
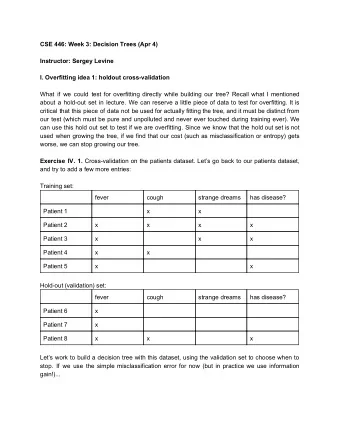
Introduction to Machine Learning Evaluation: Test Error Learning - PowerPoint PPT Presentation
Introduction to Machine Learning Evaluation: Test Error Learning goals training error 0.06 test error Underfitting, Overfitting, High Bias, Low Bias, Understand the definition of test 0.04 Low Variance High Variance MSE error 0.02
Introduction to Machine Learning Evaluation: Test Error Learning goals training error 0.06 test error Underfitting, Overfitting, High Bias, Low Bias, Understand the definition of test 0.04 Low Variance High Variance MSE error 0.02 Understand how overfitting can 0.00 2 4 6 8 10 be seen in the test error degree of polynomial
TEST ERROR Learner Training Dataset Dataset D Model Fit Split into Tain and Test Predict Test Dataset Test Error � c Introduction to Machine Learning – 1 / 8
TEST ERROR AND HOLD-OUT SPLITTING Split data into 2 parts, e.g., 2/3 for training, 1/3 for testing Evaluate on data not used for model building Learner Training Dataset Dataset D Model Fit Split into Tain and Test Predict Test Dataset Test Error � c Introduction to Machine Learning – 2 / 8
TEST ERROR Let’s consider the following example: Sample data from sinusoidal function 0 . 5 + 0 . 4 · sin( 2 π x ) + ǫ 1.00 0.75 Train set Test set y 0.50 0.25 True function 0.00 0.00 0.25 0.50 0.75 1.00 x Try to approximate with a d th -degree polynomial: d f ( x | θ ) = θ 0 + θ 1 x + · · · + θ d x d = � θ j x j . j = 0 � c Introduction to Machine Learning – 3 / 8
TEST ERROR degree 1.00 1 3 0.75 9 0.50 y Train set Test set 0.25 0.00 True function 0.00 0.25 0.50 0.75 1.00 x d=1: MSE = 0.038: Clear underfitting d=3: MSE = 0.002: Pretty OK d=9: MSE = 0.046: Clear overfitting � c Introduction to Machine Learning – 4 / 8
TEST ERROR Plot evaluation measure for all polynomial degrees: training error test error 0.06 Underfitting, Overfitting, High Bias, Low Bias, 0.04 Low Variance High Variance MSE 0.02 0.00 2 4 6 8 10 degree of polynomial Increase model complexity (tendentially) decrease in training error U-shape in test error (first underfit, then overfit, sweet-spot in the middle) � c Introduction to Machine Learning – 5 / 8
TEST ERROR PROBLEMS Test data has to be i.i.d. compared to training data. Bias-variance of hold-out: The smaller the training set, the worse the model → biased estimate. The smaller the test set, the higher the variance of the estimate. If the size of our initial, complete data set D is limited, single train-test splits can be problematic. � c Introduction to Machine Learning – 6 / 8
TEST ERROR PROBLEMS A major point of confusion: In ML we are in a weird situation. We are usually given one data set. At the end of our model selection and evaluation process we will likely fit one model on exactly that complete data set. As training error evaluation does not work, we have nothing left to evaluate exactly that model. Hold-out splitting (and resampling) are tools to estimate the future performance. All of the models produced during that phase of evaluation are intermediate results. � c Introduction to Machine Learning – 7 / 8
Recommend























More recommend
Explore More Topics
Stay informed with curated content and fresh updates.