
PRLab TUDelft NL PATTERN RECOGNITION & MACHINE LEARNING An - PowerPoint PPT Presentation
PRLab TUDelft NL PATTERN RECOGNITION & MACHINE LEARNING An Introduction Marco Loog Pattern Recognition Laboratory Delft University of Technology PRLab TUDelft NL What These Lectures Will Cover Intro to supervised learning and
PRLab TUDelft NL
PATTERN RECOGNITION & MACHINE LEARNING An Introduction Marco Loog Pattern Recognition Laboratory Delft University of Technology PRLab TUDelft NL
What These Lectures Will Cover � Intro to supervised learning and classification � Semi-supervised learning � Multiple instance learning � Active learning � Transfer learning, domain adaptation, etc., etc. � General theme is partially supervised learning � General focus is on methods and concepts PRLab TUDelft NL
Lab & Final Assignment � Last day : computer lab � You can work on your “final assignment” � Like rest of this course, attending is not mandatory � It is eight [8!] hours… which I find somewhat long � Most of the work you can also do, say, at home � I guess we still have to find the right way to go about this… � More about the actual assignment on a later slide… PRLab TUDelft NL
Supervised Learning � Aims to find solutions to difficult decision, assignment, classification, and prediction problems � Automation often, possibly implicit, an issue � Have computers and robots do task that are dangerous, tedious, boring, etc. � Part of the point : humans often severely biased in judgment, very inaccurate � You cannot even trust your own eyes! PRLab TUDelft NL
PRLab TUDelft NL
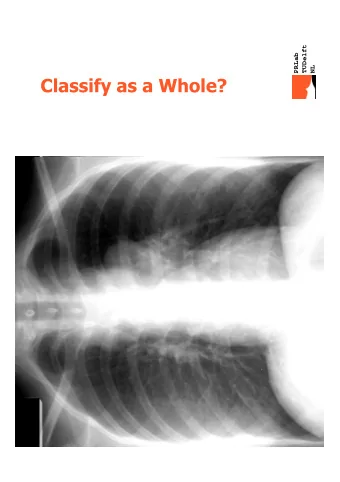
Comparing and … PRLab TUDelft NL
Supervised Learning = Not Modeling Fruits orange, reddish-green � to yellowish-green, round, 4- 12 cm, consist of a leathery peel, 6 mm thick, tightly adherent, protecting the juicy inner pulp, which is divided into segments that may not contain seeds, depending on the cultivar… PRLab TUDelft NL
Orange Modeling � Difficult, hassle, overly ambitious, inaccurate,… � Captures typicalities PRLab TUDelft NL
Supervised Learning � …is learning by example � Given input and associated output, determine input- output mapping � Mapping should be able to generalize to new and previously unseen examples PRLab TUDelft NL
Remark � In the end, one never relies solely on extremes of pure modeling or pure model-free learning � Learning does use models, though they are weak and nonspecific PRLab TUDelft NL
Restricted Setting : Classification � Sought-after mapping puts out discrete label, category, or class membership � A, B, C,… � Orange, apple, banana… � Benign, malignant,… � Present, absent,… � Many relevant decision problems can be formulated as such PRLab TUDelft NL
Standard Approach � Training phase � Collect example objects � Measure � features of choice and represent in vector space � Chop up � -dimensional feature space and assign every part a class label � Test phase � Extract same features from new object � Look in what part it ends up in feature space � Assign label of corresponding part to object PRLab TUDelft NL
weight redness PRLab TUDelft NL
weight redness PRLab TUDelft NL
weight redness PRLab TUDelft NL
weight label? redness PRLab TUDelft NL
More Realistic Problems… � Manual construction becomes difficult when � > 3 � Formulate classifier building as “fitting” problem that can be automated � Learning algorithm � Ingredients : � What functions / mappings to fit : hypothesis class? � What defines a good fit : loss / risk function? � How do find the optimal fit? PRLab TUDelft NL
PRLab Also : Learning is Ill-Posed TUDelft NL
A General Challenge � One of the challenges [in research and applications] is how to pick out classifier that generalizes best to unseen data � How to do accurate induction � Important tradeoff : complexity decision boundary versus accuracy on training examples � Key issue : how to tell how good a classifier works on infinite amounts of unseen data based on a finite sample? PRLab TUDelft NL
