
RNA Search and Motif Discovery CSEP 527 Computational Biology - PowerPoint PPT Presentation
RNA Search and Motif Discovery CSEP 527 Computational Biology Previous Lecture Many biologically interesting roles for RNA RNA secondary structure prediction 1 2 Approaches to Structure Prediction Maximum Pairing + works on
RNA Search and � Motif Discovery CSEP 527 � Computational Biology
Previous Lecture � Many biologically interesting roles for RNA RNA secondary structure prediction 1
2
Approaches to Structure Prediction Maximum Pairing � + works on single sequences � + simple � - too inaccurate Minimum Energy � + works on single sequences � - ignores pseudoknots � - only finds “optimal” fold Partition Function � + finds all folds � - ignores pseudoknots 3
“Optimal pairing of r i ... r j ” � Two possibilities i j Unpaired: � Find best pairing of r i ... r j-1 j j-1 j Paired (with some k): � i Find best r i ... r k-1 + � k-1 best r k+1 ... r j-1 plus 1 k j Why is it slow? � k+1 j-1 Why do pseudoknots matter? 4
Nussinov: � A Computation Order Or energy B(i,j) = # pairs in optimal pairing of r i ... r j B(i,j) = 0 for all i, j with i ≥ j-4; otherwise B(i,j) = max of: K=2 B(i,j-1) 3 4 5 max { B(i,k-1)+1+B(k+1,j-1) | � i ≤ k < j-4 and r k -r j may pair} Time: O(n 3 ) Loop-based energy version is better; recurrences similar, slightly messier 5
Loop -based Energy Minimization 1 Detailed experiments show it’s � more accurate to model based � 2 on loops , rather than just pairs 3 Loop types 1. Hairpin loop 2. Stack 4 3. Bulge 4. Interior loop 5. Multiloop 5 6
Zuker: Loop-based Energy, I W(i,j) = energy of optimal pairing of r i ... r j V(i,j) = as above, but forcing (i.e., subset with) pair i•j W(i,j) = V(i,j) = ∞ for all i, j with i ≥ j-4 W(i,j) = min( W(i,j-1), � min { W(i,k-1)+V(k,j) | i ≤ k < j-4 } ) 7
Zuker: Loop-based Energy, II bulge/ multi- hairpin stack interior loop V(i,j) = min(eh(i,j), es(i,j)+V(i+1,j-1), VBI(i,j), VM(i,j)) VM(i,j) = min { W(i,k)+W(k+1,j) | i < k < j } VBI(i,j) = min { ebi(i,j,i’,j’) + V(i’, j’) | � i < i’ < j’ < j & i’-i+j-j’ > 2 } Time: O(n 4 ) bulge/ interior O(n 3 ) possible if ebi(.) is “nice” 8
Single Seq Prediction Accuracy Mfold, Vienna,... [Nussinov, Zuker, Hofacker, McCaskill] Estimates suggest ~50-75% of base pairs predicted correctly in sequences of up to ~300nt Definitely useful, but obviously imperfect 9
Approaches, II Comparative sequence analysis � + handles all pairings (potentially incl. pseudoknots) � - requires several (many?) aligned, � Today appropriately diverged sequences Stochastic Context-free Grammars � Roughly combines min energy & comparative, but no pseudoknots Physical experiments (x-ray crystalography, NMR) 10
Covariation is strong evidence for base pairing 11
A L19 ( rplS ) mRNA leader P1 TSS Excess L19 represses L19 (RF00556; 555-559 similar) P2 -35 -10 RBS Start Example: Ribosomal Autoregulation: C B B. subtilis L19 mRNA leader nucleotide nucleotide UU U C identity present UU U A G U U A U U A G G N 97% 97% G G A U G U N 90% 90% G U G A C G ? C G N 75% 75% G C G L19 P2 C G G C U 50% 3' U G C U U G C G Y C A A G A G stem loop U G C G U A A C C always present U A A C G U U G U C G U C G G A G C C G C C G C G compensatory mutations G U A U A U A 3' A compatible mutations R U A U G G A R Y G P1 G C G U R G A U A G C Watson-Crick base pair U G G R U G A U A U U 5' 3' G Y U U G A other base interaction 5' C G C U G 12 G U A G 5' C G AAAA C
Mutual Information f xi , xj ∑ M ij = f xi , xj log 2 ; 0 ≤ M ij ≤ 2 f xi f xj xi , xj Max when no seq conservation but perfect pairing MI = expected score gain from using a pair state (below) Finding optimal MI, (i.e. opt pairing of cols) is hard(?) Finding optimal MI without pseudoknots can be done by dynamic programming 13
M.I. Example (Artificial) * 1 2 3 4 5 6 7 8 9 * MI: 1 2 3 4 5 6 7 8 9 A G A U A A U C U 9 0 0 0 0 0 0 0 0 A G A U C A U C U 8 0 0 0 0 0 0 0 A G A C G U U C U 7 0 0 2 0.30 0 1 A G A U U U U C U 6 0 0 1 0.55 1 A G C C A G G C U 5 0 0 0 0.42 A G C G C G G C U 4 0 0 0.30 A G C U G C G C U 3 0 0 A G C A U C G C U 2 0 A G G U A G C C U 1 A G G G C G C C U A G G U G U C C U Cols 1 & 9, 2 & 8: perfect conservation & might be A G G C U U C C U A G U A A A A C U base-paired, but unclear whether they are. M.I. = 0 A G U C C A A C U A G U U G C A C U Cols 3 & 7: No conservation, but always W-C pairs, A G U U U C A C U so seems likely they do base-pair. M.I. = 2 bits. Cols 7->6: unconserved, but each letter in 7 has A 16 0 4 2 4 4 4 0 0 C 0 0 4 4 4 4 4 16 0 only 2 possible mates in 6. M.I. = 1 bit. G 0 16 4 2 4 4 4 0 0 U 0 0 4 8 4 4 4 0 16 14
