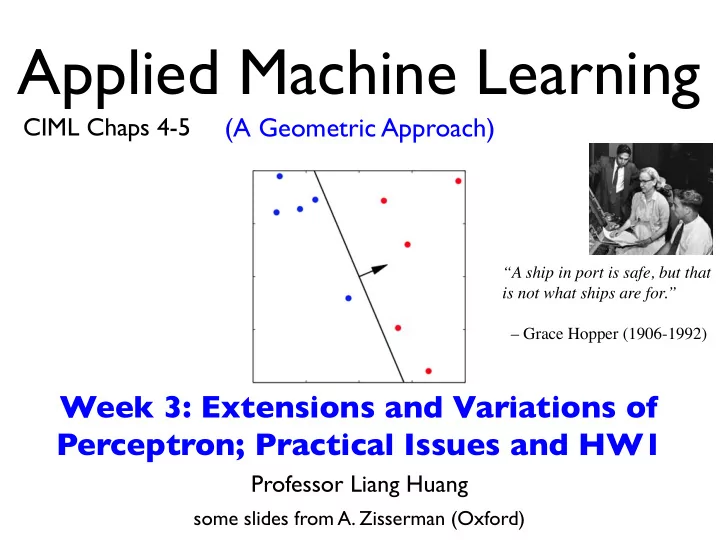
Applied Machine Learning CIML Chaps 4-5 (A Geometric Approach) “A ship in port is safe, but that is not what ships are for.” – Grace Hopper (1906-1992) Week 3: Extensions and Variations of Perceptron; Practical Issues and HW1 Professor Liang Huang some slides from A. Zisserman (Oxford)
Trivia: Grace Hopper and the first bug • Edison coined the term “bug” around 1878 and it had been widely used in engineering • Hopper was associated with the discovery of the first computer bug in 1947 which was a moth stuck in a relay Smithsonian National Museum of American History 2
Week 3: Perceptron in Practice • Problems with Perceptron “A ship in port is safe, but that is not what ships are for.” • doesn’t converge with inseparable data – Grace Hopper (1906-1992) • update might often be too “bold” • doesn’t optimize margin • result is sensitive to the order of examples • Ways to alleviate these problems (without SVM/kernels) • Part II: voted perceptron and average perceptron • Part III: MIRA (margin-infused relaxation algorithm) • Part IV: Practical Issues and HW1 • Part V: “Soft” Perceptron: Logistic Regression 3
Recap of Week 2 δ δ input: training data D x ⊕ ⊕ output: weights w x initialize w ← 0 u · x ≥ δ R while not converged u : k u k = 1 w 0 aa for ( x , y ) ∈ D aaaa if y ( w · x ) ≤ 0 aaaaaa w ← w + y x w “idealized” ML Input x Training Model w Output y “actual” ML deep learning ≈ representation learning Input x feature map ϕ Input x Model w Training Output y Model w Training Output y feature map ϕ 4
Python Demo (requires numpy and matplotlib) $ python perc_demo.py 5
Part II: Voted and Averaged Perceptron vanilla perceptron dev set error a v e r a g e d p e r c e p t r o n v o t e d p e r c e p t r o n 6
Voted/Avg. Perceptron Revives Perceptron batch 1997 +soft-margin Cortes/Vapnik SVM s l e n online approx. r e k + subgradient descent max margin +max margin 2007--2010* minibatch Singer group Pegasos minibatch online 2003 2006 Crammer/Singer Singer group c o n s e r v a t i v e u p d a t e s MIRA aggressive 1959 1962 1969* DEAD 1999 Rosenblatt Novikoff Minsky/Papert Freund/Schapire invention proof book killed it voted/avg: revived i n s e p a r a b l e c a s e 2002 2005* Collins McDonald/Crammer/Pereira structured MIRA structured *mentioned in lectures but optional (others papers all covered in detail) 7
Voted/Avged Perceptron • problem: later examples dominate earlier examples • solution: voted perceptron (Freund and Schapire, 1999) • record the weight vector after each example in D • not just after each update! • and vote on a new example using | D | models • shown to have better generalization power • averaged perceptron (from the same paper) • an approximation of voted perceptron • just use the average of all weight vectors • can be implemented efficiently 8
Voted Perceptron our notation: ( x (1) , y (1) ) v is weight, c is its # of votes r e c t , i n c r e a s e t h e i f c o r n t m o d e l ’ s # o f v o t e s ; c u r r e w i s e c r e a t e a n e w o t h e r l w i t h 1 v o t e m o d e 9
Voted Perceptron our notation: ( x (1) , y (1) ) v is weight, c is its # of votes r e c t , i n c r e a s e t h e i f c o r n t m o d e l ’ s # o f v o t e s ; c u r r e w i s e c r e a t e a n e w o t h e r l w i t h 1 v o t e m o d e 9
Experiments vanilla perceptron dev set error a v e r a g e d p e r c e p t r o n v o t e d p e r c e p t r o n 10
Averaged Perceptron • voted perceptron is not scalable • and does not output a single model • avg perceptron is an approximation of voted perceptron • actually, summing all weight vectors is enough; no need to divide initialize w ← 0; w s ← 0 while not converged w (1) = w (1) = ∆ w (1) aa for ( x , y ) ∈ D aaaa if y ( w · x ) ≤ 0 w (2) = w (2) = ∆ w (1) ∆ w (2) aaaaaa w ← w + y x aaaa w s ← w s + w w (3) = w (3) = ∆ w (1) ∆ w (2) ∆ w (3) output: summed weights w s w (4) = w (4) = ∆ w (1) ∆ w (2) ∆ w (3) ∆ w (4) after each example, not after each update! 11
