Moore s Law s Law Moore Super Scalar/Vector/Parallel 1 PFlop/s - PDF document
Self- -Adapting Adapting Self Numerical Software Numerical Software (SANS- -Effort) Effort) (SANS Jack Dongarra, Innovative Computing Laboratory University of Tennessee and Computer Science and Mathematics Division Oak Ridge National
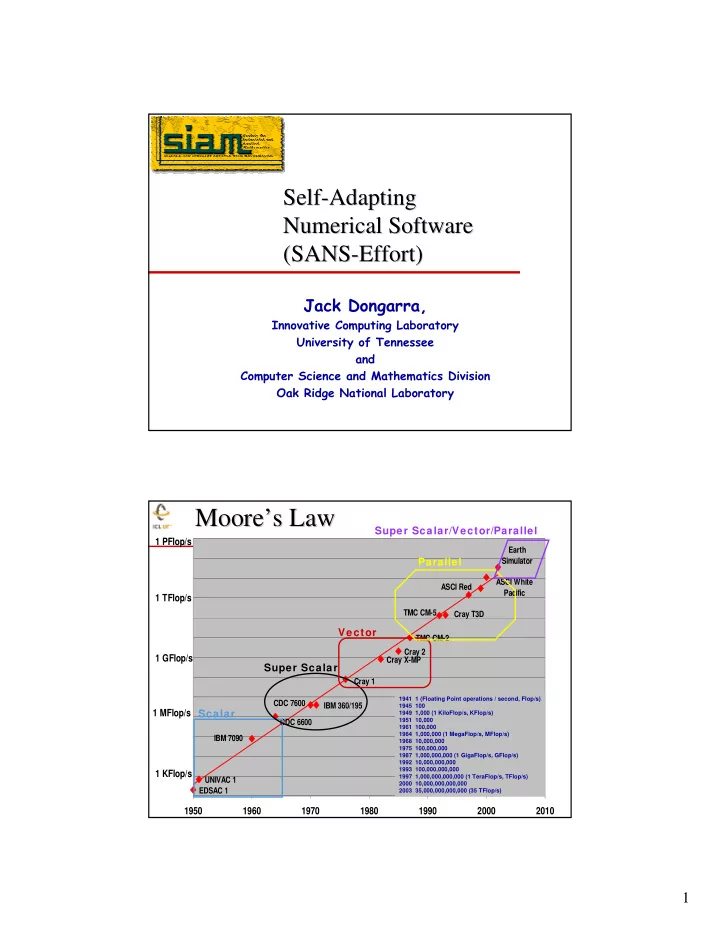
Self- -Adapting Adapting Self Numerical Software Numerical Software (SANS- -Effort) Effort) (SANS Jack Dongarra, Innovative Computing Laboratory University of Tennessee and Computer Science and Mathematics Division Oak Ridge National Laboratory Moore’ ’s Law s Law Moore Super Scalar/Vector/Parallel 1 PFlop/s Earth Parallel Simulator ASCI White ASCI Red Pacific 1 TFlop/s TMC CM-5 Cray T3D Vector TMC CM-2 Cray 2 1 GFlop/s Cray X-MP Super Scalar Cray 1 1941 1 (Floating Point operations / second, Flop/s) CDC 7600 IBM 360/195 1945 100 1 MFlop/s Scalar 1949 1,000 (1 KiloFlop/s, KFlop/s) 1951 10,000 CDC 6600 1961 100,000 1964 1,000,000 (1 MegaFlop/s, MFlop/s) IBM 7090 1968 10,000,000 1975 100,000,000 1987 1,000,000,000 (1 GigaFlop/s, GFlop/s) 1992 10,000,000,000 1993 100,000,000,000 1 KFlop/s 1997 1,000,000,000,000 (1 TeraFlop/s, TFlop/s) UNIVAC 1 2000 10,000,000,000,000 EDSAC 1 2003 35,000,000,000,000 (35 TFlop/s) 1950 1960 1970 1980 1990 2000 2010 1
Linpack (100x100) Analysis Linpack (100x100) Analysis ♦ Compaq 386/SX20 SX with FPA - .16 Mflop/s ♦ Pentium IV – 2.8 GHz – 1.32 Gflop/s ♦ 12 years � we see a factor of ~ 8231 ♦ Moore’s Law says something about a factor of 2 every 18 months or a factor of 256 over 12 years ♦ Where is the missing factor of 32 … Complex set of interaction between Users’ applications � Clock speed increase = 128x Algorithm Programming language � External Bus Width & Caching – Compiler � 16 vs. 64 bits = 4x Machine instruction � Floating Point - Hardware Many layers of translation from � 4/8 bits multi vs. 64 bits (1 clock) = 8x the application to the hardware � Compiler Technology = 2x Changing with each generation ♦ However the theoretical peak for that Pentium 4 is 5.6 Gflop/s and here we are getting 1.32 Gflop/s � Still a factor of 4.25 off of peak Where Does the Performance Go? or Where Does the Performance Go? or Why Should I Care About the Memory Hierarchy? Why Should I Care About the Memory Hierarchy? Processor-DRAM Memory Gap (latency) µProc 60%/yr. 1000000 (2X/1.5yr) “Moore’s Law” CPU Performance 10000 Processor-Memory Performance Gap: 100 (grows 50% / year) DRAM DRAM 9%/yr. 1 (2X/10 yrs) 0 2 4 6 8 0 2 4 6 8 0 2 4 8 8 8 8 8 9 9 9 9 9 0 0 0 9 9 9 9 9 9 9 9 9 9 0 0 0 1 1 1 1 1 1 1 1 1 1 2 2 2 Year 2
The Memory Hierarchy The Memory Hierarchy ♦ By taking advantage of the principle of locality: � Present the user with as much memory as is available in the cheapest technology. � Provide access at the speed offered by the fastest technology. Registers 1cy 3-10 words/cycle compiler managed CPU Chip 1-3cy 1-2 words/cycle hardware managed Level 1 Cache 5-10cy 1 word/cycle hardware managed Level 2 Cache Chips 30-100cy 0.5 words/cycle OS managed DRAM 10 6 -10 7 cy 0.01 words/cycle OS managed Mech