Multivariate Statistics Fundamentals Part 2: Distance-based - PowerPoint PPT Presentation
Objective Reduce Complexity Classification Test for Differences Approach PCA explain greatest DISCRIM explain what MANOVA amount of variation in distinguishes pre-determined dataset groups Rotation Exp. Factor explain scales
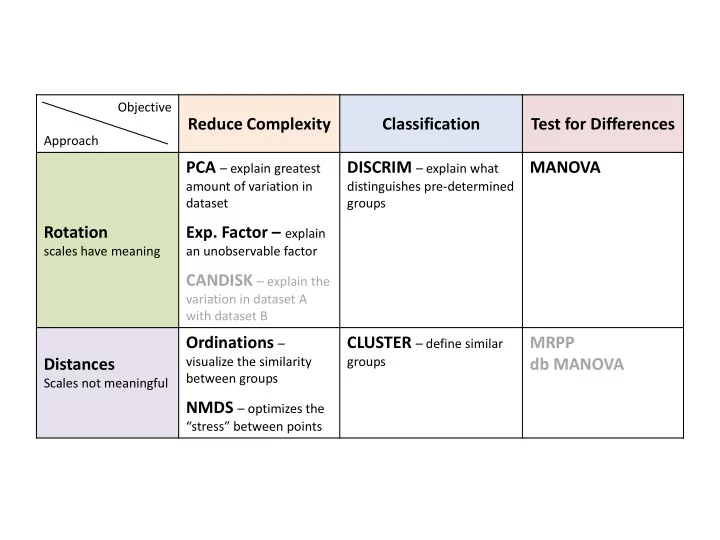
Objective Reduce Complexity Classification Test for Differences Approach PCA – explain greatest DISCRIM – explain what MANOVA amount of variation in distinguishes pre-determined dataset groups Rotation Exp. Factor – explain scales have meaning an unobservable factor CANDISK – explain the variation in dataset A with dataset B Ordinations – CLUSTER – define similar MRPP visualize the similarity groups Distances db MANOVA between groups Scales not meaningful NMDS – optimizes the “stress” between points
Objective Reduce Complexity Classification Test for Differences Approach PCA – explain greatest DISCRIM – explain what MANOVA amount of variation in distinguishes pre-determined dataset groups Rotation Exp. Factor – explain scales have meaning an unobservable factor CANDISK – explain the variation in dataset A with dataset B Ordinations – CLUSTER – define similar MRPP visualize the similarity groups Distances db MANOVA between groups Scales not meaningful NMDS – optimizes the “stress” between points Today
Multivariate Statistics Fundamentals Part 2: Distance-based Techniques
Distance-based techniques We use “Distance” to infer about similarity between data points Consider a 3D (3 variables) space: The green points are similar because they plot Variable 3 out close together The red points are also similar but this distance between them is larger than the green points We can use distances to determine if the grey Variable 1 point more similar to red or green group? Or is grey it’s own group?
Distance-based techniques In General : If two points are closer together the distance is smaller – meaning variables are similar among points If two points are further apart the distance is greater – meaning variables are different among points Unlike rotation based techniques, distance-based techniques do not keep track of original scales Data gets converted to represent similarity Data therefore becomes scale-less
The math behind distance-based techniques It’s as simple as calculating the distance between points y 2 Simplest method is to calculate the Euclidian distance: C Formula: C = 𝐵 2 + 𝐶 2 B y 1 𝑦 1 − 𝑦 2 2 + 𝑧 1 − 𝑧 2 2 2D : 𝑒 𝐹 = A 𝑦 1 − 𝑦 2 2 + 𝑧 1 − 𝑧 2 2 + ⋯ + 𝑨 1 − 𝑨 2 2 Multi : 𝑒 𝐹 = x 1 x 2 We end up changing our data table: Data.ID Varable1 Variable2 Variable3 Variable4 … A B C D … A 0 0.7 1.3 4 A B 0.7 0 2.8 1.1 B C 1.3 2.8 0 0.4 C D 4 1.1 0.4 0 D … … New matrix is symmetrical (i.e. to/from doesn’t matter) with zeros on the diagonal (indicating identical) All distance values will be positive – therefore the closer to zero the more similar