15
MI-Based Structure-Learning � Problem: Find best (max total MI) pseudo-knot-free subset of column pairs among i…j. Solution: “Just like Nussinov/Zucker folding” $ S i , j = max S i , j − 1 j unpaired % max i ≤ k < j − 4 S i , k − 1 + M k , j + S k + 1, j − 1 j paired & BUT, need the right data—enough sequences at the right phylogenetic distance 16
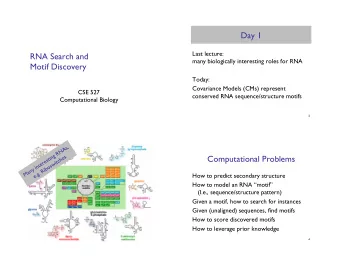
Computational Problems How to predict secondary structure How to model an RNA “motif” � (I.e., sequence/structure pattern) Given a motif, how to search for instances Given (unaligned) sequences, find motifs How to score discovered motifs How to leverage prior knowledge 17
Motif Description 18
RNA Motif Models “Covariance Models” (Eddy & Durbin 1994) aka profile stochastic context-free grammars aka hidden Markov models on steroids Model position-specific nucleotide preferences and base-pair preferences Pro: accurate Con: model building hard, search slow 19
Eddy & Durbin 1994: What A probabilistic model for RNA families The “Covariance Model” ≈ A Stochastic Context-Free Grammar A generalization of a profile HMM Algorithms for Training From aligned or unaligned sequences Automates “comparative analysis” Complements Nusinov/Zucker RNA folding Algorithms for searching 20
Main Results Very accurate search for tRNA (Precursor to tRNAscanSE – a very good tRNA-finder) Given sufficient data, model construction comparable to, but not quite as good as, � human experts Some quantitative info on importance of pseudoknots and other tertiary features 21
Probabilistic Model Search As with HMMs, given a sequence: You calculate likelihood ratio that the model could generate the sequence, vs a background model You set a score threshold Anything above threshold → a “hit” Scoring: “Forward” / “Inside” algorithm - sum over all paths Viterbi approximation - find single best path � (Bonus: alignment & structure prediction) 22
Example: searching for tRNAs � 23
Profile Hmm Structure M j : Match states (20 emission probabilities) I j : Insert states (Background emission probabilities) D j : Delete states (silent - no emission) 24
How to model an RNA “Motif”? Conceptually, start with a profile HMM: from a multiple alignment, estimate nucleotide/ insert/delete preferences for each position given a new seq, estimate likelihood that it could be generated by the model, & align it to the model ins mostly G del all G 25
How to model an RNA “Motif”? Add “column pairs” and pair emission probabilities for base-paired regions <<<<<<< >>>>>>> paired columns … … 26
Profile Hmm Structure M j : Match states (20 emission probabilities) I j : Insert states (Background emission probabilities) D j : Delete states (silent - no emission) 27
CM Structure A: Sequence + structure B: the CM “guide tree” C: probabilities of letters/ pairs & of indels Think of each branch being an HMM emitting both sides of a helix (but 3’ side emitted in reverse order) 28
CM Viterbi Alignment � (the “inside” algorithm) = i th letter of input x i x ij = substring i ,..., j of input T yz = P (transition y → z ) y E x i , x j = P (emission of x i , x j from state y ) y S ij = max π log P ( x ij gen'd starting in state y via path π ) 29
CM Viterbi Alignment � (the “inside” algorithm) y = max π log P ( x ij generated starting in state y via path π ) S ij % z y max z [ S i + 1, j − 1 + log T yz + log E x i , x j ] match pair ' y ] z max z [ S i + 1, j + log T yz + log E x i match/insert left ' ' y = y ] z S ij & max z [ S i , j − 1 + log T yz + log E x j match/insert right ' z max z [ S i , j + log T yz ] delete ' y right ] y left + S k + 1, j ' max i < k ≤ j [ S i , k bifurcation ( Time O(qn 3 ), q states, seq len n compare: O(qn) for profile HMM 30
Primary vs Secondary Info disallowing / allowing pseudoknots ( ) / 2 n ∑ max j M i,j i = 1 31
An Important Application: � Rfam A Database of RNA Families 32
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.