Disk Tape Motivation Self Adapting Motivation Self Adapting Numerical Software (SANS) Effort Numerical Software (SANS) Effort ♦ Optimizing software to exploit the features of a given system has historically been an exercise in hand customization. � Time consuming and tedious � Hard to predict performance from source code � Must be redone for every architecture and compiler � Software technology often lags architecture � Best algorithm may depend on input, so some tuning may be needed at run-time. ♦ There is a need for quick/dynamic deployment of optimized routines . 3
What is Self Adapting Self Adapting What is Performance Tuning of Software? Performance Tuning of Software? ♦ Two steps: 1.Identify and generate a space of algorithm/software, with various based on the architectural features � Instruction mixes and orders � Memory Access Patterns � Data structures � Mathematical Formulations 2.Generate different versions and search for the fastest one, by running them ♦ When do we search? � Once per kernel and architecture � At compile time � At run time � All of the above ♦ Many examples � PHiPAC, ATLAS, Sparsity, FFTW, Spiral,… Vendor BLAS 3500.0 Software Generation Software Generation ATLAS BLAS 3000.0 F77 BLAS 2500.0 Strategy - - ATLAS BLAS Strategy ATLAS BLAS MFLOP/S 2000.0 1500.0 ♦ Parameter study of the hw 1000.0 ♦ Generate multiple versions 500.0 of code, w/difference 0.0 3 0 0 3 5 2 0 0 0 0 0 0 3 1 6 0 z 2 0 7 0 values of key performance 6 5 5 - 1 1 1 2 H E 2 2 0 - 6 - 6 5 / - - - M S - - 2 n 5 v 3 4 2 3 8 0 2 - o v e 7 0 r r 3 S 2 3 c h l e 6 e e 3 w / p p r t C 0 / C w w 9 i i a A C E 0 P o o z 0 0 p E D 0 P P P I I H 0 0 S D 9 I - 0 0 parameters M D P M M M P G 0 2 a 1 1 t r A H B B B e l 3 R R l I I I t 5 I I U n 2 . G G n I u 4 S S - S P l e n t ♦ Run and measure the Architectures ♦ Takes ~ 20 minutes to run, I performance for various generates Level 1,2, & 3 BLAS versions ♦ “New” model of high ♦ Pick best and generate performance programming library where critical code is machine generated using parameter ♦ Level 1 cache multiply optimization. optimizes for: ♦ Designed for modern � TLB access architectures � L1 cache reuse � Need reasonable C compiler � FP unit usage ♦ Today ATLAS in used within � Memory fetch various ASCI and SciDAC � Register reuse activities and by Matlab, � Loop overhead minimization Mathematica, Octave, Maple, Similar to FFTW and Johnsson, ♦ Debian, Scyld Beowulf, SuSE,… UH See: http://icl.cs.utk.edu/atlas/ joint with Clint Whaley & Antoine Petitet 4
ATLAS 3.6 (new release) ATLAS 3.6 (new release) ATLAS 3.6 AMD Opteron 1.6 GHz 3000 2500 2000 MFlop/s DGEMM 1500 DGETRF DPOTRF 1000 ATLAS 3.6 Intel Itanium-2 900 MHz 500 3500 DGEMM 0 3000 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 3 5 7 9 1 3 5 7 9 1 1 1 1 1 DGETRF 2500 Order Mflop/s 2000 1500 1000 500 http://www.netlib.org/atlas/ 0 100 200 300 400 500 600 700 800 900 1000 Order Self Adapting Numerical Software - - Self Adapting Numerical Software SANS Effort SANS Effort ♦ Provide software technology to aid in high performance on commodity processors, clusters, and grids. ♦ Pre-run time (library building stage) and run time optimization. ♦ Integrated performance modeling and analysis ♦ Automatic algorithm selection – polyalgorithmic functions ♦ Automated installation process ♦ Can be expanded to areas such as communication software and selection of numerical algorithms Different Best Algorithms, Algorithm, TUNING Segment Sizes Segment Size SYSTEM 5
