
Long-term Recurrent Convolutional Networks for Visual Recognition - PowerPoint PPT Presentation
Long-term Recurrent Convolutional Networks for Visual Recognition and Description Donahue et al. Berkan Demirel Overview of LRCN LRCN is a class of models that is both spatially and temporally deep. It has the fmexibility to be applied
Long-term Recurrent Convolutional Networks for Visual Recognition and Description Donahue et al. Berkan Demirel
Overview of LRCN LRCN is a class of models that is both spatially and temporally deep. It has the fmexibility to be applied to a variety of vision tasks involving sequential inputs and outputs. Image credit: main paper
Convolutional Neural Networks Krizhevsky, Alex, Ilya Sutskever, and Geofgrey E. Hinton. "Imagenet classifjcation with deep convolutional neural networks." Advances in neural information processing systems. 2012.
Limitation 1 Fixed-size, static input - 224x224x3
Limitation 2 Output is a single choice from list of options
Background: Sequence Learning Jefg Donahue, CVPR Cafge Tutorial, June 6, 2015
Background: Sequence Learning Jefg Donahue, CVPR Cafge Tutorial, June 6, 2015
Background: Sequence Learning Jefg Donahue, CVPR Cafge Tutorial, June 6, 2015
Background: Sequence Learning Jefg Donahue, CVPR Cafge Tutorial, June 6, 2015
Background: Sequence Learning Jefg Donahue, CVPR Cafge Tutorial, June 6, 2015
Background: Sequence Learning Jefg Donahue, CVPR Cafge Tutorial, June 6, 2015
Contributions Mapping variable-length inputs (e.g., video frames) to variable length outputs (e.g., natural language text). LRCN is directly connected to modern visual convnet models. It is suitable for large-scale visual learning which is end-to- end trainable.
Sequential inputs /outputs Image credit: main paper
LRCN Model LRCN model works by passing each visual input (an image in isolation, or a frame from a video) through a feature transformation parametrized by V to produce a fixed-length vector representation. In its most general form, a sequence model, parametrized by W, maps an input x t and a previous timestep hidden state h t-1 to an output z t and update hidden state h t . The final step in predicting a distribution P(y t ) at timestep t is to take a softmax over the outputs z t of the sequential mode.
LRCN Model - Activity Recognition Sequential input, fixed outputs: <x 1 ,x 2 ,x 3 ,... x T > → y With sequential inputs and scalar outputs, we take a late fusion approach to merging the per-timestep predictions into a single prediction for the full sequence. Image credit: main paper
LRCN Model – Image Description Fixed input, sequential outputs: x → <y 1 ,y 2 ,y 3 ,... y T > With fixed-size inputs and sequential outputs, we simply duplicate the input x at all T timesteps. Image credit: main paper
LRCN Model – Video Description Fixed input, sequential outputs: <x 1 ,x 2 ,x 3 ,... x T > → <y 1 ,y 2 ,y 3 ,... y T' > For a sequence-to-sequence problem with (in general) different input and output lengths, take an “encoder-decoder” approach. In this approach, one sequence model, the encoder, is used to map the input sequence to a fixed length vector, then another sequence model, the decoder, is used to unroll this vector to sequential outputs of arbitrary length. Image credit: main paper
LRCN Model Under the proposed system, the weights (V;W) of the model’s visual and sequential components can be learned jointly by maximizing the likelihood of the ground truth outputs.
Activity Recognition • T individual frames are input to T convolutional networks which are then connected to a single layer LSTM with 256 hidden units. • The CNN base of the LRCN is a hybrid of the Caffe reference model, a minor variant of AlexNet, and the network used by Zeiler & Fergus which is pre-trained on the 1.2M image ILSVRC-2012 classification training subset of the ImageNet dataset.
Activity Recognition • Two variants of the LRCN architecture are used: one in which the LSTM is placed after the first fully connected layer of the CNN (LRCN-fc6) and another in which the LSTM is placed after the second fully connected layer of the CNN (LRCN-fc7). • Networks are trained with video clips of 16 frames. The LRCN predicts the video class at each time step and we average these predictions for final classification. • Consider both RGB and flow inputs.
Activity recognition CNN CNN CNN CNN LSTM LSTM LSTM LSTM jumping jumping running sitting Average jumping
Evaluation Architecture is evaluated on the UCF-101 dataset which consists of over 12,000 videos categorized into 101 human action classes.
Image Description • In contrast to activity recognition, the static image description task only requires a single convolutional network. • At each timestep, both the image features and the previous word are provided as inputs to the sequential model, in this case a stack of LSTMs (each with 1000 hidden units), • This is used to learn the dynamics of the time-varying output sequence, natural language.
Image Description CNN LSTM LSTM LSTM LSTM LSTM <BOS> jumpi <EOS> a dog is ng
Image Description CNN LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM a jumping dog <EOS> <BOS> is
Image Description Two layered factor CNN LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM a jumping dog <EOS> <BOS> is
Evaluation – Image Retrieval Model is trained on the combined training sets of the Flickr30k (28,000 training images) and COCO2014 dataset (80,000 training images). Results are reported on Flickr30k ( 1000 images each for test and validation).
Evaluation – Image Retrieval Image retrieval results for variants of the LRCN architectures.
Evaluation – Sentence Generation BLEU (bilingual evaluation understudy ) metric is used. Additionally, Authors report results on the new COCO2014 dataset which has 80,000 training images, and 40,000 validation images. Authors isolate 5,000 images from the validation set for testing purposes and the results are reported
Evaluation – Human Evaluation Rankings Human evaluator rankings from 1-6(low is good) averaged for each method and criterion.
Image Description Results
Image Description Results
Image Description Results
Video Description • Due to limitations of available video description datasets authors take a different path. • They rely on more "traditional" activity and video recognition processing for the input and use LSTMs for generating a sentence. • They assume they have predictions of objects, subjects, and verbs present in the video from a CRF based on the full video input.
Video Description Pre-trained detector predictions LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM LSTM jumping a dog <EOS> <BOS> is
LSTM Encoder & Decoder Figure credit: supplementary material
LSTM Decoder with CRF Max Figure credit: supplementary material
LSTM Decoder with CRF Prob. Figure credit: supplementary material
Evaluation – Video Description TACoS multilevel dataset, which has 44,762 video/sentence pairs (about 40,000 for training/validation).
Video Description Figure credit: supplementary material
Video Description Figure credit: supplementary material
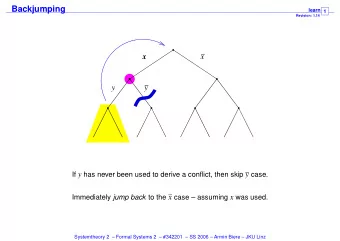
Conclusion LRCN is a flexible framework for vision problems involving sequences Able to handle: ✔ Sequences in the input (video) ✔ Sequences in the output (natural language description)
Future Directions Image credit: Hu, Ronghang, Marcus Rohrbach, and Trevor Darrell. "Segmentation from Natural Language Expressions." arXiv preprint arXiv:1603.06180 (2016).
Thank You!
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.