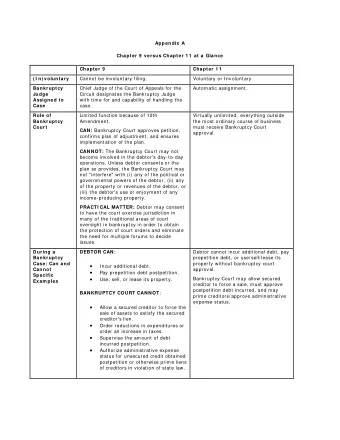
Chapter 2 Methods for Describing Sets of Data
Objectives Describe Data using Graphs Describe Data using Charts
Describing Qualitative Data • Qualitative data are nonnumeric in nature • Best described by using Classes • 2 descriptive measures class frequency – number of data points in a class class relative = class frequency frequency total number of data points in data set class percentage – class relative frequency x 100
Describing Qualitative Data – Displaying Descriptive Measures Summary Table Class Class percentage – class relative frequency x 100 Frequency
Describing Qualitative Data – Qualitative Data Displays Bar Graph
Describing Qualitative Data – Qualitative Data Displays Pie chart
Describing Qualitative Data – Qualitative Data Displays Pareto Diagram
Graphical Methods for Describing Quantitative Data The Data Percentage of Revenues Spent on Research and Development Company Percentage Company Percentage Company Percentage Company Percentage 1 13.5 14 9.5 27 8.2 39 6.5 2 8.4 15 8.1 28 6.9 40 7.5 3 10.5 16 13.5 29 7.2 41 7.1 4 9.0 17 9.9 30 8.2 42 13.2 5 9.2 18 6.9 31 9.6 43 7.7 6 9.7 19 7.5 32 7.2 44 5.9 7 6.6 20 11.1 33 8.8 45 5.2 8 10.6 21 8.2 34 11.3 46 5.6 9 10.1 22 8.0 35 8.5 47 11.7 10 7.1 23 7.7 36 9.4 48 6.0 11 8.0 24 7.4 37 10.5 49 7.8 12 7.9 25 6.5 38 6.9 50 6.5 13 6.8 26 9.5
Graphical Methods for Describing Quantitative Data Dot Plot
Graphical Methods for Describing Quantitative Data Stem-and-Leaf Display
Graphical Methods for Describing Quantitative Data Histogram
Graphical Methods for Describing Quantitative Data More on Histograms Number of Observations in Data Set Number of Classes Less than 25 5-6 25-50 7-14 More than 50 15-20
Summation Notation Used to simplify summation instructions Each observation in a data set is identified by a subscript x 1 , x 2 , x 3 , x 4 , x 5 , …. x n Notation used to sum the above numbers together is n x x x x x x i n 1 2 3 4 i 1
Summation Notation Data set of 1, 2, 3, 4 2 4 4 Are these the same? and 2 x x i i i 1 i 1 4 2 2 2 2 2 1 4 9 16 30 x x x x x i 1 2 3 4 i 1 2 4 2 2 2 x x x x x 1 2 3 4 10 100 i 1 2 3 4 i 1
Numerical Measures of Central Tendency • Central Tendency – tendency of data to center about certain numerical values • 3 commonly used measures of Central Tendency Mean Median Mode
Numerical Measures of Central Tendency The Mean • Arithmetic average of the elements of the data set • Sample mean denoted by x • Population mean denoted by • Calculated as n n x x i i and 1 1 i i x n n
Numerical Measures of Central Tendency The Median • Middle number when observations are arranged in order • Median denoted by m n • Identified as the observation if n is 0 . 5 2 n n odd, and the mean of the and 1 2 2 observations if n is even
Numerical Measures of Central Tendency The Mode • The most frequently occurring value in the data set • Data set can be multi-modal – have more than one mode • Data displayed in a histogram will have a modal class – the class with the largest frequency
Numerical Measures of Central Tendency The Data set 1 3 5 6 8 8 9 11 12 n x i 1 3 5 6 8 8 9 11 12 63 Mean 1 i 7 x 9 9 n or 5 th observation, 8 n Median is the 0 . 5 2 Mode is 8
Numerical Measures of Variability • Variability – the spread of the data across possible values • 3 commonly used measures of Central Tendency Range Variance Standard Deviation
Numerical Measures of Variability The Range • Largest measurement minus the smallest measurement • Loses sensitivity when data sets are large These 2 distributions have the same range. How much does the range tell you about the data variability?
