1 Graphs Graphs a a c c Graph algorithms Depth-first search, - PDF document
PhD course Bulk-Synchronous Parallel (BSP) Computing Big Data Analytics Bulk-Synchronous Parallel (BSP) Model [Valiant90] A Bridging Model between abstract PRAM model and real-world parallel computers, to support algorithm development
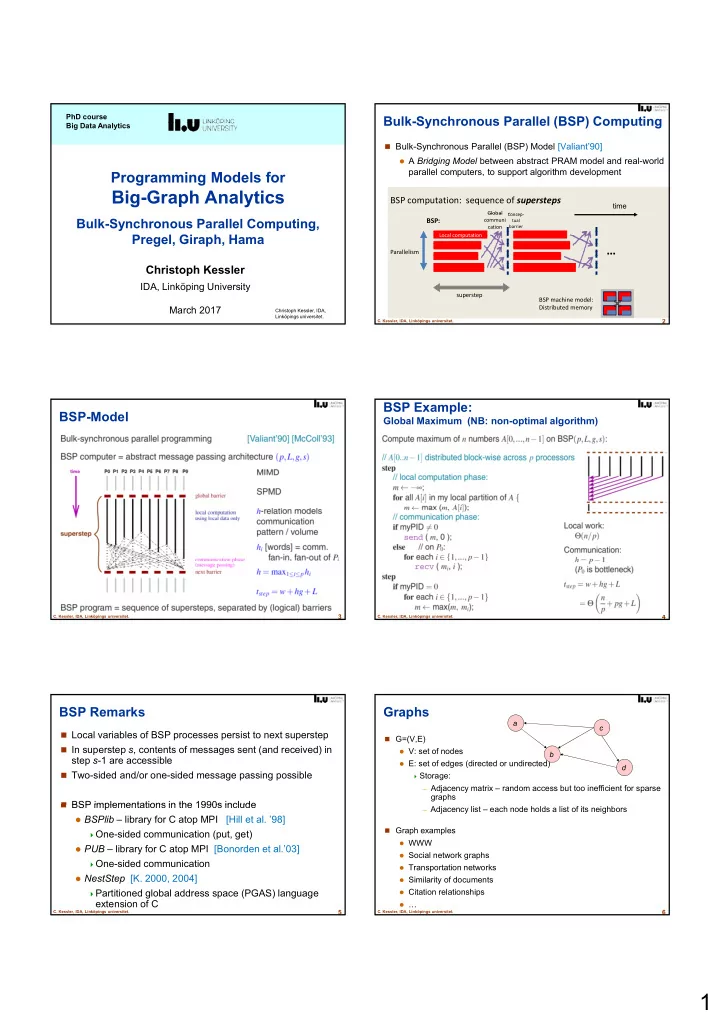
PhD course Bulk-Synchronous Parallel (BSP) Computing Big Data Analytics Bulk-Synchronous Parallel (BSP) Model [Valiant’90] A Bridging Model between abstract PRAM model and real-world parallel computers, to support algorithm development Programming Models for Big-Graph Analytics BSP computation: sequence of supersteps time Global Global Concep- Concep- Bulk-Synchronous Parallel Computing, BSP: communi tual cation barrier Pregel, Giraph, Hama Local computation … Parallelism Christoph Kessler IDA, Linköping University superstep BSP machine model: March 2017 Distributed memory Christoph Kessler, IDA, Linköpings universitet. 2 C. Kessler, IDA, Linköpings universitet. BSP Example: BSP-Model Global Maximum (NB: non-optimal algorithm) 3 4 C. Kessler, IDA, Linköpings universitet. C. Kessler, IDA, Linköpings universitet. BSP Remarks Graphs a c Local variables of BSP processes persist to next superstep G=(V,E) In superstep s , contents of messages sent (and received) in V: set of nodes b step s -1 are accessible E: set of edges (directed or undirected) d Two-sided and/or one-sided message passing possible Storage: – Adjacency matrix – random access but too inefficient for sparse graphs BSP implementations in the 1990s include BSP implementations in the 1990s include – Adjacency list – each node holds a list of its neighbors BSPlib – library for C atop MPI [Hill et al. ’98] Graph examples One-sided communication (put, get) WWW PUB – library for C atop MPI [Bonorden et al.’03] Social network graphs One-sided communication Transportation networks NestStep [K. 2000, 2004] Similarity of documents Partitioned global address space (PGAS) language Citation relationships extension of C … 5 6 C. Kessler, IDA, Linköpings universitet. C. Kessler, IDA, Linköpings universitet. 1
Graphs Graphs a a c c Graph algorithms Depth-first search, Breadth-first search b b Single-source shortest paths Today, many graphs are very large d d All-pairs shortest paths Clustering Page rank How to distribute a graph? How to distribute a graph? Minimum cut / Maximum flow Minimum cut / Maximum flow Usually, partition and distribute the array of vertices Connected components (each vertex with a local value Strongly connected components and its adjacency list of outgoing edges) Hamiltonian, Euler Tour, Traveling Salesman Problem If locality matters in partitioning? … Typical properties Replace default partitioning with a user-defined partitioning Poor locality of memory accesses Graph partitioner Little work per vertex e.g. METIS (used in HPC e.g. for FEM meshes) Changing degree of parallelism 7 8 C. Kessler, IDA, Linköpings universitet. C. Kessler, IDA, Linköpings universitet. Example Example Server 0 Server 1 0 0 4 4 1 1 5 5 2 2 6 6 3 3 Hash vertices over servers. Ex.: S servers, N vertices, hashfn = id , B = ceil( N / S ): • owner (i) = i div B • local index (i) = i mod B 9 10 C. Kessler, IDA, Linköpings universitet. C. Kessler, IDA, Linköpings universitet. Graph Traversal Graph Analytics a c Global analysis of a graph Exploration starts at some vertex Consider each vertex and each edge For each vertex, b consider all its neighbors 2 flavors: d Visit each vertex once and traverse each edge once Compute one value over all vertices / edges Sequential algorithms: E.g. sum-up/maximize/… attribute values over all vertices Depth first search, Breadth first search Depth first