Efficient Implementation of Averaging • naive implementation (running sum w s ) doesn’t scale • OK for low dim. (HW1); too slow for high-dim. (HW3) • very clever trick from Hal Daumé (2006, PhD thesis) ∆ w ( t ) w ( t ) initialize w ← 0; w a ← 0; c ← 0 while not converged w (1) = w (1) = ∆ w (1) aa for ( x , y ) ∈ D aaaa if y ( w · x ) ≤ 0 c w (2) = w (2) = ∆ w (1) ∆ w (2) aaaaaa w ← w + y x aaaaaa w a ← w a + cy x w (3) = w (3) = ∆ w (1) ∆ w (2) ∆ w (3) aaaa c ← c + 1 output: c w − w a w (4) = w (4) = ∆ w (1) ∆ w (2) ∆ w (3) ∆ w (4) after each update, not after each example! 12
Part III: MIRA • perceptron often makes bold updates (over-correction) • and sometimes too small updates (under-correction) • but hard to tune learning rate x • “just enough” update to correct the mistake? w 0 w 0 w + y � w · x x under-correction k x k 2 w easy to show: x ⊕ w 0 · x = ( w + y � w · x x ) · x = y perceptron w 0 1 k x k k x k 2 � w · x k x k w 0 MIRA margin-infused relaxation x · w k over-correction � x algorithm (MIRA) w k 1 13
Example: Perceptron under-correction x perceptron w 0 w 14
MIRA: just enough w 0 k w 0 � w k 2 min s.t. w 0 · x � 1 x w 0 MIRA minimal change to ensure functional margin of 1 (dot-product w ’ · x =1) k x k 1 perceptron w 0 MIRA ≈ 1-step SVM w functional margin: y ( w · x ) geometric margin: y ( w · x ) k w k 15
MIRA: functional vs geom. margin w 0 k w 0 � w k 2 min 1 = 0 x w · s.t. w 0 · x � 1 x k w 0 k w 0 MIRA minimal change to ensure 1 functional margin of 1 w 0 · x = 0 (dot-product w ’ · x =1) MIRA ≈ 1-step SVM w functional margin: y ( w · x ) geometric margin: y ( w · x ) k w k 16
Optional: Aggressive MIRA · x = 1 0 w 7 0 = w 0 x . · k w 0 k 1 w 0 0 = x 0 x w · • aggressive version of MIRA • also update if correct but not confident enough • i.e., functional margin ( y w · x ) not big enough • p- aggressive MIRA: update if y ( w · x ) < p (0<= p <1) • MIRA is a special case with p= 0: only update if misclassified! • update equation is same as MIRA • i.e., after update, functional margin becomes 1 • larger p leads to a larger geometric margin but slower convergence 17
Demo 18
Demo 19
Part IV: Practical Issues and HW1 “A ship in port is safe, but that is not what ships are for.” – Grace Hopper (1906-1992) • you will build your own linear classifiers for HW1 data 20
HW1: Adult Income >50K? training/dev sets: Age, Sector, Education, Marital_Status, Occupation, Race, Sex, Hours, Country, Target 40, Private, Doctorate, Married-civ-spouse, Prof-specialty, White, Female, 60, United-States, >50K 44, Local-gov, Some-college, Married-civ-spouse, Exec-managerial, Black, Male, 38, United-States, >50K 55, Private, HS-grad, Divorced, Sales, White, Male, 40, England, <=50K test data (semi-blind): 30, Private, Assoc-voc, Married-civ-spouse, Tech-support, White, Female, 40, Canada, ??? • 2 numerical features: age and hours-per-week • option 1: keep them as numerical features • but is older and more hours always better? • option 2: (better) treat them as binary features • e.g., age=22, hours=38, ... • 7 categorical features: convert to binary features • country, race, occupation, etc. • e.g., country=United_States, education=Doctorate,... • perceptron: ~19% dev error, avg. perceptron: ~15% dev error 21
Interesting Facts in HW1 Data • only ~25% positive (>50K); data was from 1994 (~$27K per capita) • education is probably the single most important factor • education=Doctorate is extremely positive (80%) • education=Prof-school is also very positive (75%) • education=Masters is also positive (55%) • education=9th (high school dropout) is extremely negative (6%) • “married” is good (45%), “never married” is extremely bad (5%) • “self-emp-inc” is the best sector (59%), but “self-emp-not-inc” 30% • hours-per-week=1 is 100% positive; country=Iran is 70% positive • exec-managerial and prof-specialty are best occupations (48% / 46%) • interesting combinations (e.g. “edu=Doc and sector=self-emp-inc”: 100%) 22
Recommend
More recommend
Unleash a World of Digital Possibilities—Browse, Share, and Explore Content Without Boundaries