Patterns of hemagglutinin evolution and the epidemiology of - PowerPoint PPT Presentation
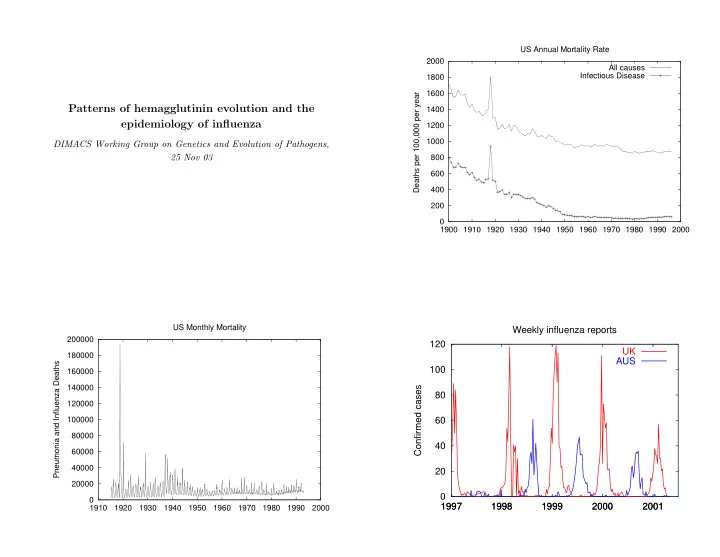
US Annual Mortality Rate 2000 All causes Infectious Disease 1800 1600 Deaths per 100,000 per year 1400 Patterns of hemagglutinin evolution and the epidemiology of influenza 1200 1000 DIMACS Working Group on Genetics and Evolution of
US Annual Mortality Rate 2000 All causes Infectious Disease 1800 1600 Deaths per 100,000 per year 1400 Patterns of hemagglutinin evolution and the epidemiology of influenza 1200 1000 DIMACS Working Group on Genetics and Evolution of Pathogens, 800 25 Nov 03 600 400 200 0 1900 1910 1920 1930 1940 1950 1960 1970 1980 1990 2000 US Monthly Mortality Weekly influenza reports 200000 120 UK 180000 AUS Pneumonia and Influenza Deaths 100 160000 140000 Confirmed cases 80 120000 60 100000 80000 40 60000 40000 20 20000 0 0 1997 1997 1998 1998 1999 1999 2000 2000 2001 2001 1910 1920 1930 1940 1950 1960 1970 1980 1990 2000
UK influenza by subtype 120 Influenza viruses H1 H3 Three types, A, B and C, in decreasing order of importance. 100 B Flu A has fifteen identified hemagglutinin subtypes , all of which are Confirmed cases 80 always present in waterfowl. Evolutionary shifts occur when core proteins from human-adapted 60 strains recombine with surface proteins from avian strains, probably in people, domestic fowl or pigs. 40 Evolutionary drift in the surface proteins means that most people are 20 susceptible to a related, circulating strain of the flu around five years after recovery. 0 1997 1997 1998 1998 1999 1999 2000 2000 2001 2001 2002 An influenza virion Shift evolution Major antigenic change caused be reassortment between human and avian virus segments. 1918 Spanish flu (H1N1) replaces earlier strain. 1957 H2N2 replaces H1N1. 1968 H3N2 replaces H2N2. 1977 H1N1 mysteriously reappears. It is estimated that there have been roughly 10 influenza pandemics (presumably caused by shifts) in the last 250 years.
✌ ✁ ☞ ✝☛ ✠✡ ✝✞✟ �✁ ✆ ✂☎✄ Drift evolution The gradual accumulation of point mutations antibody-combining regions (epitopes), leading to immunological escape. Makes vaccine-strain selection very difficult. Annual epidemics due to drift cause more total mortality and morbidity than pandemics. Rambaut, et al., 2001 Fitch, et al., 1997 Questions to be addressed by influenza modelling How do different subtypes interact at the population level, and what can this tell us about pandemics? Why model infectious diseases? What factors determine influenza’s unique phylogenetic patterns? How do local interactions explain population-level patterns? Can predictions about drift evolution improve annual vaccine choices? What can population-level patterns tell us about local interactions? Why does influenza incidence show such marked seasonal oscillations? What are the implications of influenza’s antigenic evolution for drug resistance?
Confronting models with data Outline Clustering More clustering Volatility More volatility Quasispecies structure and the antigenic evolution How to compare hemagglutinin molecules of Influenza A Antigenic assays Joshua Plotkin, Jonathan Dushoff, Simon Levin; PNAS 99:6263 Three-dimensional structure Amino-acid sequence Questions • Simple • What do modelers mean by a ‘strain’? • Precise • What does strain space look like? • Available • Do influenza viruses cluster into ‘quasispecies’?
