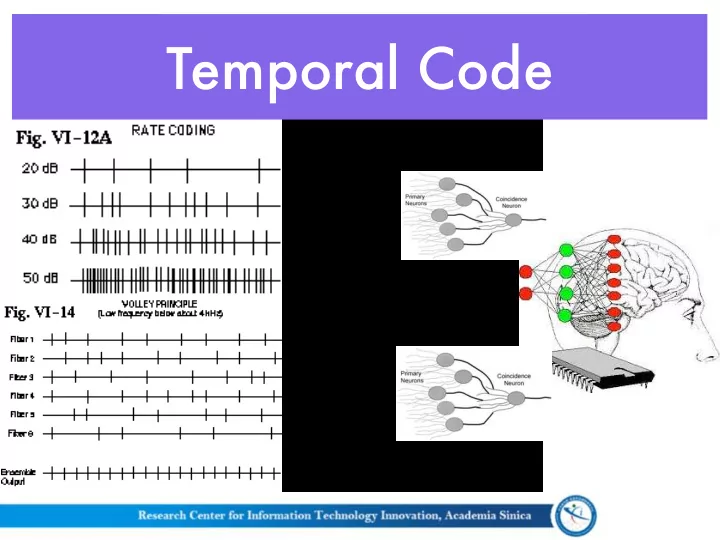
Temporal Code
Temporal Code
Temporal Code (Acoustic Front-end)
Human Recognition
Machine Recognition RECOGNIZED UTTERANCE LANGUAGE MODELING (Back-end) � HYPOTHESIZED UTTERANCES STATISTICAL SEQUENCE RECOGNITION ACOUSTIC REPRESENTATION ACOUSTIC FRONT END SPEECH WAVEFORM
Human vs. Machine
“Top-down” Processing
Machine Training • Aurora-4 Speech Database � • Wall Street Journal (WSJO) Corpus � • Large Vocabulary Continuous Speech Recognition � • 7,138 clean speech utterances, 16kHz
Human Training • Wernicke’s Area: Speech Understanding � • Broca’s Area: Speech Production
Acoustic Model Hidden Markov Model (HMM) • Each triphone characterized by HMM consisting of 3 states, 8 Gaussian mixtures per state Transition Probability Emission Probability Density
Acoustic Model • Maximum likelihood (ML) training applied to estimate a set of context-dependent triphone acoustic models
Language Model • Standard 5k lexicon (CMU pronouncing Dictionary) • Tri-gram language model
Decoder • Single-pass Viterbi beam search-based decoder
Human Recognition � Noise-Vocoder � Tone-Vocoder
CI Recognition
Normal Hearing vs. CI • Cochlear Implant range (hatched area) compared with average normal hearing scores (filled squares)
CI vs. Machine Recognition • ASR provided most accurate simulation ever!
Machine Recognition • ASR derived by world’s best auditory scientists
Effects of Training
Effects of Training
Effects of Training
Clinical Implications • Alter Frequency Allocation � • Deactivate Interfering Electrodes � • Alter Compression Curve � • Modify Electric Pulse Width
Summary
Information Technology • 2014, HMM can now improve Hearing Science
Future Work • Design improved signal processing to mimic: � • 1) Place code of neurons � • 2) Neural Firing Rates
FAME Strategy • Frequency Amplitude Modulation Encoder
SOUND S pectral Or � U ndertone N ormalization D ecomposition
Recommend
More recommend
Unleash a World of Digital Possibilities—Browse, Share, and Explore Content Without Boundaries