A Note on Research � The purpose of PR [and ML] research is not only to construct classification routines but, in addition, to understand these routines and to obtain insight in their behavior, pros and cons, etc. � Ultimately, it should lead to understanding the learning problem as such � And no , it is not about getting the best classification performance or achieving “state of the art”! PRLab TUDelft NL
Mathematics versus Empiricism � Can’t we just all solve it mathematically? � After all, we can write down our objective function : argmin � � � � ≠ � �; � � �, � �� � � � Some major problems � Finite sample : we do not know �(�, �) � Ones math skills might be limited PRLab TUDelft NL
Mathematics versus Empiricism � Luckily [applied?] computer science is an empirical discipline with programs as its experiments � We can just build classifiers and see what happens � Use of artificial and real-world data � So we can ditch the math? PRLab TUDelft NL
Still : Insight Please? � Yes, this remains, all in all, difficult… � Firstly : hold on to current knowledge � Generally, there is no such thing as the overall best classifier � Classifiers should be studied relative to one or more [families of] data sets / examples � Parameters of major influence : sample size and dimensionality PRLab TUDelft NL
Still : Insight Please? � Secondly : ask yourself “obvious” questions [and try to answer them] � Why does my approach work better / worse? � Can I come up with examples in which case the one approach is always better than the other? � Do I understand why that happens in this case? � Can I say more than “experiment X gives outcome Y”? � Trivial? Sure… PRLab TUDelft NL
Lab & Final Assignment � The idea : implement [or take] two or three methods and do a basic comparison � To each other � To the standard benchmark [e.g. supervised classifier or random sampling] � In particular � Find data sets [artificial or real world] in which the methods outperform the standard benchmark � Find a data set for which Method � outperforms Method Ω and vice versa � Explain your reasoning, constructions, and findings! PRLab TUDelft NL
How To? argmin � � � � ≠ � �; � � �, � �� � � � � Empirical risk ⇒ smooth ⇒ make convex PRLab TUDelft NL
Surrogate Losses… PRLab TUDelft NL
Regularization � Regularized empirical risk : argmin � ! � " , � � " ; � + �(�) � " � � typically controls complexity / smoothness of the solution � ∙ ; � � Ubiquitous example � Take � �; � = �, � , the class of linear classifiers � � Take � � = PRLab TUDelft NL
Loss, Hypothesis Class, Regularizer? � Yes � LDA, QDA, NMC, SVM, least squares classifier [a.k.a. least squares SVM, Fisher classifier], logistic regression, neural nets, lasso � No? � $ NN, random forest, AdaBoost, Parzen classifier � Some parameters are tuned different then others � N.B. no classifier really minimizes the empirical 0-1 loss directly… PRLab TUDelft NL
The Dipping Phenomenon � A consequence of the use of surrogate losses � Meant as a warning : be award of what you optimize! � Meant as an example of PR research � But first we need learning curves … PRLab TUDelft NL
Learning Curves � Tool to study behavior of classifiers over varying number of examples and to compare two or more classifiers error rate # training examples PRLab TUDelft NL
Expected Behavior � Monotonic decrease of learning curve [at least in the average] error rate # training examples PRLab TUDelft NL
Well… There is Peaking � Independently described in 1995 by both Opper and Duin error rate # training examples PRLab TUDelft NL
New Hypothesis? � Can we guarantee that, in expectation , best performance, for particular classifier on particular problem, is achieved when sample size is infinite ? PRLab TUDelft NL
The Dipping Phenomenon � Can we guarantee that, in expectation , best performance, for particular classifier on particular problem, is achieved when sample size is infinite ? � No, we cannot… PRLab TUDelft NL
Basic Dipping : Linear Classifiers PRLab TUDelft NL
Basic Dipping : Linear Classifiers PRLab TUDelft NL
Basic Dipping : Linear Classifiers PRLab TUDelft NL
Basic Dipping : Linear Classifiers PRLab TUDelft NL
PRLab TUDelft NL
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.