
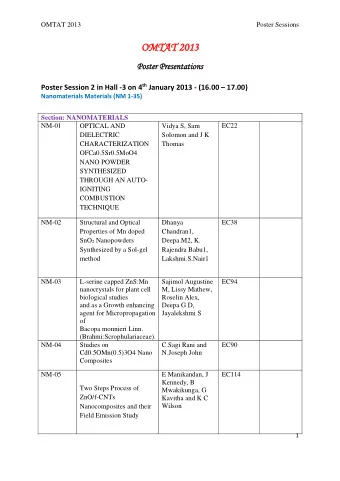
Vine copula mixture models and clustering for non-Gaussian data - PowerPoint PPT Presentation
Vine copula mixture models and clustering for non-Gaussian data Statistical Methods in Machine Learning Prof. Claudia Czado Ozge Sahin <ozge.sahin@tum.de> Bernoulli-IMS One World Symposium August 2020 Finite mixture models k
Vine copula mixture models and clustering for non-Gaussian data Statistical Methods in Machine Learning Prof. Claudia Czado ¨ Ozge Sahin <ozge.sahin@tum.de> Bernoulli-IMS One World Symposium August 2020
Finite mixture models k components generate data The density of a finite mixture model for X = ( X 1 , . . . , X d ) ⊤ at x = ( x 1 , . . . , x d ) ⊤ can be written as: k � g ( x ; η ) = π j · g j ( x ; ψ j ) . (1) j =1 How to select densities of each component g j ( x ; ψ j )? Symmetric distributions, skewed distributions, and others... ¨ Ozge Sahin Vine copula mixture models and clustering for non-Gaussian data August 2020 1 / 13
Vine copula mixture models, vcmm Representation of diverse dependence structures in the data The density of a finite mixture model for X = ( X 1 , . . . , X d ) ⊤ at x = ( x 1 , . . . , x d ) ⊤ can be written as: k � g ( x ; η ) = π j · g j ( x ; ψ j ) . (2) j =1 How to select flexible densities of each component g j ( x ; ψ j ) so the model can represent different asymmetric or/and tail dependencies for different pairs of variables? Vine copulas ¨ Ozge Sahin Vine copula mixture models and clustering for non-Gaussian data August 2020 2 / 13
Vine copulas Efficient tools for high-dimensional dependence modeling A bivariate copula C: Distribution on [0 , 1] 2 with univariate uniform margins. Vine copulas : For higher-dimensional data, Bivariate copulas are building blocks [Aas et al., 2009], Bivariate copulas and a nested set of trees determine dependence structure [Bedford and Cooke, 2002]. Sklar’s Theorem [Sklar, 1959] A d -dimensional density can be decomposed into products of marginal densities and bivariate copula densities assuming absolute continuity of random variables: � · f 1 ( x 1 ) · · · f d ( x d ) , x ∈ R d . � F 1 ( x 1 ) , . . . , F d ( x d ) g ( x ) = c (3) ¨ Ozge Sahin Vine copula mixture models and clustering for non-Gaussian data August 2020 3 / 13
Vine copula mixture models, vcmm Decompose a component’s density into marginal and 2 d -copula dens. C (1)1 , 2 C (1)2 , 3 C (2)1 , 2 C (2)1 , 3 T (1)1 T (2)1 1 2 3 2 1 3 C (1)1 , 3;2 C (2)2 , 3;1 T (1)2 1,2 2,3 T (2)2 1,2 1,3 (a) First component (b) Second component Figure 1: Vine copula model of two components. The density of the first component at x = ( x 1 , x 2 , x 3 ) ⊤ : � � g 1 ( x ; ψ 1 ) = c (1)1 , 2 F 1(1) ( x 1 ; γ 1(1) ) , F 2(1) ( x 2 ; γ 2(1) ); θ (1)1 , 2 � � · c (1)2 , 3 F 2(1) ( x 2 ; γ 2(1) ) , F 3(1) ( x 3 ; γ 3(1) ); θ (1)2 , 3 (4) � � · c (1)1 , 3;2 F (1)1 | 2 ( x 1 | x 2 ; γ 1(1) , γ 2(1) , θ (1)1 , 2 ) , F (1)3 | 2 ( x 3 | x 2 ; γ 3(1) , γ 2(1) , θ (1)2 , 3 ); θ (1)1 , 3;2 · f 1(1) ( x 1 ; γ 1(1) ) · f 2(1) ( x 2 ; γ 2(1) ) · f 3(1) ( x 3 ; γ 3(1) ) , ¨ Ozge Sahin Vine copula mixture models and clustering for non-Gaussian data August 2020 4 / 13
Vine copula mixture models, vcmm Work with an assignment of the observations to the components Input: d -dimensional n observations to cluster x i = ( x i , 1 , . . . , x i , d ) ⊤ ∈ R d for i = 1 , . . . , n , Total number of clusters k . A partition of the observations: Total number of observations assigned to the j th component is n j , The observations belonging to the j th component x ( j ) i j = ( x ( j ) i j , 1 , . . . , x ( j ) i j , d ) ⊤ for i j = 1 , . . . n j and j = 1 , . . . , k , k � n j = n and � x ( j ) i j = � x i . j =1 ∀ ( j , i j ) ∀ i ¨ Ozge Sahin Vine copula mixture models and clustering for non-Gaussian data August 2020 5 / 13
Vine copula mixture models, vcmm Parametric model selection For a variable x p ( j ) = ( x ( j )1 , p , . . . , x ( j ) n j , p ) ⊤ , p = 1 , . . . , d and j = 1 , . . . , k , 1. Marginal distribution selection F j : For each candidate for marginal distribution on the variable x p ( j ) , find the parameters that maximize the log-likelihood ℓ ( ˆ γ p ( j ) ), then select the marginal distribution ˆ F p ( j ) with the lowest AIC. 2. Vine tree structure selection V j : Obtain u-data by applying u p ( j ) = ˆ probability integral transformation: ˆ F p ( j ) ( x p ( j ) ; ˆ γ p ( j ) ). Then follow the greedy algorithm of [Dißmann et al., 2013]. 3. Pair copula family selection B j ( V j ): Given the vine tree structure, estimate the copula parameters that maximize the log-likelihood ℓ ( ˆ θ ( j ) e a , e b ; D e ). Later choose the copula family with the lowest AIC. ¨ Ozge Sahin Vine copula mixture models and clustering for non-Gaussian data August 2020 6 / 13