search, Breadth first search Compute one value for each vertex / each edge Compute one value for each vertex / each edge Special case: Tree traversals E.g. page rank for each vertex (web page) Much (dynamic) parallelism Often, iterative (unless graph has very special structure) multiple sweeps over the graph Little/no data locality (unless graph has very special structure) Suitable for massively parallel and distributed computation History of exploration (i.e., recursive call stack, visited vertices) Requires a global view (random access) of the graph must be kept dependences / communication for visiting a remote vertex when calculating on a distributed system How to address huge graphs? 11 12 C. Kessler, IDA, Linköpings universitet. C. Kessler, IDA, Linköpings universitet. 2
Pregel Pregel [Malevicz et al . 2010] A framework to process/query large distributed graphs Proprietary (by Google) Kneiphof Pregel is the ”MapReduce” for graphs island Pregel Iterative computations Sequence of BSP supersteps Sequence of BSP supersteps Each BSP superstep is basically a composition of the By Bogdan Giuşcă - Public MapReduce phases (Map, Combine, Sort, Reduce) domain (PD), based on the N image, CC BY-SA 3.0, https://commons.wikimedia.org Attempts to utilize all servers available /w/index.php?curid=112920 K E by partitioning and distributing the graph A multigraph S Leonhard Euler Good for computations touching all vertices / edges 1736: There is no Eulertour (1707-1783), (path traversing each bridge Bad for computations touching only few vertices / edges Swiss exactly once) for Königsberg mathematician nor any other topology with >2 nodes having odd degree. 13 14 C. Kessler, IDA, Linköpings universitet. Source: Wikipedia C. Kessler, IDA, Linköpings universitet. Pregel Example: Maximum vertex value Programming Model States of a vertex Vote to halt Graph Vertices For now, assume 1 BSP a b c d Each with unique identifier (String) Active Inactive processing node per vertex Each with a user-defined value Each with a state in { Active, Inactive } 4 5 3 2 Message received Initial states / values Initially (before superstep 1), every vertex is active Superstep 0: Graph Edges send my value to all neighbors; Each edge can have a user-defined value (e.g., weight) receive from all neighbors One (conceptual) BSP process assigned to each vertex Superstep 1: Not to the edges, by the way… maximize over all received values; Iteratively executing supersteps while active if larger than my value, 5 5 5 3 update it and Two-sided communication with send () and receive () calls send new value to all neighbors; Graph can be dynamic receive from neighbors; Vertices and/or edges can be added or removed in each superstep else vote for halt; Algorithm termination 5 5 5 5 Superstep 2: When all vertices are simultaneously inactive … and there are no messages in transit Superstep 3: Otherwise, go for another superstep … 5 5 5 5 15 16 C. Kessler, IDA, Linköpings universitet. C. Kessler, IDA, Linköpings universitet. Exercise: Connected Components Example: Maximum vertex value based on Maximum (with local accumulation) Now: multiple BSP processes Server 0 Server 1 per server node a b c d message aggregation, local combining 4 5 3 2 0 Initial states / values 0 4 Superstep 0: 4 send my value to all neighbors; receive from all neighbors 1 1 Superstep 1: 5 maximize over all received values; 5 if larger than my value, 5 5 5 3 2 update it and send new value to all neighbors; 2 receive from neighbors; 6 3 else vote for halt; 6 3 5 5 5 5 Superstep 2: … Superstep 3: Initialization … 5 5 5 5 17 18 C. Kessler, IDA, Linköpings universitet. C. Kessler, IDA, Linköpings universitet. 3
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.