Distance method options y 2 1. Euclidian Distance – shortest path based on trigonometry y 1 𝑦 1 − 𝑦 2 2 + 𝑧 1 − 𝑧 2 2 + ⋯ + 𝑨 1 − 𝑨 2 2 𝑒 𝐹 = x 1 x 2 2. Manhattan Distance – think of going down city blocks y 2 you can’t scale a building y 1 𝑒 𝑁 = 𝑦 1 − 𝑦 2 + 𝑧 1 − 𝑧 2 + ⋯ + 𝑨 1 − 𝑨 2 x 1 x 2 3. Cheoybev’s Distance – relies on maximum values y 2 𝑒 𝐷 = 𝑝𝑔 𝑢ℎ𝑓 𝑐𝑗𝑓𝑡𝑢 𝑒𝑗𝑔𝑔𝑓𝑠𝑓𝑜𝑑𝑓𝑡 𝑝𝑜 𝑏𝑜𝑧 𝑏𝑦𝑗𝑡 y 1 x 1 x 2
Distance method options 4. Mahalanobis Distance – based on PCA followed by Euclidian distance (weights variables) Weighting Process: • If 2 variables are highly correlated then they are combined • If 2 variables are orthogonal (not correlated) then they get an equal value (varies based on correlation value) Accounts for collinearity among your variables 𝑦 1.𝑄𝐷𝐵 − 𝑦 2.𝑄𝐷𝐵 2 + 𝑧 1.𝑄𝐷𝐵 − 𝑧 2.𝑄𝐷𝐵 2 + ⋯ + 𝑨 1.𝑄𝐷𝐵 − 𝑨 2.𝑄𝐷𝐵 2 𝑒 𝑁𝑏ℎ𝑏𝑚 = X 2. PCA Y 2.PCA X 1.PCA Y 1. PCA We are rotating the data with PCA then calculating the Euclidian distance
Distance method options 5. Bray-Curtis Distance (a.k.a. Sorrenson Data) – works with binary (0,1) data Useful for Presence/Absence data Or data that is highly skewed d BC will be a value between 0 and 1 (think of it like a % of dissimilarity) Presence/Absence: #𝑝𝑔 𝑡𝑞𝑓𝑑𝑗𝑓𝑡 𝑞𝑠𝑓𝑡𝑓𝑜𝑢 𝑗𝑜 𝑐𝑝𝑢ℎ 𝑞𝑚𝑝𝑢𝑡 𝐵 &𝐶 ∗ 2 𝑒 𝐶𝐷 = # 𝑡𝑞𝑓𝑑𝑗𝑓𝑡 𝑞𝑠𝑓𝑡𝑓𝑜𝑢 𝑗𝑜 𝐵 + # 𝑡𝑞𝑓𝑑𝑗𝑓𝑡 𝑞𝑠𝑓𝑡𝑓𝑜𝑢 𝑗𝑜 𝐶 Frequency: 𝑇𝑣𝑛 𝑝𝑔 𝑚𝑓𝑡𝑡𝑓𝑠 𝑔𝑠𝑓𝑟𝑣𝑓𝑜𝑑𝑧 𝑝𝑔 𝑡𝑞𝑓𝑑𝑗𝑓𝑡 𝑗𝑜 𝑞𝑚𝑝𝑢𝑡 𝐵 &𝐶 𝑒 𝐶𝐷 = 𝑇𝑣𝑛 𝑝𝑔 𝑡𝑞𝑓𝑑𝑗𝑓𝑡 𝑔𝑠𝑓𝑟𝑣𝑓𝑜𝑑𝑧 𝑗𝑜 𝐵 + 𝑇𝑣𝑛 𝑝𝑔 𝑡𝑞𝑓𝑑𝑗𝑓𝑡 𝑔𝑠𝑓𝑟𝑓𝑜𝑑𝑧 𝑗𝑜 𝐶 Lesser : for the species that are present in both A & B include the smaller frequency Example: For Douglas-fir frequency if Plot A has 20% and Plot B has 30% - include 20% in the calculation We are determining the similarity between plots
How to choose your distance method Every field has its own method for distance measurements You need to figure out what works for your data and the question you want to answer Good starting places: Euclidian Distance – default setting for most fields, BUT explore other methods as there may be a better option for your data Mahalanobis Distance – good for ecological data, BUT it may struggle if there is a large amount of variation in one of your variables – Also good for variables that are highly correlated Bray-Curtis Distance – if you have binary data, presence absence data, or proportional data this is your best method Once distance matrices are generated (using ANY method) all fields come back to the same set of multivariate analysis techniques
Recommend
























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.