
MHC-Peptide Interaction Studies using Bioinformatics tools - PowerPoint PPT Presentation
MHC-Peptide Interaction Studies using Bioinformatics tools Presented by Kunde Ramamoorthy Govindarajan Overview Introduction to Major histocompatibility complex What is MHC MHC gene organization MHC classification Structure,
MHC-Peptide Interaction Studies using Bioinformatics tools Presented by Kunde Ramamoorthy Govindarajan
Overview Introduction to Major histocompatibility complex � What is MHC � MHC gene organization � MHC classification � Structure, Function and antigen processing. Development of MHC-Peptide interaction Database(MPID) � Existing Databases � Objectives � Database Design � Database Access Conclusion and Future work
Major Histocompatibility complex � MHC is a genetic complex with multiple loci encoding two major MHC proper (proteins with the potential of presenting peptides to the TCRs.) class I, class II and a non-MHC genes with immune functions (class III). � Highly polymorphic cell surface molecules that present peptide ligands to cell of the T-cell compartment of the immune system.
MHC genes � Human MHC is a cluster of genes on short arm of chromosome 6. � MHC is highly polymorphic. � Class I: HLA-A, B and C α - chains. � Class II: DP, DQ and DR arranged in pairs encoding α and β chains.
MHC gene Organization Human Mouse
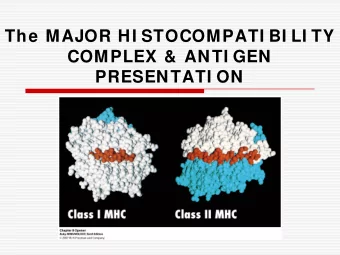
MHC Structure � The 3-D structure of MHC class I and class II have been established using X-ray crystallography. � Class I and class II MHC molecules have less similarity in protein sequences, but are very similar in function. � The physical difference between the two are small and are essential for peptide binding.
Class I MHC Structure and Function � Ternary complexes- α - chain, β -2 microglobulin and antigenic peptide. � Consists three extra cellular domains ( α 1 , α 2 & α 3 ) a transmembrane segment and a cytoplasmic domain. � α 1 and α 2 forms peptide binding groove. � Binding groove contains long α -helix and four β -strands.
Class I MHC Structure and Function � α -chain is highly polymorphic. � Cleft is closed at the ends,limiting the size of the peptide. � α chain folds to form a cleft with α - helical sides and β - pleated sheet floor to hold 8-10 a.a peptides .
Class I Antigen Processing Source: http://www.med.sc.edu:85/bowers/mhc.htm
Class II MHC Structure and Function � Heterodimer of α and β chains. � Consists of four extra cellular domains ( α 1 , α 2 , β 1 & β 2 ). � α 1 and β 1 forms peptide binding groove. � Binding groove Contains long α -helix and four β -strands. � Cleft is open at the ends, allowing longer peptides to bind (13-18 a.a).
MHC class II Structure and Function
Class II Antigen processing Source: http://www.med.sc.edu:85/bowers/mhc.htm
Importance of MHC � Recognition of a peptide derived from a disease associated protein (e.g) viral or a bacteria, in the presence of a co-stimulatory signal leads to T-cell activation and triggers a T-cell mediated Immune response. � Therefore, which peptide fragments binds to MHC molecules for recognition by T-cell is crucial for the development of peptide based vaccines.
Current scenario in MHC-Peptide binding prediction � So far MHC-Peptide binding prediction has focused on sequence-based methods. � However, the methods are not sensitive. A recent review says “Poor correspondence between predicted and experimental binding of peptides to class I MHC molecules”. (Anderson et al, 2000 Tissue antigens. 55, 519- 31).
Current Scenario (Contd…) � Another approach is based on structural information obtained from X-ray crystallography. ( Altuvia et al., 1997; Schueler-Furman et al., 2000 ). Recent review says “structure based methods have not been extensively used for the prediction of CTL- epitopes” (Markus Schirle et al., 2001 Journal of Immunological Methods 257, 1-16). Advantages of structural approach � Structure is conserved longer time in evolution when compared to sequences. � Structure determinants influence the binding of specific amino acid sequences for particular MHC- allele.
