Big Picture: Compilation Process Source program Scanner Lexical - PDF document
Big Picture: Compilation Process Source program Scanner Lexical CSCI: 4500/6500 Programming Analyzer Lexical units, token stream Languages Parser Syntax Analyzer Parse tree Lex & Yacc Intermediate Code Generator Symbol Optimizer
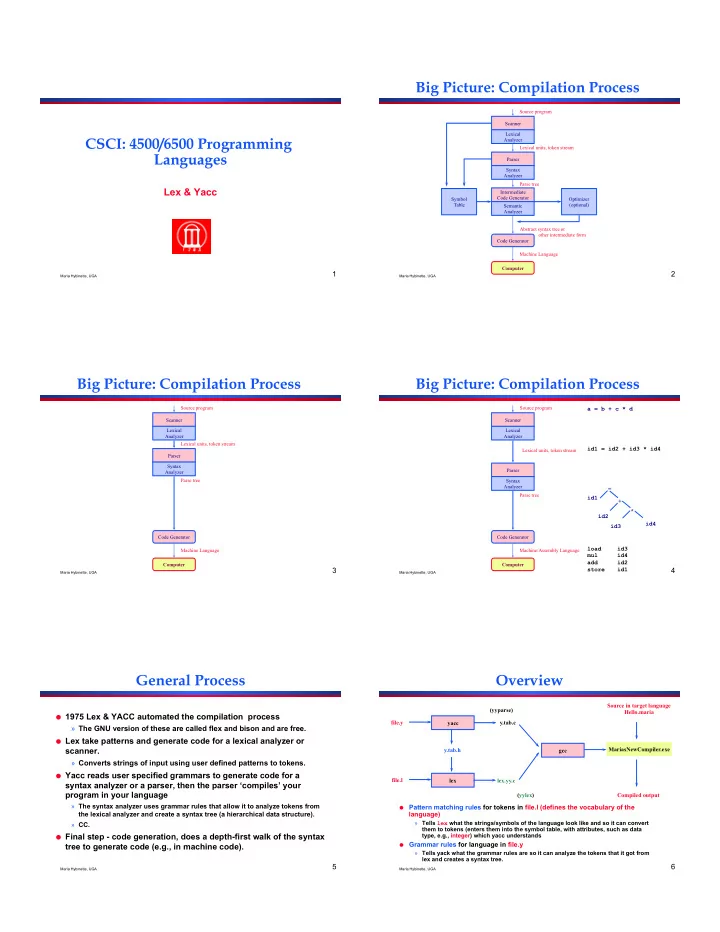
Big Picture: Compilation Process Source program Scanner Lexical CSCI: 4500/6500 Programming Analyzer Lexical units, token stream Languages Parser Syntax Analyzer Parse tree Lex & Yacc Intermediate Code Generator Symbol Optimizer Table (optional) Semantic Analyzer Abstract syntax tree or other intermediate form Code Generator Machine Language Computer 1 2 Maria Hybinette, UGA Maria Hybinette, UGA Big Picture: Compilation Process Big Picture: Compilation Process Source program Source program a = b + c * d Scanner Scanner Lexical Lexical Analyzer Analyzer Lexical units, token stream id1 = id2 + id3 * id4 Lexical units, token stream Parser Syntax Parser Analyzer Parse tree Syntax Analyzer = Parse tree id1 + * id2 id4 id3 Code Generator Code Generator load id3 Machine Language Machine/Assembly Language mul id4 add id2 Computer Computer 3 store id1 4 Maria Hybinette, UGA Maria Hybinette, UGA General Process Overview Source in target language (yyparse) Hello.maria ! 1975 Lex & YACC automated the compilation process file.y yacc y.tab.c » The GNU version of these are called flex and bison and are free. ! Lex take patterns and generate code for a lexical analyzer or scanner. y.tab.h MariasNewCompiler.exe gcc » Converts strings of input using user defined patterns to tokens. ! Yacc reads user specified grammars to generate code for a file.l lex lex.yy.c syntax analyzer or a parser, then the parser ‘compiles’ your program in your language (yylex) Compiled output » The syntax analyzer uses grammar rules that allow it to analyze tokens from ! Pattern matching rules for tokens in file.l (defines the vocabulary of the the lexical analyzer and create a syntax tree (a hierarchical data structure). language) » Tells lex what the strings/symbols of the language look like and so it can convert » CC. them to tokens (enters them into the symbol table, with attributes, such as data ! Final step - code generation, does a depth-first walk of the syntax type, e.g., integer) which yacc understands ! Grammar rules for language in file.y tree to generate code (e.g., in machine code). » Tells yack what the grammar rules are so it can analyze the tokens that it got from lex and creates a syntax tree. 5 6 Maria Hybinette, UGA Maria Hybinette, UGA
Lex and Yacc What is Lex ? ! Lex is a lexical analyzer generator (or tokenizer). It enables you to define the ‘ vocabulary ’ of the Lex and Yacc are tools for generating language parsers ! language. Each do a “ single function ” ! » How?: It automatically “ generates ” a lexer or scanner given a lex specification file as input (.l file) This is what they do: ! ! Purpose: Breaks up the input stream into tokens and it » “ Get a token from the input stream (stream of characters) ” and sees a group of characters that match a key, takes a » “ Parse a sequence of tokens to see if it matches a grammar ” certain action. Yacc generates a parser (another program). » For example consider breaking up a file containing the ! story “ Moby Dick ” into individual words » Calls Lex generated “ tokenizer function ” (yylex()) each time it – Ignore white space wants a token. – Ignore punctuation » You can define actions for particular grammar rules. For ! Generates a C source file, e.g., maria.c, example1.c example, it can: » contains a function called yylex() that obtains the next – print the string “ match ” if the input matched the grammar it valid token in the input stream. expected (or something more complex) » this source file in turn can then be compiled by the C compiler (e.g., gcc) to machine/assembly code. 7 8 Maria Hybinette, UGA Maria Hybinette, UGA Lex ’ s Input File Syntax Lex Syntax ! Lex input file consist of up to three sections ! Lex input file consist of up to three sections ('%% ’ ) » Lex and C definition section that can be used in the ! .c is generated after running %{ middle section. C definitions are wrapped in %{ and ! This