
TRACER - Preprocessing Marco Bchler, Emily Franzini, Greta Franzini, - PowerPoint PPT Presentation
TRACER - Preprocessing Marco Bchler, Emily Franzini, Greta Franzini, Maria Moritz eTRAP Research Group Gttingen Centre for Digital Humanities Institute of Computer Science Georg August University Gttingen, Germany 2015 DH Estonia
TRACER - Preprocessing Marco Büchler, Emily Franzini, Greta Franzini, Maria Moritz eTRAP Research Group Göttingen Centre for Digital Humanities Institute of Computer Science Georg August University Göttingen, Germany 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Hacking – Installation & configuration guide for TRACER 1) Copy Tracer from /storage/tracer.tar.gz to your storage folder such as /storage/mbuechler 2) Change to your storage folder with cd command 3) Unzip archive: gunzip tracer.tar.gz 4) Untar archive: tar -xvf tracer.tar 5) Change to tracer folder: cd Tracer 6) Open the config file with vim conf/tracer_config.xml 7) Configure your input file: 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Hacking - Starting TRACER 1) Start the tool with the command: java -Xmx600m -Dde.gcdh.medusa.config.ClassConfig=conf/tracer_config.xml -jar tracer.jar Explanation: -Xmx600m (up to 600 MB memory), -Dfile.encoding sets the encoding of your input file (optionally), -Dde.gcdh.medusa.config.ClassConfig (configuration file) 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Overview • What is preprocessing? • Overview of preprocessing techniques • Hacking • Conclusion with some test questions 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
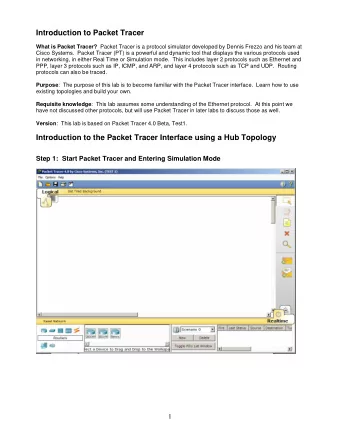
Reminder: Current approach 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Pre-step: Segmentation - an example 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Pre-step: Segmentation 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Question What do you associated with preprocessing? 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Foundations for preprocessing – Zipfian Law 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Implications of the Zipfian Law • Approx. 50% of all words occur only once • Approx. 16% of all words occur only twice • Approx. 8% of all words occur three times • ... • Approx. 90% of all words in a corpus occur 10 times or less • The top 300 – 700 most frequent words cover already about 50% of all tokens (depending language) 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Question • What does lemmatisation mean for this plot? 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Preprocessing 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Preprocessing: Directed Graph Normalisation • e.g. lemmatisation 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Preprocessing: Indirected Graph Normalisation • e.g. synonyms, string similarity 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Hacking • Tasks: – Run on your texts ... 1) ... without preprocessing 2) ... 1) + lemmatisation 3) ... 2) + synonym replacement 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Hacking • Questions: – Compare the input file with the *.prep file for all preprocessing techniques. Which methods seems to work best for you? Which does make no sense for the dataset? – Compare all *.meta files containing some numbers! How many words have changed and by which method? – (optional and advanced) what is the number of word types for each preprocessing (can be derived from *.prep.inv first column) 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Preprocessing – 1) without preprocessing • Hint: – Configuration file can be found in ${TRACER_HOME}/conf/tracer_conf.xml – All values show „false“ 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Preprocessing – 2) Removing diachritics • Hint: – BoolRemoveDiachritics is switched on by value true 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Preprocessing – 3) Lower case • Hint: – boolMakeAllLowerCase is switched on by value true 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Preprocessing – 4) Lemmatising text • Hint: – boolLemmatisation is switched on by value true – Lemmatisation can be configured by <property name="BASEFORM_FILE_NAME" value="data/corpora/Bible/Bible.lemma" /> 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Preprocessing – 5) Synonym handling • Hint: – boolReplaceSynonyms is switched on by value true – Synonyms can be configured by <property name="SYNONYMS_FILE_NAME" value="data/corpora/Bible/Bible.syns" /> 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Preprocessing – 6) String similarity for normalising variants • Hint: – boolReplaceStringSimilarWords is switched on by value true – Thresholds: 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Open issue: Fragmentary words 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Open issue: Fragmentary words – dealing with gaps and Leiden Convention Οὐιβίῳ Ἀλεξά̤[ν]δρῳ τῷ κρατίστῳ ἐπιστρατήγῳ παρὰ Ἀντ[ωνίου Δ]όμνά̤ου τοῦ καὶ Φιλαντι[νό]οά̤υά̤ Ἀντωνίοά̤[υ Ῥωμανο]ῦά̤ Τραιανείου τοῦ καά̤[ὶ Στρα]τά̤είου Ἀντινοέως. [οὐκ ἂν] εἰς τοῦτο προήχθά̤[η]νά̤, ἐά̤πι- τρόπων [μέγιστ]εά̤, μέ[τριος] καὶ ἀπρά̤γά̤μων ὢνά̤ ἄνθρά̤[ωπος,] εά̤ἰ μὴ [ὓβρι]ν τὴν μά̤[εγ]ίστηνά̤ ἐπά̤επόνθ[ειν ὑπὸ] Ὡρίωνο[ς κ]ωά̤μογρα[μ]μά̤ατέως Φ[ι]λαδελφείά̤[ας τῆ]ς Ἡρακλεά̤ίά̤δου μερίδοά̤[ς] τά̤οῦ Ἀρά̤σινοίτου. [οὗ χά]ριν μην[ύ]ω παρὰ τ[ὰ ἀ]πει- ρημένα ἑαά̤[υτὸ]νά̤ ἐνσείσανά̤τα εἰς τὴν κωμο- γραμματείανά̤ [μ]ήτε σιτολογήσαντα μήτε πρά̤[α]κτορεύσαντά̤α παντελῶς ἄπορον ὄν[τ]αά̤. δι᾽ ἣά̤ν αἰτίαν κά̤αὶ πρότερον οὐ διέλιπον ἐντυγ- χά̤νων καὶ νῦά̤ν ἀξιῶ, ἐάν σου τῇ τύχῃ δόξ[ῃ], ἀκοῦσά̤αί μου π[ρ]ὸς αὐτὸν πρὸς τὸ τυχεῖν με τά̤ῆά̤ςά̤ ἀπὸ σοῦ [μι]σοπονήρου ἐγδ[ι]κίας, ἵν᾽ ὦ ὑπὸά̤ [σ]οά̤ῦά̤ κατὰά̤ πά̤άντα βά̤εά̤βοηθ(ημένος). διευτύχει Ἀντώνιος Δόμνά̤οά̤ς ἐπιδέδωκα. 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Gap between knowledge and experience 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Test questions • Statement: – „My lemmatisation tool <XYZ> is able to compute the baseforms of 80% of all tokens in a corpus.“ Good or bad??? 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Test questions • Fact file: – Language variants – Different writing styles – (some) Dialects – Diachritics – OCR errors • Question: What is the difference for you? 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Test questions • Fact file: – Language variants – Different writing styles – (some) Dialects – Diachritics – OCR errors • Question: What do you think is the difference for the computer? 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Importance of preprocessing • Cleaning and harmonising the data • When working with a new corpus (not only language but also same language in a different epoch or geographical region can take up to 70% of the overall time. • Preprocessing mantra: Garbage in, garbage out. 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Thank you! " Stealing from one is plagiarism, stealing from many is research " (Wilson Mitzner, 1876-1933) Visit us at http://etrap.gcdh.de 2015 DH Estonia – Text Reuse Hackathon 20. Oktober 2015
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.