Vine copula mixture models Estimate parameters with the modified ECM algorithm The log-likelihood of the given data: n n k � � � ℓ ( η ) = log g ( x i ; ψ ) = log π j · g j ( x i ; ψ j ) . (5) i =1 i =1 j =1 Introduce latent variables z i = ( z i , 1 , . . . , z i , k ) ⊤ � 1 , if x i belongs to the j th component, z i , j = (6) 0 , otherwise, k and � z i , j = 1. j =1 The complete data log-likelihood ℓ c ( η ; z , x ) of the com- plete data y i = ( x i , z i ) ⊤ : n k n k n k � � � � � � [ π j · g j ( x i ; ψ j )] zi , j = ℓ c ( η ; z , x ) = log z i , j · log π j + z i , j · log g j ( x i ; ψ j ) , i =1 j =1 i =1 j =1 i =1 j =1 (7) ¨ Ozge Sahin Vine copula mixture models and clustering for non-Gaussian data August 2020 7 / 13
Vine copula mixture models, vcmm Estimate parameters with the modified ECM algorithm Our steps at the ( t + 1)th iteration: 1. E-step (Posterior probabilities) π ( t ) g j ( x i ; ψ ( t ) ) r ( t +1) j j = for i = 1 , . . . n and j = 1 , . . . k . i , j k π ( t ) g j ( x i ; ψ ( t ) � ) j j j =1 (8) 2. CM-step 1 (Mixture weights) n r ( t +1) � i , j π ( t +1) i =1 = j = 1 , . . . k . (9) for j n 3. CM-step 2 (Marginal parameters) n r ( t +1) · log g j ( x i ; γ j , θ ( t ) � max ) for j = 1 , . . . k (10) i , j j γ j i =1 4. CMR-step (Pair copula parameters updated sequentially) ¨ Ozge Sahin Vine copula mixture models and clustering for non-Gaussian data August 2020 8 / 13
Vine copula based clustering, vcmmc Consists of 7 primary building blocks 1. Initial clustering assignment, 2. Initial model selection with Markov trees and parametric marginal distributions, 3. Iterative parameter estimation with the modified ECM, 4. Temporary clustering assignment, 5. Temporary model selection with full vine specification, 6. Final model selection with different initial clustering methods, i.e. run the steps 1-5 with different initial partitions, 7. Final clustering assignment. ¨ Ozge Sahin Vine copula mixture models and clustering for non-Gaussian data August 2020 9 / 13
Vine copula based clustering, vcmmc Captures the non-Gaussian components hidden in the data Figure 2: Pairwise scatter plot of the subset of AIS data(left), red:females, green:males. Pairs plots of females(middle) and males(right). Model vcmmc GMM skew normal t skew-t k-means Misclassification rate 0.02 0.09 0.04 0.29 0.04 0.34 BIC 6942 7062 7055 7092 7048 - Number of free parameters 41 30 51 41 51 - Table 1: Comparison of clustering algorithm performances on the subset of AIS data. ¨ Ozge Sahin Vine copula mixture models and clustering for non-Gaussian data August 2020 10 / 13
Vine copula based clustering, vcmmc Nicely interprets the structure of the data Males Females N(-0.27/-0.17) C(1.84/0.48) SG(3.90/0.74) F(-0.15/-0.02) Ferr Ht LBM LBM Wt WBC SG(7.64/0.87) C(1.95/0.49) N(0.11/0.07) WBC Wt Ht Ferr F(1.62/0.18) Figure 3: The first tree level of the estimated vine copula model for females and males. A capital letter at an edge refers to its bivariate copula family, where N: Gaussian, C: Clayton, SG: Survival Gumbel, and F: Frank copula. The estimated parameter value and corresponding Kendall’s τ of the pair copula are given inside the parenthesis (estimated parameter/Kendall’s ˆ τ ). ¨ Ozge Sahin Vine copula mixture models and clustering for non-Gaussian data August 2020 11 / 13
Vine copula mixture models and clustering Appealing ad promising framework What we have done: A vine copula mixture model, called vcmm, that works with continuous data and fits all classes of vine tree structures, Use of parametric marginal distributions and pair copula families with a single parameter, Data-driven approach for model selection problems, Modified the ECM algorithm [Meng and Rubin, 1993] for parameter estimation, A new and promising model-based clustering algorithm, called vcmmc. Future research directions: Extension for discrete ordinal variables, Dimensionality reduction for vine copula based clustering, Parsimonious vine copula mixture models. ¨ Ozge Sahin Vine copula mixture models and clustering for non-Gaussian data August 2020 12 / 13
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.