
Inverted Indexes IR, session 5 CS6200: Information Retrieval - PowerPoint PPT Presentation
Inverted Indexes IR, session 5 CS6200: Information Retrieval Slides by: Jesse Anderton Scaling up A term incidence matrix with V Corpus Terms Docs Entries terms and D documents has O(V x D) entries. Shakespeares ~1.1 ~31,000 37
Inverted Indexes IR, session 5 CS6200: Information Retrieval Slides by: Jesse Anderton
Scaling up • A term incidence matrix with V Corpus Terms Docs Entries terms and D documents has O(V x D) entries. Shakespeare’s ~1.1 ~31,000 37 Plays million • Shakespeare used around 31,000 distinct words across 37 plays, for about 1.1M entries. English ~1.7 ~4.5 ~7.65 • As of 2014, a collection of Wikipedia Wikipedia million million trillion pages comprises about 4.5M pages and roughly 1.7M distinct words. Assuming just one bit per matrix >2 >1.7 >3.4x10 15 English Web million billion entry, this would consume about 890GB of memory.
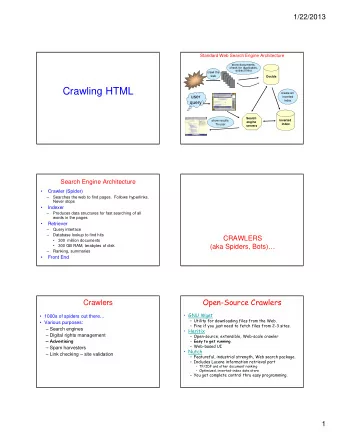
Inverted Indexes • Two insights allow us to reduce this to a manageable size: 1. The matrix is sparse – any document uses a tiny fraction of the vocabulary. 2. A query only uses a handful of words, so we don’t need the rest. • We use an inverted index instead of using a term incidence matrix directly. • An inverted index is a map from a term to a posting list of documents which use that term.
Search Algorithm • Consider queries of the form: t 1 AND t 2 AND … AND t n • In this simplified case, we need only take the intersections of the term posting lists. • This algorithm, inspired by merge sort, relies on the posting lists being sorted by length. • We save time by processing the terms in order from least common to most common. (Why does this help?)
Example
Wrapping Up • All modern search engines rely on inverted indexes in some form. Many other data structures were considered, but none has matched its efficiency. • The entries in a production inverted index typically contain many more fields providing extra information about the documents. • The efficient construction and use of inverted indexes is a topic of its own, and will be covered in a later module. • Next, we’ll see a more nuanced way to find relevant documents.
Recommend




















More recommend
Explore More Topics
Stay informed with curated content and fresh updates.