Codon clustering 1 0.9 0.8 Mean cluster size 0.7 Random clustering technique 0.6 Examine random clusters at different length scales 0.5 Look for scales at which clusterings are stable; these are natural 0.4 clusterings 0.3 0.2 0.1 0 0 5 10 15 20 25 30 Threshold distance Amino acid clustering 1 0.9 0.8 Mean cluster size 0.7 40 0.6 Cluster size 0.5 30 0.4 0.3 20 0.2 10 0.1 0 0 2 4 6 8 10 12 14 1985 1990 1995 2000 Threshold distance Calendar year
Geographic location by cluster 40 China Other 35 Clusters through time Number of sequences 30 • Quasispecies have limited temporal range 25 • Dominant quasispecies replace each other on a time scale of 2–5 20 years 15 • Evolution is linear over this time span in amino-acid space 10 5 0 1986 1988 1990 1992 1994 1996 1998 3 Epitope A (19 sites) B (22) C (27) D (41) Mean dist. betw. seqs. E (22) Other sites (198) 2 40 35 1 30 Cluster size 25 0 5 A B 20 C Dist. betw. cluster centroids 4 D E 15 Other 3 10 2 5 1 84/85 89/90 94/95 99/00 WHO vaccine: � 0 1984 1986 1988 1990 1992 1994 1996 1998 2000
Conclusions Clustering methods for HA structures • Sequences are clustered in amino-acid space, forming natural with Ben McMahon and Joshua Plotkin ‘quasispecies’. If formal clustering methods assist in analysis of genomic patterns, • Clusters replace each other on a time scale of 2–5 years. can they also assist in analysis of structural patterns? • Clusters display interesting interactions with antibody-combining Computational and algorithmic advances make it possible to make regions (epitopes). homology models for hundreds of sequences (based on known • Formal clustering methods have potential for predicting the structures). direction of influenza evolution. Human H3 structures Homology modeling Start with backbone in the same place as known structure. Adjust for stereochemical constraints and known motifs. Local energy minimization. Works surprisingly well over a broad range of proteins.
Clustering methods for HA structures The cartoon shape is the backbone (with a color gradient). Spheres are the side chains: Relative methods White Non-polar Calculate profiles based on the protein backbone (e.g. the electric Blue Positive field at each of the 329 alpha carbons). Red Negative • Hydrophobicity Green Other polar • Electric field and potential measures The yellow is a sialic acid analog bound to the protein. • Distance profiles Hamming Quasi-potential 0.8 1 0.9 0.7 0.8 0.6 0.7 0.5 0.6 Cluster size Cluster size 0.4 0.5 0.4 0.3 0.3 0.2 0.2 0.1 0.1 0 0 0 0.5 1 1.5 2 2.5 3 3.5 4 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 0.1 Threshold distance Threshold distance
Hamming 60 50 40 No natural scale for structural clusters Need more sophisticated clustering methods 30 Evidence for compensatory mutations 20 10 0 1970 1975 1980 1985 1990 1995 2000 Year Quasi-potential Backbone 0.5 300 0.45 250 0.4 0.35 200 0.3 0.25 150 0.2 100 0.15 0.1 50 0.05 0 0 1970 1975 1980 1985 1990 1995 2000 1970 1975 1980 1985 1990 1995 2000 Year Year
Codon bias and frequency-dependent selection on the hemagglutinin epitopes of influenza A virus Provisional conclusions Joshua Plotkin and Jonathan Dushoff; PNAS 100:7152 Evidence for existence of compensatory mutations. Questions Simple, relative measures, combined with homology models, may be able to detect and explain these compensatory mutations. • Can codon usage help to explain how hemagglutinin evolves so quickly? More refined metrics needed to cluster in ways that will shed light on antigenicity. • Does hemagglutinin’s fast evolution leave a ‘footprint’ on codon usage? More refined clustering techniques may also be needed. • Can we correlate genomic information about evolution with structural information about hemagglutinin? Codon bias Natural selection in pathogens Genomes use certain codons in high proportions, in preference to other, synonymous codons. This is surprising because there is no Stabilizing selection (selection not to change) implies inflexibility, obvious reason why the organism should distinguish between importance. synonymous codons. Positive selection (selection to change) implies pressure from host Some reasons for codon bias include: immune system, or directional change (change of disease mechanism, • Nucleotide biases or change of host) Useful for investigating biology and evolution of pathogens • Mutational biases Potential applications for vaccine and drug development • The mechanics of translation • Evolutionary history
Volatility Bias towards volatility CCA (P) CTA (L) Some codons have more synonymous neighbors than others. Under CAA (Q) neutral selection, all of the non-stop neighbors of a codon are equally GGA (G) likely as predecessors. If a gene is under positive selection, the predecessor codon is more CGA (R) CGG (R) likely to have been non-synonymous. If a gene is under negative selection, the predecessor codon is more TGA (Z) likely to have been non-synonymous. CGT (R) Thus, an overabundance of codons with more non-synonymous AGA (R) neighbors (high volatility ) is a marker of positive selection. And CGC (R) conversely. 8 non-stop neighbors. 4 encode other amino acids (non-synonymous changes). Volatility = 4/8. Volatility AGG (R) AGT (S) TGA (Z) ACC (T) Detecting bias towards volatility Problem: Other sources of codon bias. Amino-acid composition of CGA (R) AGA (R) genes will bias measures of volatility. Solution: Control for amino-acid composition by making bootstrap AAA (K) copies of the gene, with the same amino-acid composition. GGA (G) ACA (T) ATA (I) 8 non-stop neighbors. 6 encode other amino acids (non-synonymous changes). Volatility = 6/8.
Recommend









![Design Patterns in Eiffel Dr. Till Bay design patterns? [Design Patterns] are](https://c.sambuz.com/1019917/design-patterns-in-eiffel-s.webp)













More recommend
Explore More Topics
Stay informed with curated content and fresh updates.