part will be %} %} embedded into *.c » Pattern action pairs, where the pattern is a regular ! Substitutions, code and expression and the action is in C syntax start states; will be copied … definitions …. into *.c » Supplementary C-routines (later) %% … patterns rules … %{ example1.l ! Define how to scan (pattern) %% %% and what action to take for #include <stdio> each lexeme that translates to … subroutines … %} a token %% %% ! Any user code for example printf( “ Stop command received ” ); Stop main() calls yylex() one is provided by default. Start printf( “ Start command received ” ); %% 9 10 Maria Hybinette, UGA Maria Hybinette, UGA Regular expressions http://www.cs.uga.edu/~maria/classes/4500-Spring-2012/lexyacc.zip example1.l %{ %{ example2.l #include <stdio.h> #include <stdio.h> %} %} %% %% Stop printf( “ Stop command received ” ); [01234567890]+ printf( “ NUMBER\n ” ); Start printf( “ Start command received ” ); [a-zA-Z][a-zA-Z0-9]* printf( “ WORD\n ” ); %% %% Maximize compatibility to ATT ’ s lex implementation Write to standard output instead of lex.yy.c {atlas:maria:422} flex -l -t example2.l > example2.c {atlas:maria:255} flex -l -t example1.l > example1.c {atlas:maria:423} gcc example2.c -o example2 -lfl {atlas:maria:257} gcc example1.c -o example1 -lfl {atlas:maria:424} example2 {atlas:maria:261} example1 hello WORD hello hello 5lkfsj Start NUMBER Start command received WORD ^D lkjklj3245 WORD You may wonder how the program runs, as we didn't define a main() function. This function is defined for you in libl (liblex) which we compiled in with the -lfl command. Make sure that you do not create zero length matches like '[0-9]*' - your lexer might get confused and start matching empty strings repeatedly.
More Complicated (C-like) logging { Syntax category lame-servers { null; }; category cname { null; }; }; zone “ . ” { type hint; ! Supposing we know what we want the Syntax file “ /etc/bind/db.root ” ; to look more C like ! }; 13 Maria Hybinette, UGA logging input3.txt logging input3.txt { { category lame-servers { null; }; category lame-servers { null; }; category cname { null; }; category cname { null; }; }; }; zone “ . ” zone “ . ” { { type hint; type hint; file “ /etc/bind/db.root ” ; file “ /etc/bind/db.root ” ; }; {atlas:maria:470} example3 < input3.txt }; WORD OBRACE WORD FILENAME OBRACE WORD SEMICOLON EBRACE SEMICOLON WORD WORD OBRACE WORD SEMICOLON EBRACE SEMICOLON example3.l %{ EBRACE SEMICOLON #include <stdio.h> WORD QUOTE FILENAME QUOTE OBRACE %} WORD WORD SEMICOLON %{ WORD QUOTE FILENAME QUOTE SEMICOLON %% #include <stdio.h> EBRACE SEMICOLON %} [a-zA-Z][a-zA-Z0-9]* printf("WORD "); example3.l [a-zA-Z0-9\/.-]+ printf("FILENAME "); %% \" printf( “ QUOTE "); [a-zA-Z][a-zA-Z0-9]* printf("WORD "); \{ printf("OBRACE "); [a-zA-Z0-9\/.-]+ printf("FILENAME "); \" printf("QUOTE "); \} printf("EBRACE "); \{ printf("OBRACE "); ; printf("SEMICOLON "); \} printf("EBRACE "); ; printf("SEMICOLON "); \n printf("\n"); \n printf("\n"); [ \t]+ /* ignore whitespace */; [ \t]+ /* ignore whitespace */; %% %% Patterns: Regular Expressions in Some Rules of the Rules Lex ! The rules section of the Lex/Flex input contains ! Operators: » \ [ ] ^ - ? . * + | ( ) $ / { } % < > a series of rules of the form: » Use ‘escape’ to use an operator as a character, the escape character » pattern action is “\” » Examples: ! Patterns (more next slide): \$ = “$” » Un-indented (starts in the first column) and the action \\ = “\” starts on the same line ! [ ]: Defines ‘ character classes ’ - matches the string once. » Ends or terminates at first non-escaped white space » [ab] – a or b ! Action: » [a-z] – a or b or c or … z » If action is empty and a pattern match » [^a-zA-Z] – ^ negates - any character that is NOT a letter – not the circumflex – then input token is discarded (ignored) is in a character class[], outside a character class ^ means beginning of line. » If the action is enclosed in braces {} then the action ! “.”: may cross multiple lines » Matches all characters except newline (\n) ! A? A* A+: 17 18 » 0 or one instance of A, 0 or more, 1 or more instances of A Maria Hybinette, UGA Maria Hybinette, UGA
Recommend
























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.