Numerical Measures of Variability The Sample Variance (s 2 ) • The sum of the squared deviations from the mean divided by (n-1). Expressed as units squared n 2 ( ) x x i 2 i 1 s 1 n • Why square the deviations? The sum of the deviations from the mean is zero
Numerical Measures of Variability The Sample Standard Deviation (s) • The positive square root of the sample variance n 2 ( x x ) i 2 i 1 s s n 1 • Expressed in the original units of measurement
Numerical Measures of Variability Samples and Populations - Notation Sample Population s 2 2 Variance Standard s Deviation
Interpreting the Standard Deviation How many observations fit within + n s of the mean? Chebyshev’s Empirical Rule Rule No useful info Approximately 1 s 1 or 68% At least 75% Approximately 2 s 2 or 95% At least 8/9 Approximately 3 s 3 or 99.7%
Interpreting the Standard Deviation You have purchased compact fluorescent light bulbs for your home. Average life length is 500 hours, standard deviation is 24, and frequency distribution for the life length is mound shaped. One of your bulbs burns out at 450 hours. Would you send the bulb back for a refund? Interval Range % of observations % of observations included excluded Approximately Approximately 476 - 524 1 s 68% 32% Approximately Approximately 452 - 548 2 s 95% 5% Approximately Approximately 428 - 572 3 s 99.7% 0.3%
Numerical Measures of Relative Standing Descriptive measures of relationship of a measurement to the rest of the data Common measures: • percentile ranking or percentile score • z-score
Numerical Measures of Relative Standing Percentile rankings make use of the pth percentile The median is an example of percentiles. Median is the 50 th percentile – 50 % of observations lie above it, and 50% lie below it For any p , the pth percentile has p % of the measures lying below it, and (100- p )% above it
Numerical Measures of Relative Standing z-score – the distance between a measurement x and the mean, expressed in standard units Use of standard units allows comparison across data sets x x x z z s
Numerical Measures of Relative Standing More on z-scores Z-scores follow the empirical rule for mounded distributions
Methods for Detecting Outliers Outlier – an observation that is unusually large or small relative to the data values being described Causes • Invalid measurement • Misclassified measurement • A rare (chance) event 2 detection methods • Box Plots • z-scores
Methods for Detecting Outliers Box Plots • based on quartiles, values that divide the dataset into 4 groups Lower Quartile Q L – 25 th percentile • • Middle Quartile - median Upper Quartile Q U – 75 th percentile • • Interquartile Range (IQR) = Q U - Q L
Methods for Detecting Outliers Box Plots Potential Outlier Q U (hinge) Whiskers Median Q L (hinge) Not on plot – inner and outer fences, which determine potential outliers
Methods for Detecting Outliers Rules of thumb • Box Plots – measurements between inner and outer fences are suspect – measurements beyond outer fences are highly suspect • Z-scores – Scores of 3 in mounded distributions ( 2 in highly skewed distributions) are considered outliers
Graphing Bivariate Relationships Bivariate relationship – the relationship between two quantitative variables Graphically represented with the scattergram
The Time Series Plot Time Series Data – data produced and monitored over time Graphically represented with the time series plot Time on x axis Order on x axis
Distorting the Truth with Descriptive Techniques • Graphical techniques – Scale manipulation Same data, different scales
Distorting the Truth with Descriptive Techniques • Graphical techniques – More Scale manipulation
Distorting the Truth with Descriptive Techniques • Graphical techniques – More Scale manipulation
Distorting the Truth with Descriptive Techniques • Numerical techniques – Mismatch of measure of central tendency and distribution shape Use of mean overstates average Use of mean understates average
Distorting the Truth with Descriptive Techniques • Numerical techniques – Discussion of central tendency with no information on variability Which model would you purchase if you knew only the average MPG? Would knowing the standard deviation affect your choice? Why?
Distorting the Truth with Descriptive Techniques • Graphical techniques – Look past the pictures to the data they represent • Numerical techniques – Is measure being used most appropriate for underlying distribution? – Are you provided with information on central tendency and variability?
Recommend
More recommend
Unleash a World of Digital Possibilities—Browse, Share, and Explore Content Without Boundaries