Existing Databases for MHC � IMGT/HLA - Sequences for all HLA-alleles. (http://www.ebi.ac.uk/imgt/hla/). � SYFPEITHI - Sequence database for MHC binding Peptides. (http://syfpeithi.bmiheidelberg.com/) � MHCPEP - Peptide sequences with experimental binding data. (http://wehih.wehi.edu.au/mhcpep/) � FIMM - Referenced data-peptides,MHC and relevant disease association. (http://sdmc.krdl.org.sg:8080/fimm/)
Project Objectives � To collect and curate the available MHC-Peptide complex structure data from PDB. � Calculate properties defining MHC-Peptide complex interaction. � Develop a comprehensive database spanning sequence-structure-function realms. � Analyze data and quantify MHC-Peptide complex interaction. � Develop algorithm for MHC-Peptide binding prediction.
Project Objectives � To collect and curate the available MHC-Peptide complex structure data from Protein Data Bank (PDB). � Calculate properties defining MHC-Peptide complex interaction. � Develop a comprehensive database spanning sequence-structure-function realms � Analyze data and quantify MHC-Peptide complex interaction. � Develop algorithm for MHC-Peptide binding prediction.
Data clustering and Redundancy � Structural Data derived from Protein DataBank(PDB). � Data clustered based on MHC class, By Allele and Peptide length.
Redundancy (contd…) Non-Redundancy: � Best structure from each group on the basis of highest resolution and completeness of structural information. � If the PDB entries contains multiple protein chains, the first complex is stored in MPID. � Non-classical MHC-Peptide structure and complexes of non-standard amino acids are not included.
Project Objectives � To collect and curate the available MHC-Peptide complex structure data from PDB. � Calculate properties defining MHC-Peptide complex interaction. � Develop a comprehensive database spanning sequence-structure-function realms � Analyze data and quantify MHC-Peptide complex interaction. � Develop algorithm for MHC-Peptide binding prediction.
Interaction parameters Interface area between MHC and Peptide � Defined as the change in their solvent accessible surface area ( ∆ ASA) when going from a monomeric to a dimeric MHC-Peptide complexes state. � The ∆ ASA of the complexes and the individual polypeptides were calculated using the program NACCESS based on Lee & Richard(1971) algorithm. ∆ A S A = A S A o f M H C + A S A o f P e p tid e -A S A o f M H C p c o m p le x 2
Parameters(contd…) Gap Volume � The gap volume between the MHC & peptide in each complex was calculated using the Program SURFNET (Laskowski 1995). Gap Index � Gap index (Å ) is defined as the ratio of gap volume between the MHC and the peptide(Å 3 ) to the interface area(Å 2 ) per MHC peptide. 3 ) Gap Index = Gap Volume between MHC & Peptide(Å 2 ) Interface area (Å
Parameters(contd…) Hydrogen bonds � The number of intermolecular hydrogen bonds between the peptide and the MHC was calculated using HBPLUS( McDonald and Thornton 1994) in which hydrogen bonds are defined according to standard geometric criteria.
Schematic diagram of MHC Peptide Interactions Ligplot � Schematic diagram MHC-Peptide interactions based on the plotting diagram, LIGPLOT are also available in MPID in pdf format.
Schematic diagram (contd…) Sequence Conservation (by peptide length) � Sequence logo is a graphical display of a multiple alignment consisting of color coded stacks of letters representing amino acids at successive positions. The height represents the frequency of the amino acids. Conserved residues in 12-mer peptides.
Project Objectives � To collect and curate the available MHC-Peptide complex structure data from PDB. � Calculate properties defining MHC-Peptide complex interaction. � Develop a comprehensive database spanning sequence-structure-function realms. � Analyze data and quantify MHC-Peptide complex interaction. � Develop algorithm for MHC-Peptide binding prediction.
Database design � MPID is a relational database(MySQL v.3.22.21) developed and hosted on the UNIX platform (IRIX 6.5) running Apache 1.3.12. � MPID is a semi-automatically derived. The overall dimensional model of MPID data depicts � the flow between the different dimensions along with internal links and links to relevant external data sources. Currently, there are five dimensions: MHC-Peptide � complexes, MHC, Peptides, Interactions and References.
MPID Links � The sequence data derived from PDB is hyperlinked to IMGT/HLA (for MHC) and to the SYFPEITHI (for the peptide) databases. � The publication reference for each MPID structure is provided by a link to the PubMed database. � The related sequences and structures for the relevant protein chains of each MPID entry can be accessed via the NCBI structure database. � Experimental binding strengths along with the corresponding references have been provided, wherever available.
Recommend






















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.