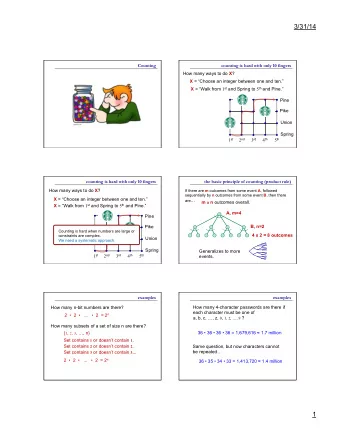
Counting Views
● Includes logged-out users ● Better measure of reach than votes ● Currently exposed to Why Count Views? moderators and content creators
Cat Fist Bumping Cat Walking a Human
Why is Counting Hard?
● Counts are over the life of a post ● The same user should not count multiple times within a short time frame ● Should build in some protections against Product spamming/cheating (similar to votes) Requirements ● Should provide (near) real-time feedback
● Exact counting: ○ Requires storing state per user per post ● Approximate counting: Exact vs. ○ Requires much less state and storage Approximate ○ Provides an estimate of reach within a Counting few percentage points of the exact number
● HyperLogLog (HLL) ○ Hash-based probabilistic algorithm published in 2007 ○ Approximates set cardinality ○ Works well for large cardinalities, but not for small ones HyperLogLog ● HyperLogLog++ (And Friends) ○ Introduced by Google in 2013 ○ Uses sparse and dense HLL representations ○ Switches over to HLL once needed
● Hash table consisting of m registers or buckets, each of width k bits ● Hash the input value, and split the hash value into 2 portions ● First portion (log 2 m bits) used to index to How does a register HLL work? ● Second portion used to count the number of leading zeros and set the register value
Assume: m=8 registers, k=3 bits r0 input 1 1 1 0 0 0 1 1 hash r1 r2 Register# 7 3 leading zeroes Record 3+1=4 into Register# 7 r3 r4 r5 r6 r7 1 0 0 Adapted from HyperLogLog - A Layman’s Overview
● Estimate of cardinality is computed by taking the harmonic mean of the registers and raising 2 to that power ● Intuition: HLL is like flipping a coin! Computing Cardinality ● Largest run of heads gives an estimate of total number of flips
● HLL standard error ○ Number of registers/hash buckets m ○ Standard error = 1.04/sqrt( m ) Counting Error ○ Using Redis’s HLL implementation, standard error is 0.81%!
● 1 HLL per post ● HLL inserts are idempotent! ○ Allows reprocessing data if needed ● How to manage de-duping over short Using HLL to time window? Count Views ○ Store user + truncated timestamp as the value
● Exact counting: ○ User id = 8 byte long ○ ~1.5m users * 8 bytes = 12 MB Space Usage ● HLL (Redis implementation) ○ Max size = 12 KB ○ 0.1% of the exact counting storage
Counting Architecture
1. Consume a stream of view events and filter out spam/bad events 2. For good events, insert into an HLL in real time Architecture 3. Allow clients to consume views values in Goals real time
Server Side Events Anti-Spam App Servers Client Side Events Counting
● Kafka ○ Main message bus for view events ● Redis ○ Used for storing state + HLLs ○ Intended as short term storage ○ Functions as a cache for Cassandra Stream Processing ● Cassandra Infrastructure ○ Used to store the final counts and HLLs in separate column families ○ Intended as long term storage
● Anti-Spam Consumer ○ Consumes the stream of views from Kafka Counting ○ Basic rules engine backed by Redis Application ○ Consumer outputs a decision to a (Part 1) Kafka topic
● Counting Consumer ○ Consumes the decisions topic output by the anti-spam consumer ○ Creates/updates the HLL for the post Counting in Redis. Application ○ Stores both the count and the HLL (Part 2) filter out to Cassandra.
Scaling Challenges
● Problems ○ Rules engine is very memory heavy ○ HLL counting is very CPU-heavy ○ Rules engine data is generally Redis time-bound with expiry ○ HLL data should be kept in Redis as long as possible to avoid reading from Cassandra
● Solutions ○ Separate Redis instances for the 2 parts of the application ○ Different instance types to reflect the different workloads ○ Allkeys-lru expiration on HLLs, volatile-ttl expiration on the rules engine
● Problems ○ 1 row per post - overwritten frequently ○ Read rate on page loads overwhelming the cluster Cassandra ○ Issues with load when “catching up“ ○ Storage grows forever with the number of posts!
● Solutions ○ Updates to the same row in Cassandra throttled to every 10 seconds ○ Read caching ○ Slow the update rate when catching up ○ More disk!
● Views on Reddit skew towards newer posts ○ Allows most views to be served by Redis Observations ○ Keeps read rate on Cassandra very low
● Thanks to HLLs, counting views became much more efficient ○ Current storage usage is ~1TB for a full year of posts! Takeaways ● Delivery was possible in a quarter with an engineering team of 3 (not always full time)
● /u/gooeyblob - Cassandra + Backend ● /u/d3fect - Backend + API Thanks to our team! ● /u/powerlanguage - Product Management
Thanks! Krishnan Chandra krishnan@reddit.com u/shrink_and_an_arch PS: We’re hiring! http://reddit.com/jobs
● View Counting at Reddit (Blog Post from 2017) ● Original HyperLogLog paper References ● Redis blog announcing HLL support ● Google paper announcing HLL++ algorithm ● HyperLogLog - A Layman’s Overview
Recommend





















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.