1 Translation model Language model Dictionaries used Languages - PowerPoint PPT Presentation
Motivation Classification of CLIR methods Cross-Language IR at We developed an automatic transliteration query translation method University of Tsukuba method for Japanese and English CLIR document translation method Automatic
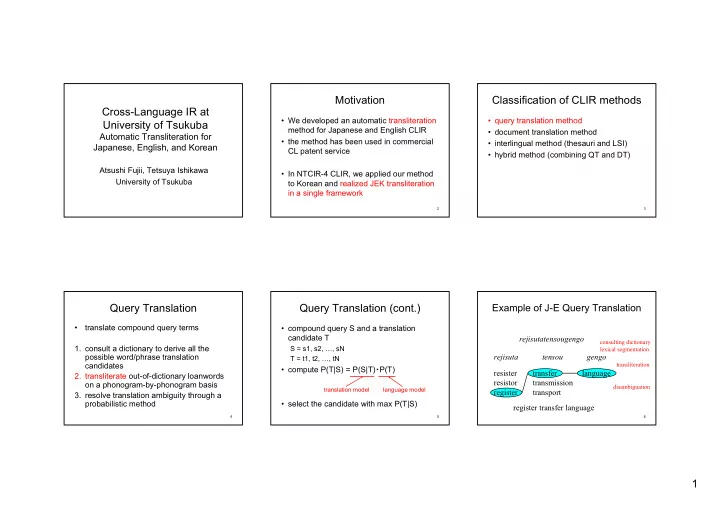
Motivation Classification of CLIR methods Cross-Language IR at • We developed an automatic transliteration • query translation method University of Tsukuba method for Japanese and English CLIR • document translation method Automatic Transliteration for • the method has been used in commercial • interlingual method (thesauri and LSI) Japanese, English, and Korean CL patent service • hybrid method (combining QT and DT) Atsushi Fujii, Tetsuya Ishikawa • In NTCIR-4 CLIR, we applied our method University of Tsukuba to Korean and realized JEK transliteration in a single framework 2 3 Query Translation Query Translation (cont.) Example of J-E Query Translation • translate compound query terms • compound query S and a translation candidate T rejisutatensougengo consulting dictionary 1. consult a dictionary to derive all the S = s1, s2, …, sN lexical segmentation possible word/phrase translation rejisuta tensou gengo T = t1, t2, …, tN candidates transliteration • compute P(T|S) = P(S|T) ・ P(T) resister transfer language 2. transliterate out-of-dictionary loanwords resistor transmission on a phonogram-by-phonogram basis disambiguation translation model language model register transport 3. resolve translation ambiguity through a probabilistic method • select the candidate with max P(T|S) register transfer language 4 5 6 1
Translation model Language model Dictionaries used Languages Name #Entries Type • P(S|T) = Π P(si | ti) • word-based trigram model J-E Cross Language 1M technical si and ti are base words in compound words • 100K vocabulary in a target document • EM algorithm to estimate P(si | ti) in collection E-J Cross Language 1M technical bilingual dictionary • Palmkit is used J-E/E-J EDICT 108K general J-K UNISOFT 213K general K-J UNISOFT 134K general E-K/K-E Cross Language 548K technical 7 8 9 Document retrieval Transliteration method Producing J-E dictionary • out-of-dictionary word S and a 1. extract Japanese Katakana words and • Okapi BM25 transliteration candidate T English translations from J-E dictionary • word and character indexes for Japanese S = s1, s2, …, sN 2. romanize Katakana words • word index for English and Korean T = t1, t2, …, tN • one-to-one mapping b/w Katakan and Roman characters can easily be performed s1 and t1 are letters (substrings of words) 3. correspond romanized Katakana words • compute P(T|S) = P(S|T) ・ P(T) and English on a letter-by-letter basis language model 4. find the best path from a corresponding transliteration model (word unigram) matrix • select the candidate with max P(T|S) 10 11 12 2
Example matrix Producing J-K dictionary Romanizing Korean words • first consonant changes every 21 lines • In EUC-KR, characters are coded • vowel changes every line and repeats every 21 lines independent of pronunciation テ キ ス ト $ • last consonant changes every column t 3 1 2 3 0 • one-to-one mapping b/w Hangul and e 0 0 0 0 0 Roman characters cannot easily be x 1 2 1 1 0 performed t 3 1 2 3 0 $ 0 0 0 0 3 – # of Hangul characters is approx. 11,000 – # of common characters is approx. 2,000 テ te • we used Unicode, in which character is キス x coded according to pronunciation ト t specific Hangul characters can be identified by pronunciation 13 14 15 Experiments (J/E) Experiments (Korean) Example of transliteration <TITLE>, mean average precision (rigid) <TITLE>, mean average precision (rigid) Topic ID Japanese English Korean Languages #Entries w/o w/ Languages w/o transliteration w/ transliteration transliteration transliteration 005 dioxin ダイオキシン 다이옥신 J-K 0.2177 0.2457 J-E 1M 0.2174 0.2182 < < 006 マイケル・ Michael 마이클 조던 K-J 0.1486 0.1746 E-J 1M 0.1250 0.1250 < = Jordan ジョーダン J-E (EDICT) 108K 0.1147 0.1383 E-K 0.2026 0.2153 < < 008 viagra バイアグラ 비아그라 K-E 0.1017 0.1231 E-J (EDICT) 108K 0.0612 0.0857 < < 031 Yugoslavia ユーゴスラビア 유고슬라비아 transliteration was also effective for Korean transliteration was effective for small dictionaries 16 17 18 3
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.