Self Adapting for Message Passing Self Adapting for Message Passing ♦ Communication libraries � Optimize for the specifics of one’s configuration. � A specific MPI collective communication algorithm implementation may not give best results on all platforms. � Choose collective communication parameters that give best results for the system when the system is assembled. Root Sequential Binary Binomial Ring ♦ Algorithm layout and implementation � Look at the different ways to express implementation Different Best TUNING Algorithms, Algorithm, SYSTEM Size msgs Block msgs Self Adaptive Software Self Adaptive Software ♦ Software can adapt its workings to the environment in (at least) 3 ways � Kernels, optimized for platform (Atlas, Sparsity): static determination � Scheduling, taking network conditions into account (LFC): dynamic, but data- independent � Algorithm choice (Salsa): dynamic, strongly dependent on user data. 6
Data Layout Critical for Data Layout Critical for Performance Performance Number of processors Aspect ratio of processes Block size m mb n nb Needs An “Expert” To Do The Tuning LFC Performance Results LFC Performance Results Using up to 64 of Time to solution of Ax=b (n=60k) AMD 1.4 GHz 25000 processors at Ohio Naive 20000 Supercomputer LFC Center ) s 15000 d n o c I ncreasing e (s e im margin 10000 T of potential user error 5000 0 32 34 36 39 42 45 47 49 51 54 56 58 62 64 Number of processors 7
LFC: LAPACK For Clusters LFC: LAPACK For Clusters Want to relieve the user of some of the ♦ tasks via Cluster Middleware Make decisions on the number of User ♦ processors to use based on the user’s problem and the state of the system problem � Optimize for the best time to solution Library � Distribute the data on the processors and collections of results Middleware � Start the SPMD library routine on all the platforms Users, etc. e.g. 100 Mbit Resources ~ Myrinet Switch, ~ Gbit Switch, (fully connected) (fully connected) software hardware Joint with Piotr Ł uszczek & Kenny Roche http://icl.cs.utk.edu/lfc/ SALSA: Self-Adaptive Linear Solver Architecture Run-time adaptation to user data for linear system solving Choice between direct/iterative ♦ solver � Space and runtime considerations � Numerical properties of system Choice of preconditioner, scaling, ♦ ordering, decomposition User steering of decision process ♦ Insertion of performance data in ♦ database Metadata on both numerical data ♦ and algorithms Heuristics-driven automated ♦ analysis Self-adaptivity: tuning of ♦ heuristics over time through Joint work with experience gained from production runs Victor Eijkhout, Bill Gropp, & David Keyes 8
Recommend
























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.